
집 >백엔드 개발 >XML/RSS 튜토리얼 >안드로이드의 XML 파싱 기술 구현에 대한 자세한 설명(사진)
안드로이드의 XML 파싱 기술 구현에 대한 자세한 설명(사진)

- 黄舟원래의
- 2017-03-09 17:07:061618검색
이 글에서는 Android 플랫폼에서 XML을 구문 분석하는 세 가지 방법을 소개합니다.
XML은 다양한 개발에 널리 사용되며 Android도 예외는 아닙니다. 데이터를 운반하는 중요한 역할로서 XML을 읽고 쓰는 방법은 Android 개발에 있어 중요한 기술이 되었습니다.
Android에서 흔히 사용되는 XML 파서로는 DOM 파서, SAX 파서, PULL 파서가 있는데, 아래에서 하나씩 자세히 소개해드리겠습니다.
첫 번째 방법: DOM 파서:
DOM은 개발자는 DOM API를 사용하여 XML 트리를 탐색하고 필요한 데이터를 검색할 수 있습니다. 이 구조를 분석하려면 일반적으로 노드 정보를 검색하고 업데이트하기 전에 전체 문서를 로드하고 트리 구조를 구성해야 합니다. Android는 DOM 구문 분석을 완벽하게 지원합니다. DOM의 개체를 사용하면 XML 문서를 읽고, 검색하고, 수정하고, 추가하고 삭제할 수 있습니다.
DOM 작동 방식: DOM을 사용하여 XML 파일을 작동하는 경우 먼저 파일을 구문 분석하고 파일을 독립적인 요소, 속성 및 주석으로 나누어야 합니다. 등을 사용한 다음 노드 트리 형태로 메모리에 XML 파일을 표시합니다. 노드 트리를 통해 문서의 내용에 액세스하고 필요에 따라 문서를 수정할 수 있습니다. 이것이 DOM이 작동하는 방식입니다.
DOM 구현은 먼저 XML 문서 구문 분석을 위한 인터페이스 세트를 정의하고, 파서는 전체 문서를 읽은 다음 메모리 상주 트리 구조를 구성합니다. 그런 다음 코드는 DOM 인터페이스를 사용하여 전체 트리 구조를 조작할 수 있습니다.
DOM은 메모리에 트리 구조로 저장되므로 검색, 업데이트 효율성이 높아집니다. 그러나 특히 큰 문서의 경우 전체 문서를 구문 분석하고 로드하는 데 리소스가 많이 소모됩니다. 물론, XML 파일의 내용이 상대적으로 작다면 DOM을 사용하는 것이 가능합니다.
일반적으로 사용되는 DoM 인터페이스 및 클래스:
문서: 이 인터페이스는 DOM의 일련의 분석 및 생성을 정의합니다. 문서 트리의 루트이자 DOM 운영의 기초가 되는 문서 메서드입니다.
요소: 이 인터페이스는 Node 인터페이스를 상속하며 XML 요소 이름과 속성을 얻고 수정하는 메서드를 제공합니다.
노드: 이 인터페이스는 노드 및 하위 노드 값을 처리하고 얻는 방법을 제공합니다.
NodeList: 노드 수와 현재 노드를 가져오는 메서드를 제공합니다. 이를 통해 개별 노드에 반복적으로 액세스할 수 있습니다.
DOMParser: 이 클래스는 XML 파일을 직접 구문 분석할 수 있는 Apache Xerces의 DOM 구문 분석기 클래스입니다.
DOM 파싱 과정은 다음과 같습니다.

두 번째 방법: SAX 파서:
SAX(Simple API for XML) 파서는 이벤트 기반입니다. 파서의 스트리밍 파싱 방식은 일시정지나 되감기 없이 파일의 처음부터 문서의 끝까지 순차적으로 파싱하는 것이다. 그 핵심은 주로 이벤트 소스와 이벤트 프로세서를 중심으로 작동하는 이벤트 처리 모델입니다. 이벤트 소스가 이벤트를 생성하면 해당 이벤트 프로세서의 처리 메서드를 호출하여 이벤트를 처리할 수 있습니다. 이벤트 소스가 이벤트 핸들러에서 특정 메서드를 호출할 때 해당 이벤트의 상태 정보도 이벤트 핸들러에 전달해야 이벤트 핸들러가 제공된 이벤트 정보를 기반으로 자체 동작을 결정할 수 있습니다.
