
집 >데이터 베이스 >MySQL 튜토리얼 >10분 안에 MySQL의 잘못된 문제를 이해하고 해결하는 방법을 알아보세요.
10분 안에 MySQL의 잘못된 문제를 이해하고 해결하는 방법을 알아보세요.

- 黄舟원래의
- 2017-02-23 10:51:521394검색
이 글에서는 MySQL 문자 깨짐 현상의 원인과 구체적인 해결방안을 자세히 소개합니다. >
왜 왜곡된 문자가 나타나는지 이해하려면 먼저 클라이언트가 요청을 시작하는 시점부터 MySQL이 데이터를 저장하는 시점, 클라이언트가 다음에 테이블에서 데이터를 검색하는 시점까지 어떤 링크에 인코딩이 적용되는지 이해해야 합니다. /디코딩 동작. 이 과정을 더 잘 설명하기 위해 블로거는 입금과 출금의 두 단계에 해당하는 두 개의 흐름도를 제작했습니다. MySQL에 저장하기 위한 인코딩 변환 과정위 그림(빨간색 화살표)에는 3가지 인코딩/디코딩 과정이 있습니다. 세 개의 빨간색 화살표는 각각 클라이언트 인코딩, MySQL Server 디코딩 및 클라이언트 인코딩에서 테이블 인코딩으로의 변환에 해당합니다. 터미널은 Bash, 웹페이지 또는 앱일 수 있습니다. 이 기사에서는 Bash가 사용자 측의 입력 및 디스플레이 인터페이스인 터미널이라고 가정합니다. 그림의 각 상자에 해당하는 동작은 다음과 같습니다. 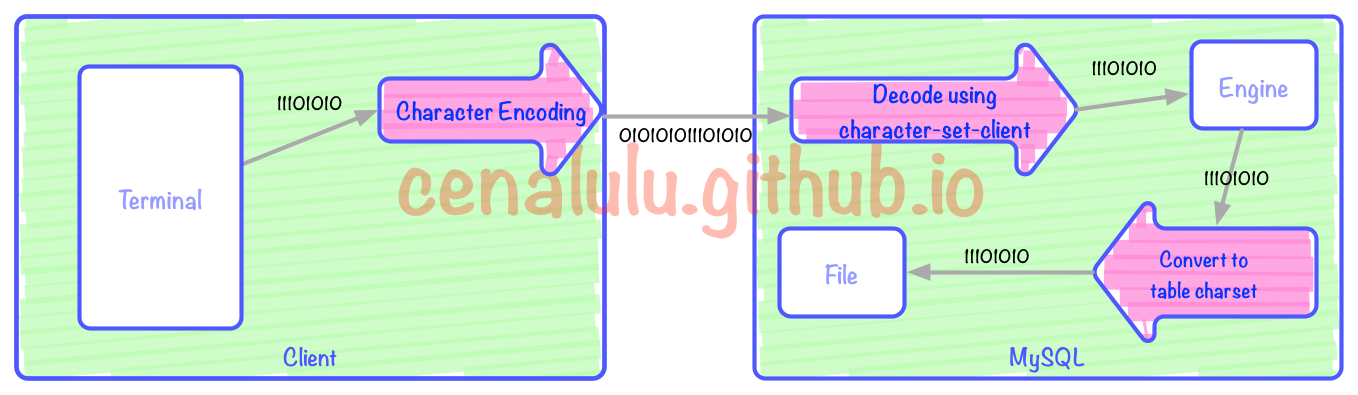
- 터미널에서 변환합니다. 문자 인코딩에 따라 바이너리 스트림으로
- 바이너리 스트림은 MySQL 클라이언트를 통해 MySQL 서버로 전송됩니다.
