
집 >데이터 베이스 >MySQL 튜토리얼 >mysql에서 자주 사용하는 기본 연산 구문(10)~~Subquery [명령줄 모드]
mysql에서 자주 사용하는 기본 연산 구문(10)~~Subquery [명령줄 모드]

- 黄舟원래의
- 2017-03-03 14:22:381268검색
mysql에는 다중 테이블 조인 쿼리를 구현하기 위한 조인 쿼리가 있지만, 조인 쿼리의 성능이 매우 좋지 않아 서브 쿼리가 등장하게 됩니다.
1. 이론적으로 하위 쿼리는 쿼리 문의 어느 위치에나 나타날 수 있지만 실제 응용에서는 from과 where 뒤에 나타나는 경우가 많습니다. from 뒤에 나타나는 하위 쿼리 결과는 일반적으로 임시 테이블 역할을 하는 다중 행 및 다중 열이며, where 뒤에 나타나는 하위 쿼리 결과는 일반적으로 조건으로 작동하는 단일 행 및 단일 열입니다. >
 2. where 뒤의 조건인 하위 쿼리는 "=", "!=", ">" 및 "<"와 같은 비교 연산자와 함께 자주 사용됩니다. 결과는 일반적으로 단일 행과 단일 열이지만, 단일 행과 다중 열이 사용되는 경우도 있고, 다중 행과 단일 열이 반환되는 경우도 있습니다. 여러 행과 단일 열의 경우 in, any, all, presents:
2. where 뒤의 조건인 하위 쿼리는 "=", "!=", ">" 및 "<"와 같은 비교 연산자와 함께 자주 사용됩니다. 결과는 일반적으로 단일 행과 단일 열이지만, 단일 행과 다중 열이 사용되는 경우도 있고, 다중 행과 단일 열이 반환되는 경우도 있습니다. 여러 행과 단일 열의 경우 in, any, all, presents:
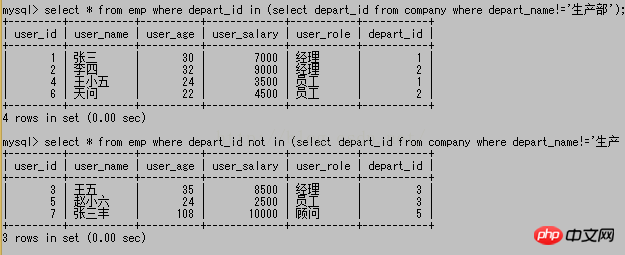 그 중 in은 후속 하위 쿼리 결과 집합에 포함되는 모든 것을 의미하고, not in은 후속 결과 집합에 포함되지 않는 것을 의미합니다. 위 그림의 하위 쿼리 결과에서 반환된 part_id는 1, 2, 4입니다. 따라서 첫 번째 쿼리에서는 emp의 모든 part_id가 1, 2, 4임을 알아내고 두 번째 쿼리에서는 1도 4도 아닙니다. 2도 4도 아닙니다.
그 중 in은 후속 하위 쿼리 결과 집합에 포함되는 모든 것을 의미하고, not in은 후속 결과 집합에 포함되지 않는 것을 의미합니다. 위 그림의 하위 쿼리 결과에서 반환된 part_id는 1, 2, 4입니다. 따라서 첫 번째 쿼리에서는 emp의 모든 part_id가 1, 2, 4임을 알아내고 두 번째 쿼리에서는 1도 4도 아닙니다. 2도 4도 아닙니다.
 = any의 사용법은 in의 효과와 동일합니다. >any는 하위 쿼리보다 크다는 의미입니다. 결과 집합은 무엇이든 괜찮습니다. 간단한 이해는 결과 집합의 가장 작은 것보다 크면 된다는 것입니다. <모든 것은 하위 쿼리 결과 집합의 어떤 것보다 작아야 합니다. 가장 큰 것보다 작아야 합니다. 따라서 여기서 >any는 1보다 커야 하고
= any의 사용법은 in의 효과와 동일합니다. >any는 하위 쿼리보다 크다는 의미입니다. 결과 집합은 무엇이든 괜찮습니다. 간단한 이해는 결과 집합의 가장 작은 것보다 크면 된다는 것입니다. <모든 것은 하위 쿼리 결과 집합의 어떤 것보다 작아야 합니다. 가장 큰 것보다 작아야 합니다. 따라서 여기서 >any는 1보다 커야 하고
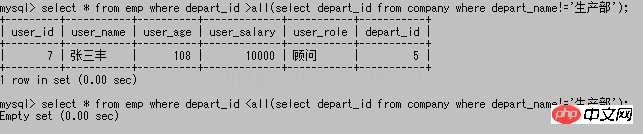 >all은 하위 쿼리 결과 집합에서 모두보다 크다는 의미입니다. 간단히 이해하면 다음보다 큽니다. Big;
>all은 하위 쿼리 결과 집합에서 모두보다 크다는 의미입니다. 간단히 이해하면 다음보다 큽니다. Big;
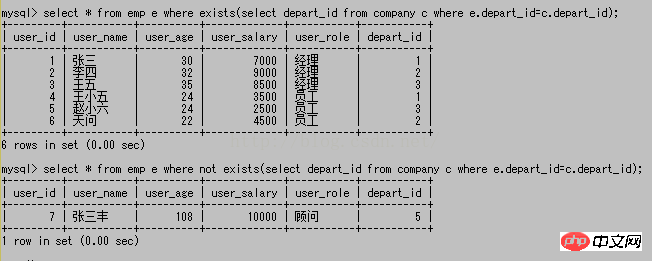
존재하고 존재하지 않음은 후속 하위 쿼리에 결과가 있는지 여부에만 관심이 있으며, 존재에 대한 하위 쿼리의 결과가 무엇인지는 중요하지 않습니다. 후속 하위 쿼리에 결과가 있으면 해당 값은 true이고, 결과가 없으면 false이며 존재하지 않는다는 것은 이와 정반대입니다. 상황이고 값이 false이면 true 값이 없습니다. 해당 값이 true인 경우 이전 쿼리의 결과가 설정되고 기본 쿼리의 결과 집합에 추가되며 그렇지 않으면 기본 쿼리의 결과 집합에 추가되지 않습니다.