SAX 파서의 장점은 파싱 속도가 빠르고 메모리를 덜 차지한다는 점이다. Android 모바일 장치에서 사용하기에 적합합니다.
SAX의 작동 원리: SAX의 작동 원리는 단순히 문서(문서)의 시작과 끝을 스캔할 때 순차적으로 스캔하는 것입니다. , 요소( 요소가 시작하고 끝날 때, 문서가 끝날 때 등을 이벤트 처리 함수에 알리고 이벤트 처리 함수는 해당 작업을 수행한 후 문서가 끝날 때까지 동일한 스캔을 계속합니다.
SAX 인터페이스에서 이벤트 소스는 파서를 통해 XML 문서를 구문 분석하는 org.xml.sax 패키지의 XMLReader입니다( ) 메서드를 사용하여 이벤트를 생성합니다. 이벤트 핸들러는 org.xml.sax 패키지에 있는 ContentHander, DTDHander, ErrorHandler 및 EntityResolver의 네 가지 인터페이스입니다. XMLReader는 해당 이벤트 핸들러 등록 메소드 setXXXX()를 통해 ContentHander, DTDHander, ErrorHandler 및 EntityResolver 4개 인터페이스와의 연결을 완료합니다.
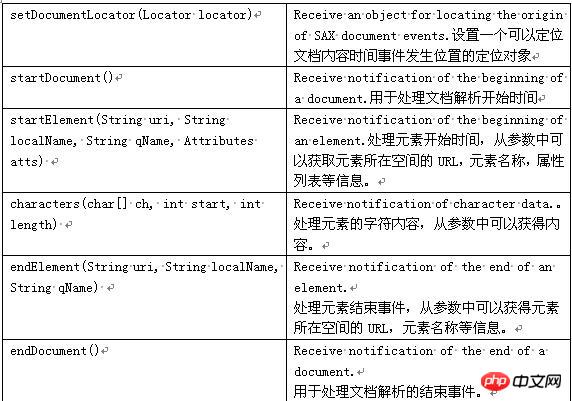
일반적으로 사용되는 SAX 인터페이스 및 클래스: 속성: 사용된 Get 속성의 수, 이름 및 값. ContentHandler: 문서 자체와 관련된 이벤트(예: 열기 및 닫기 태그)를 정의합니다. 대부분의 애플리케이션은 이러한 이벤트에 등록합니다. DTDHandler: DTD와 관련된 이벤트를 정의합니다. DTD를 완전히 보고할 만큼 충분한 이벤트를 정의하지 않습니다. DTD 구문 분석이 필요한 경우 선택적 DeclHandler를 사용하십시오. DeclHandler는 SAX의 확장입니다. 모든 파서가 이를 지원하는 것은 아닙니다. EntityResolver: 엔터티 로드와 관련된 이벤트를 정의합니다. 소수의 애플리케이션만이 이러한 이벤트에 등록됩니다. ErrorHandler: 오류 이벤트를 정의합니다. 많은 응용 프로그램은 이러한 이벤트에 등록하여 고유한 방식으로 오류를 보고합니다. DefaultHandler: 이러한 인터페이스의 기본 구현을 제공합니다. 대부분의 경우 애플리케이션이 인터페이스를 직접 구현하는 것보다 DefaultHandler를 확장하고 관련 메서드를 재정의하는 것이 더 쉽습니다. 자세한 내용은 아래 표를 참조하세요. 보시다시피 xml을 구문 분석하려면 XmlReader와 DefaultHandler가 필요합니다. SAX 파싱 과정은 다음과 같습니다. 

세 번째 방법: PULL 파서:
Android에서는 제공하지 않습니다. Java StAX API 지원. 그러나 Android에는 StAX와 유사하게 작동하는 풀 파서가 함께 제공됩니다. 이를 통해 SAX 파서가 자동으로 이벤트를 핸들러에 푸시하는 것과 달리 사용자의 애플리케이션 코드가 파서에서 이벤트를 가져올 수 있습니다.
PULL 파서는 SAX와 유사하게 작동하며 둘 다 이벤트 기반입니다. 차이점은 PULL 구문 분석 프로세스 중에 숫자가 반환되며, 프로세서가 이벤트를 트리거하고 코드를 실행하는 SAX와 달리 생성된 이벤트를 직접 얻은 다음 해당 작업을 수행해야 한다는 것입니다.