- 서버는 문자를 통해 디코딩합니다. set-client
- character-set-client가 대상 테이블의 10분 안에 MySQL의 잘못된 문제를 이해하고 해결하는 방법을 알아보세요.과 일치하는지 확인
- 일치하지 않는 경우 다음을 수행합니다. client-10분 안에 MySQL의 잘못된 문제를 이해하고 해결하는 방법을 알아보세요.에서 table-10분 안에 MySQL의 잘못된 문제를 이해하고 해결하는 방법을 알아보세요.으로 문자 인코딩 변환
- 변환된 문자 인코딩 바이너리 스트림을 파일로 저장
- 인코딩 변환 과정 MySQL 테이블에서 데이터 검색
위 그림에는 세 가지 인코딩/디코딩 프로세스(빨간색 화살표)가 있습니다. 위 그림의 세 개의 빨간색 화살표는 각각 클라이언트 디코딩 표시, 문자 세트 클라이언트에 따른 MySQL Server 인코딩, 테이블 인코딩에서 문자 세트 클라이언트 인코딩 변환에 해당합니다. 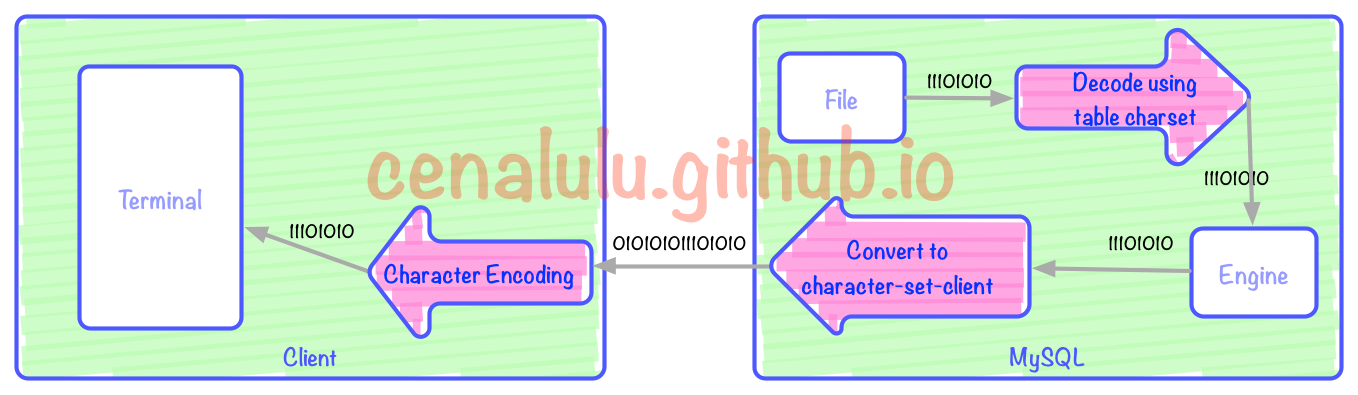
- 테이블 문자 집합 인코딩을 사용하여 디코딩
- 데이터 변환 문자 집합 클라이언트의 인코딩으로
- 문자 집합 클라이언트를 사용하여 바이너리 스트림으로 인코딩
- 서버가 다음으로 전송됩니다. 네트워크를 통해 서버 원격 클라이언트
- 클라이언트는 bash에 구성된 문자 인코딩을 통해 쿼리 결과를 표시합니다
- MySQL 문자가 왜곡되는 이유
1. 입출금 시 해당 링크의 코딩이 일치하지 않습니다
이로 인해 코드가 깨질 것은 당연합니다. 저장 단계의 세 가지 인코딩 및 디코딩 단계에 사용되는 문자 집합에 C1, C2, C3이라는 번호가 지정됩니다(그림 1의 왼쪽에서 오른쪽으로). 검색 단계에 사용되는 세 가지 문자 집합에 C1', C2라는 번호가 지정됩니다. ', C3'(왼쪽에서 오른쪽으로). 그런 다음 저장 시 bash C1은 UTF-8 인코딩을 사용하지만 이를 꺼낼 때는 C1'에 대해 Windows 터미널(기본값은 GBK 인코딩)을 사용하므로 결과가 거의 확실히 왜곡될 것입니다. 아니면 MySQL에 저장할 때는 세트명 utf8(C2)을 사용했는데, 꺼낼 때는 세트명 gbk(C2')를 사용하면 결과가 깨져야 합니다
2. 3단계 단일 프로세스 단계의 코딩이 일치하지 않습니다
즉, 위 그림 중 하나에서 같은 방향의 세 단계 중 두 개 이상의 단계의 코딩이 일치하지 않는 한 코딩 및 디코딩 오류가 발생합니다. 발생할 수 있습니다. 서로 다른 두 문자 집합 간에 무손실 인코딩 변환을 수행할 수 없는 경우(아래에 자세히 설명) 잘못된 문자가 나타납니다. 예를 들어, 쉘은 UTF8로 인코딩되어 있고, MySQL의 문자 세트 클라이언트는 GBK로 구성되어 있으며, 테이블 구조는 10분 안에 MySQL의 잘못된 문제를 이해하고 해결하는 방법을 알아보세요.=utf8이므로 의심할 여지 없이 잘못된 문자가 있을 것입니다. 여기서 이 상황을 간단히 설명하겠습니다
master [localhost] {msandbox} (test) > create table 10분 안에 MySQL의 잘못된 문제를 이해하고 해결하는 방법을 알아보세요._test_utf8 (id int primary key auto_increment, char_col varchar(50)) 10분 안에 MySQL의 잘못된 문제를 이해하고 해결하는 방법을 알아보세요. = utf8;
Query OK, 0 rows affected (0.04 sec)