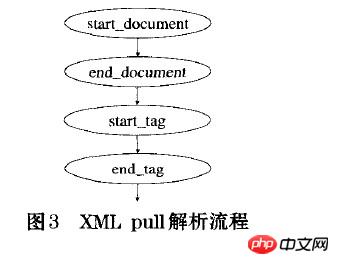
다음은 XML을 PULL 구문 분석하는 과정입니다.
xml 선언을 읽으면 START_DOCUMENT가 반환됩니다.
xml의 끝을 읽고 END_DOCUMENT를 반환합니다.
xml의 시작 태그를 읽고 START_TAG를 반환
xml의 끝 태그를 읽고 END_TAG를 반환
xml의 텍스트를 읽고 TEXT를 반환
PULL 파서는 작고 가벼우며 파싱 속도가 빠르고 간단하고 사용하기 쉬우며 안드로이드 모바일에서 사용하기에 매우 적합합니다. Android 시스템은 내부적으로 구문 분석하고 있습니다. PULL 파서 는 다양한 XML에도 사용됩니다. Android는 개발자에게 Pull 구문 분석 기술을 사용할 것을 공식적으로 권장합니다. 풀 파싱(Pull Parsing) 기술은 타사에서 개발한 오픈소스 기술로, JavaSE 개발에도 적용할 수 있습니다.
PULL 작동 방식: XML pull은 시작 요소와 끝 요소를 제공합니다. 요소가 시작되면 파서를 호출할 수 있습니다. nextText는 XML 문서에서 모든 문자 데이터를 추출합니다. 문서 해석이 끝나면 EndDocument 이벤트가 자동으로 생성됩니다.
일반적으로 사용되는 XML 풀 인터페이스 및 클래스:
XmlPullParser: XML 풀 파서는 XMLPULL VlAP1 인터페이스에서 제공되는 정의 파싱 기능입니다.
XmlSerializer: XML 정보 세트의 순서를 정의하는 인터페이스입니다.
XmlPullParserFactory: 이 클래스는 XMPULL V1 API에서 XML Pull 파서를 생성하는 데 사용됩니다.
XmlPullParserException: 단일 XML 풀 파서 관련 오류가 발생합니다.
PULL의 파싱 과정은 다음과 같습니다.
[추가] 네 번째 방법: Android.util.Xml 클래스
in Android API에는 Android도 제공됩니다. 유틸리티 Xml 클래스는 XML 파일도 구문 분석할 수 있습니다. 사용 방법은 SAX와 유사합니다. XML 구문 분석을 처리하려면 핸들러도 작성해야 하지만 아래와 같이 SAX보다 사용이 더 간단합니다. >
안드로이드로. 유틸리티 XML은 XML 구문 분석을 구현합니다.MyHandler myHandler=new MyHandler0;
android. 유틸리티 Xm1. 구문 분석(ur1.openC0nnection().getlnputStream0, Xm1.Encoding.UTF-8, myHandler)
river.xml, assets 디렉토리 에 위치합니다. 은 다음과 같습니다.
<?xml version="1.0" encoding="utf-8"?> <rivers> <river name="灵渠" length="605"> <introduction>
링취 운하는 광시 장족 자치구 싱안 현에 위치하고 있으며 세계에서 가장 오래된 운하 중 하나이며 "세계 고대 수자원 보존 건축물의 진주"라는 명성을 가지고 있습니다. 고대에는 Lingqu가 Qin Zhuoqu, Lingqu, Douhe 및 Xing'an 운하로 알려졌습니다. 기원전 214년에 건설되어 항해가 가능해졌으며 2217년 전에도 여전히 작동하고 있습니다.