master [localhost] {msandbox} (test) > set names gbk;
Query OK, 0 rows affected (0.00 sec)
master [localhost] {msandbox} (test) > insert into 10분 안에 MySQL의 잘못된 문제를 이해하고 해결하는 방법을 알아보세요._test_utf8 (char_col) values ('中文');
Query OK, 1 row affected, 1 warning (0.01 sec)
master [localhost] {msandbox} (test) > show warnings;
+---------+------+---------------------------------------------------------------------------+
| Level | Code | Message |
+---------+------+---------------------------------------------------------------------------+
| Warning | 1366 | Incorrect string value: '\xAD\xE6\x96\x87' for column 'char_col' at row 1 |
+---------+------+---------------------------------------------------------------------------+
1 row in set (0.00 sec)
master [localhost] {msandbox} (test) > select id,hex(char_col),char_col from 10분 안에 MySQL의 잘못된 문제를 이해하고 해결하는 방법을 알아보세요._test_utf8;
+----+----------------+----------+
| id | hex(char_col) | char_col |
+----+----------------+----------+
| 1 | E6B6933FE69E83 | �?�� |
+----+----------------+----------+
1 row in set (0.01 sec)MySQL 인코딩/디코딩 정보
시스템은 바이너리 스트림에 따라 전송되므로 이 바이너리 스트림 문자열을 직접 변환합니다. 테이블 파일. 저장하기 전에 두 가지 인코딩 및 디코딩 작업을 수행해야 하는 이유는 무엇입니까? 클라이언트-서버 인코딩 및 디코딩을 수행하는 이유는 MySQL이 들어오는 바이너리 스트림에 대해 구문 및 어휘 분석을 수행해야 하기 때문입니다. 인코딩 분석 및 검증을 하지 않으면 전달된 바이너리 스트림이 삽입인지 업데이트인지조차 알 수 없습니다.
- File to Engine의 인코딩 및 디코딩은 바이너리 스트림의 단어 분할 상황을 아는 것입니다. 간단한 예를 들자면, 테이블에서 특정 필드의 처음 두 문자를 검색하고 select left(col,2) from table 형식의 명령문을 실행하려고 합니다. 스토리지 엔진은 테이블에서 열 값을 읽습니다. E4B8ADE69687. 따라서 이때 이 값을 GBK에 따라 E4B8, ADE6, 9687 세 단어로 나누면 클라이언트에 반환되는 값은 UTF8에 따라 E4B8AD와 E69687로 나누면 E4B8ADE69687 두 단어가 됩니다. 반환되어야 합니다. 데이터 파일에서 데이터를 읽으면 인코딩 및 디코딩 없이는 스토리지 엔진 내부에서 문자 수준 작업을 수행할 수 없음을 알 수 있습니다.