</
introduction
>
<
imageurl
>
http://www.php.cn/
</
imageurl
>
</
river
>
<
river
name
="胶莱运河"
length
="200"
>
<
introduction
>
胶莱运河南起黄海灵山海口,北抵渤海三山岛,流经现胶南、胶州、平度、高密、昌邑和莱州等,全长200公里,流域面积达5400平方公里,南北贯穿山东半岛,沟通黄渤两海。胶莱运河自平度姚家村东的分水岭南北分流。南流由麻湾口入胶州湾,为南胶莱河,长30公里。北流由海仓口入莱州湾,为北胶莱河,长100余公里。
</
introduction
>
<
imageurl
>
http://www.php.cn/
</
imageurl
>
</
river
>
<
river
name
="苏北灌溉总渠"
length
="168"
>
<
introduction
>
位于淮河下游江苏省北部,西起洪泽湖边的高良涧,流经洪泽,青浦、淮安,阜宁、射阳,滨海等六县(区),东至扁担港口入海的大型人工河道。全长168km。
</
introduction
>
<
imageurl
>
http://www.php.cn/
</
imageurl
>
</
river
>
</
rivers
>
采用DOM解析时具体处理步骤是:
1 首先利用DocumentBuilderFactory创建一个DocumentBuilderFactory实例
2 然后利用DocumentBuilderFactory创建DocumentBuilder
3 然后加载XML文档(Document),
4 然后获取文档的根结点(Element),
5 然后获取根结点中所有子节点的列表(NodeList),
6 然后使用再获取子节点列表中的需要读取的结点。
当然我们观察节点,我需要用一个River对象来保存数据,抽象出River类
public class River implements Serializable {
privatestaticfinallong serialVersionUID = 1L;
private String name;
public String getName() {
return name; }
public void setName(String name) {
this.name = name; }
public int getLength() {
return length; }
public void setLength(int length) {
this.length = length; }
public String getIntroduction() {
return introduction; }
public void setIntroduction(String introduction) {
this.introduction = introduction; }
public String getImageurl() {
return imageurl; }
public void setImageurl(String imageurl) {
this.imageurl = imageurl; }
private int length;
private String introduction;
private String imageurl; }下面我们就开始读取xml文档对象,并添加进List中:
代码如下: 我们这里是使用assets中的river.xml文件,那么就需要读取这个xml文件,返回输入流。 读取方法为:inputStream=this.context.getResources().getAssets().open(fileName); 参数是xml文件路径,当然默认的是assets目录为根目录。
然后可以用DocumentBuilder对象的parse方法解析输入流,并返回document对象,然后再遍历doument对象的节点属性。
//获取全部河流数据
/**
* 参数fileName:为xml文档路径
*/
public List<River> getRiversFromXml(String fileName){
List<River> rivers=new ArrayList<River>();
DocumentBuilderFactory factory=null;
DocumentBuilder builder=null;
Document document=null;
InputStream inputStream=null;
//首先找到xml文件
factory=DocumentBuilderFactory.newInstance();
try {
//找到xml,并加载文档
builder=factory.newDocumentBuilder();
inputStream=this.context.getResources().getAssets().open(fileName);
document=builder.parse(inputStream);
//找到根Element
Element root=document.getDocumentElement();
NodeList nodes=root.getElementsByTagName(RIVER);
//遍历根节点所有子节点,rivers 下所有river
River river=null;
for(int i=0;i<nodes.getLength();i++){
river=new River();
//获取river元素节点
Element riverElement=(Element)(nodes.item(i));
//获取river中name属性值
river.setName(riverElement.getAttribute(NAME));
river.setLength(Integer.parseInt(riverElement.getAttribute(LENGTH)));
//获取river下introduction标签
Element introduction=(Element)riverElement.getElementsByTagName(INTRODUCTION).item(0);
river.setIntroduction(introduction.getFirstChild().getNodeValue());
Element imageUrl=(Element)riverElement.getElementsByTagName(IMAGEURL).item(0);
river.setImageurl(imageUrl.getFirstChild().getNodeValue());
rivers.add(river);
}
}catch (IOException e){
e.printStackTrace();
} catch (SAXException e) {
e.printStackTrace();
}
catch (ParserConfigurationException e) {
e.printStackTrace();
}finally{
try {
inputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return rivers;
}
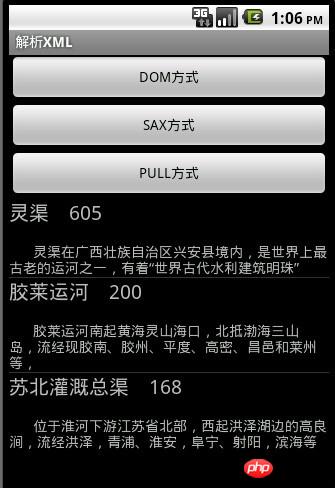
在这里添加到List中, 然后我们使用ListView将他们显示出来。如图所示:
采用SAX解析时具体处理步骤是:
1 创建SAXParserFactory对象
2 根据SAXParserFactory.newSAXParser()方法返回一个SAXParser解析器
3 根据SAXParser解析器获取事件源对象XMLReader
4 实例化一个DefaultHandler对象
5 连接事件源对象XMLReader到事件处理类DefaultHandler中
6 调用XMLReader的parse方法从输入源中获取到的xml数据
7 通过DefaultHandler返回我们需要的数据集合。
代码如下:
public List<River> parse(String xmlPath){
List<River> rivers=null;