关于错进错出
在MySQL中最常见的乱码问题的起因就是把错进错出神话。所谓的错进错出就是,客户端(web或shell)的字符编码和最终表的字符编码格式不同,但是只要保证存和取两次的字符集编码一致就仍然能够获得没有乱码的输出的这种现象。但是,错进错出并不是对于任意两种字符集编码的组合都是有效的。我们假设客户端的编码是C,MySQL表的字符集编码是S。那么为了能够错进错出,需要满足以下两个条件
MySQL接收请求时,从C编码后的二进制流在被S解码时能够无损
MySQL返回数据是,从S编码后的二进制流在被C解码时能够无损
编码无损转换
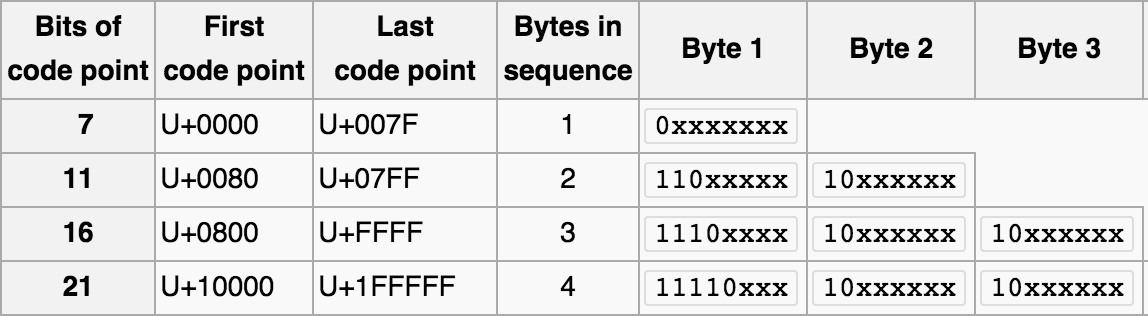
那么什么是有损转换,什么是无损转换呢?假设我们要把用编码A表示的字符X,转化为编码B的表示形式,而编码B的字形集中并没有X这个字符,那么此时我们就称这个转换是有损的。那么,为什么会出现两个编码所能表示字符集合的差异呢?如果大家看过博主之前的那篇 十分钟搞清字符集和字符编码,或者对字符编码有基础理解的话,就应该知道每个字符集所支持的字符数量是有限的,并且各个字符集涵盖的文字之间存在差异。UTF8和GBK所能表示的字符数量范围如下
GBK单个字符编码后的取值范围是:8140 - FEFE 其中不包括**7E,总共字符数在27000左右
UTF8单个字符编码后,按照字节数的不同,取值范围如下表:
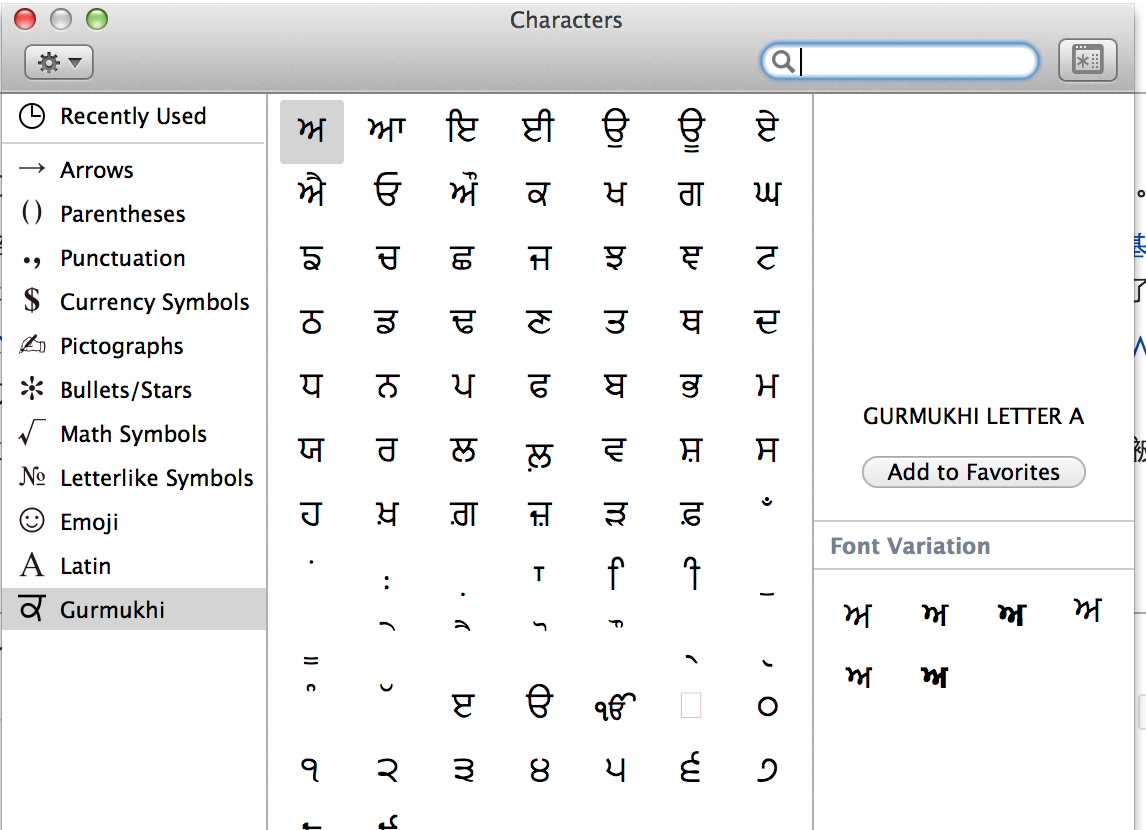
由于UTF-8编码能表示的字符数量远超GBK。那么我们很容易就能找到一个从UTF8到GBK的有损编码转换。我们用字符映射器(见下图)找出了一个明显就不在GBK编码表中的字符,尝试存入到GBK编码的表中。并再次取出查看有损转换的行为
字符信息具体是:ਅ GURMUKHI LETTER A Unicode: U+0A05, UTF-8: E0 A8 85
在MySQL中存储的具体情况如下:
master [localhost] {msandbox} (test) > create table 10분 안에 MySQL의 잘못된 문제를 이해하고 해결하는 방법을 알아보세요._test_gbk (id int primary key auto_increment, char_col varchar(50)) 10분 안에 MySQL의 잘못된 문제를 이해하고 해결하는 방법을 알아보세요. = gbk;
Query OK, 0 rows affected (0.00 sec)
master [localhost] {msandbox} (test) > set names utf8;
Query OK, 0 rows affected (0.00 sec)
master [localhost] {msandbox} (test) > insert into 10분 안에 MySQL의 잘못된 문제를 이해하고 해결하는 방법을 알아보세요._test_gbk (char_col) values ('ਅ');
Query OK, 1 row affected, 1 warning (0.01 sec)
master [localhost] {msandbox} (test) > show warnings;
+---------+------+-----------------------------------------------------------------------+
| Level | Code | Message |
+---------+------+-----------------------------------------------------------------------+
| Warning | 1366 | Incorrect string value: '\xE0\xA8\x85' for column 'char_col' at row 1 |
+---------+------+-----------------------------------------------------------------------+
1 row in set (0.00 sec)
master [localhost] {msandbox} (test) > select id,hex(char_col),char_col,char_length(char_col) from 10분 안에 MySQL의 잘못된 문제를 이해하고 해결하는 방법을 알아보세요._test_gbk;
+----+---------------+----------+-----------------------+
| id | hex(char_col) | char_col | char_length(char_col) |
+----+---------------+----------+-----------------------+
| 1 | 3F | ? | 1 |
+----+---------------+----------+-----------------------+
1 row in set (0.00 sec)出错的部分是在编解码的第3步时发生的。具体见下图
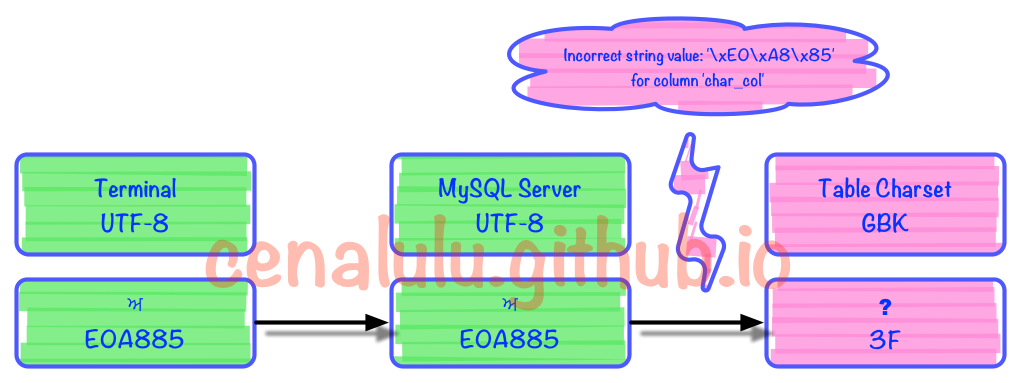
可见MySQL内部如果无法找到一个UTF8字符所对应的GBK字符时,就会转换成一个错误mark(这里是问号)。而每个字符集在程序实现的时候内部都约定了当出现这种情况时的行为和转换规则。例如:UTF8中无法找到对应字符时,如果不抛错那么就将该字符替换成� (U+FFFD)
那么是不是任何两种字符集编码之间的转换都是有损的呢?并非这样,转换是否有损取决于以下几点:
被转换的字符是否同时在两个字符集中
目标字符集是否能够对不支持字符,保留其原有表达形式