SAXParserFactory factory=SAXParserFactory.newInstance();
try {
SAXParser parser=factory.newSAXParser();
//获取事件源
XMLReader xmlReader=parser.getXMLReader();
//设置处理器
RiverHandler handler=new RiverHandler();
xmlReader.setContentHandler(handler);
//解析xml文档
//xmlReader.parse(new InputSource(new URL(xmlPath).openStream()));
xmlReader.parse(new InputSource(this.context.getAssets().open(xmlPath)));
rivers=handler.getRivers();
} catch (ParserConfigurationException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (SAXException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return rivers;
}
重点在于DefaultHandler对象中对每一个元素节点,属性,文本内容,文档内容进行处理。
前面说过DefaultHandler是基于事件处理模型的,基本处理方式是:当SAX解析器导航到文档开始标签时回调startDocument方法,导航到文档结束标签时回调endDocument方法。当SAX解析器导航到元素开始标签时回调startElement方法,导航到其文本内容时回调characters方法,导航到标签结束时回调endElement方法。
根据以上的解释,我们可以得出以下处理xml文档逻辑:
1:当导航到文档开始标签时,在回调函数startDocument中,可以不做处理,当然你可以验证下UTF-8等等。
2:当导航到rivers开始标签时,在回调方法startElement中可以实例化一个集合用来存贮list,不过我们这里不用,因为在构造函数中已经实例化了。
3:导航到river开始标签时,就说明需要实例化River对象了,当然river标签中还有name ,length属性,因此实例化River后还必须取出属性值,attributes.getValue(NAME),同时赋予river对象中,同时添加为导航到的river标签添加一个boolean为真的标识,用来说明导航到了river元素。
4:当然有river标签内还有子标签(节点),但是SAX解析器是不知道导航到什么标签的,它只懂得开始,结束而已。那么如何让它认得我们的各个标签呢?当然需要判断了,于是可以使用回调方法startElement中的参数String localName,把我们的标签字符串与这个参数比较下,就可以了。我们还必须让SAX知道,现在导航到的是某个标签,因此添加一个true属性让SAX解析器知道。
5:它还会导航到文本内标签,(就是a1f02c36ba31691bcfe87b2722de723ba376092e9406724d5c271fcc648ed25a里面的内容),回调方法characters,我们一般在这个方法中取出就是a1f02c36ba31691bcfe87b2722de723ba376092e9406724d5c271fcc648ed25a里面的内容,并保存。 6:当然它是一定会导航到结束标签130b130fec2d2f95e194298b0c54b01d 或者32597ed33a62307b98b0a630505272be的,如果是130b130fec2d2f95e194298b0c54b01d标签,记得把river对象添加进list中。如果是river中的子标签7244917fde7c9800d42f9b80557c07c0,就把前面设置标记导航到这个标签的boolean标记设置为false. 按照以上实现思路,可以实现如下代码:
/**导航到开始标签触发**/
publicvoid startElement (String uri, String localName, String qName, Attributes attributes){
String tagName=localName.length()!=0?localName:qName;
tagName=tagName.toLowerCase().trim();
//如果读取的是river标签开始,则实例化River
if(tagName.equals(RIVER)){
isRiver=true;
river=new River();
/**导航到river开始节点后**/
river.setName(attributes.getValue(NAME));
river.setLength(Integer.parseInt(attributes.getValue(LENGTH)));
}
//然后读取其他节点
if(isRiver){
if(tagName.equals(INTRODUCTION)){
xintroduction=true;
}else if(tagName.equals(IMAGEURL)){
ximageurl=true;
}
}
}
/**导航到结束标签触发**/
public void endElement (String uri, String localName, String qName){
String tagName=localName.length()!=0?localName:qName;
tagName=tagName.toLowerCase().trim();
//如果读取的是river标签结束,则把River添加进集合中
if(tagName.equals(RIVER)){
isRiver=true;
rivers.add(river);
}
//然后读取其他节点
if(isRiver){
if(tagName.equals(INTRODUCTION)){
xintroduction=false;
}else if(tagName.equals(IMAGEURL)){
ximageurl=false;
}
}
}
//这里是读取到节点内容时候回调
public void characters (char[] ch, int start, int length){
//设置属性值
if(xintroduction){
//解决null问题
river.setIntroduction(river.getIntroduction()==null?"":river.getIntroduction()+new String(ch,start,length));
}else if(ximageurl){
//解决null问题
river.setImageurl(river.getImageurl()==null?"":river.getImageurl()+new String(ch,start,length));
}
}
运行效果跟上例DOM 运行效果相同。
采用PULL解析基本处理方式:
当PULL解析器导航到文档开始标签时就开始实例化list集合用来存贮数据对象。导航到元素开始标签时回判断元素标签类型,如果是river标签,则需要实例化River对象了,如果是其他类型,则取得该标签内容并赋予River对象。当然它也会导航到文本标签,不过在这里,我们可以不用。
根据以上的解释,我们可以得出以下处理xml文档逻辑:
1:当导航到XmlPullParser.START_DOCUMENT,可以不做处理,当然你可以实例化集合对象等等。
2:当导航到XmlPullParser.START_TAG,则判断是否是river标签,如果是,则实例化river对象,并调用getAttributeValue方法获取标签中属性值。
3:当导航到其他标签,比如Introduction时候,则判断river对象是否为空,如不为空,则取出Introduction中的内容,nextText方法来获取文本节点内容
4:当然啦,它一定会导航到XmlPullParser.END_TAG的,有开始就要有结束嘛。在这里我们就需要判读是否是river结束标签,如果是,则把river对象存进list集合中了,并设置river对象为null.
由以上的处理逻辑,我们可以得出以下代码:
public List<River> parse(String xmlPath){
List<River> rivers=new ArrayList<River>();
River river=null;
InputStream inputStream=null;
//获得XmlPullParser解析器
XmlPullParser xmlParser = Xml.newPullParser();
try {
//得到文件流,并设置编码方式
inputStream=this.context.getResources().getAssets().open(xmlPath);
xmlParser.setInput(inputStream, "utf-8");
//获得解析到的事件类别,这里有开始文档,结束文档,开始标签,结束标签,文本等等事件。
int evtType=xmlParser.getEventType();
//一直循环,直到文档结束
while(evtType!=XmlPullParser.END_DOCUMENT){
switch(evtType){
case XmlPullParser.START_TAG:
String tag = xmlParser.getName();
//如果是river标签开始,则说明需要实例化对象了
if (tag.equalsIgnoreCase(RIVER)) {
river = new River();
//取出river标签中的一些属性值
river.setName(xmlParser.getAttributeValue(null, NAME));
river.setLength(Integer.parseInt(xmlParser.getAttributeValue(null, LENGTH)));
}else if(river!=null){
//如果遇到introduction标签,则读取它内容
if(tag.equalsIgnoreCase(INTRODUCTION)){
river.setIntroduction(xmlParser.nextText());
}else if(tag.equalsIgnoreCase(IMAGEURL)){
river.setImageurl(xmlParser.nextText());
}
}
break;
case XmlPullParser.END_TAG:
//如果遇到river标签结束,则把river对象添加进集合中
if (xmlParser.getName().equalsIgnoreCase(RIVER) && river != null) {
rivers.add(river);
river = null;
}
break;
default:break;
}
//如果xml没有结束,则导航到下一个river节点
evtType=xmlParser.next();
}
} catch (XmlPullParserException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}catch (IOException e1) {
// TODO Auto-generated catch block
e1.printStackTrace();
}
return rivers;
}运行效果和上面的一样。
几种解析技术的比较与总结:
对于Android的移动设备而言,因为设备的资源比较宝贵,内存是有限的,所以我们需要选择适合的技术来解析XML,这样有利于提高访问的速度。
1 DOM在处理XML文件时,将XML文件解析成树状结构并放入内存中进行处理。当XML文件较小时,我们可以选DOM,因为它简单、直观。
2 SAX则是以事件作为解析XML文件的模式,它将XML文件转化成一系列的事件,由不同的事件处理器来决定如何处理。XML文件较大时,选择SAX技术是比较合理的。虽然代码量有些大,但是它不需要将所有的XML文件加载到内存中。这样对于有限的Android内存更有效,而且Android提供了一种传统的SAX使用方法以及一个便捷的SAX包装器。 使用Android.util.Xml类,从示例中可以看出,会比使用 SAX来得简单。
3 XML pull解析并未像SAX解析那样监听元素的结束,而是在开始处完成了大部分处理。这有利于提早读取XML文件,可以极大的减少解析时间,这种优化对于连接速度较漫的移动设备而言尤为重要。对于XML文档较大但只需要文档的一部分时,XML Pull解析器则是更为有效的方法。
위 내용은 안드로이드의 XML 파싱 기술 구현에 대한 자세한 설명(사진)의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!