关于第一点,刚才已经通过实验来解释过了。这里来解释下造成有损转换的第二个因素。从刚才的例子我们可以看到由于GBK在处理自己无法表示的字符时的行为是:用错误标识替代,即0x3F。而有些字符集(例如latin1)在遇到自己无法表示的字符时,会保留原字符集的编码数据,并跳过忽略该字符进而处理后面的数据。如果目标字符集具有这样的特性,那么就能够实现这节最开始提到的错进错出的效果。
我们来看下面这个例子
master [localhost] {msandbox} (test) > create table 10분 안에 MySQL의 잘못된 문제를 이해하고 해결하는 방법을 알아보세요._test (id int primary key auto_increment, char_col varchar(50)) 10분 안에 MySQL의 잘못된 문제를 이해하고 해결하는 방법을 알아보세요. = latin1;
Query OK, 0 rows affected (0.03 sec)
master [localhost] {msandbox} (test) > set names latin1;
Query OK, 0 rows affected (0.00 sec)
master [localhost] {msandbox} (test) > insert into 10분 안에 MySQL의 잘못된 문제를 이해하고 해결하는 방법을 알아보세요._test (char_col) values ('中文');
Query OK, 1 row affected (0.01 sec)
master [localhost] {msandbox} (test) > select id,hex(char_col),char_col from 10분 안에 MySQL의 잘못된 문제를 이해하고 해결하는 방법을 알아보세요._test;
+----+---------------+----------+
| id | hex(char_col) | char_col |
+----+---------------+----------+
| 2 | E4B8ADE69687 | 中文 |
+----+---------------+----------+
2 rows in set (0.00 sec)具体流程图如下。可见在被MySQL Server接收到以后实际上已经发生了编码不一致的情况。但是由于Latin1字符集对于自己表述范围外的字符不会做任何处理,而是保留原值。这样的行为也使得错进错出成为了可能。
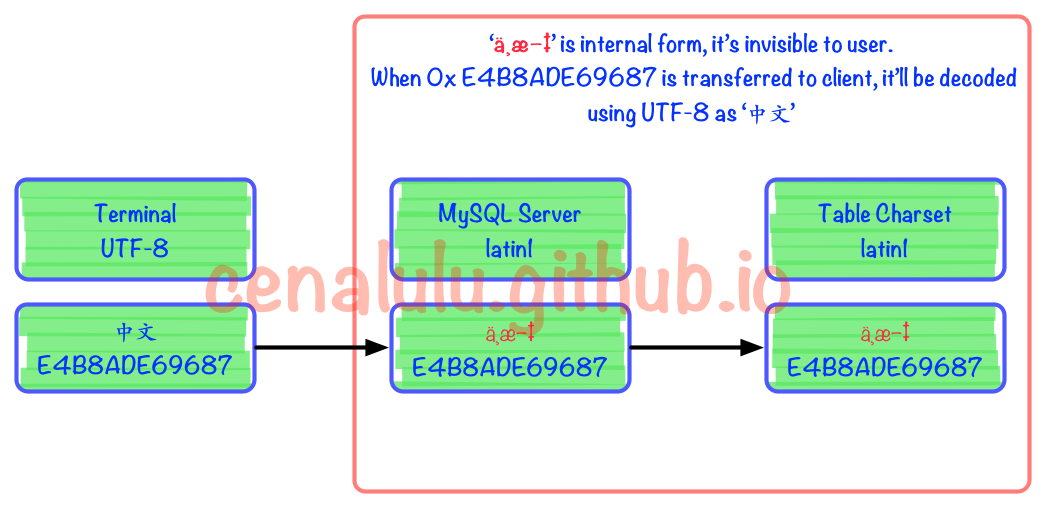
如何避免乱码
理解了上面的内容,要避免乱码就显得很容易了。只要做到“三位一体”,即客户端,MySQL character-set-client,table 10분 안에 MySQL의 잘못된 문제를 이해하고 해결하는 방법을 알아보세요.三个字符集完全一致就可以保证一定不会有乱码出现了。而对于已经出现乱码,或者已经遭受有损转码的数据,如何修复相对来说就会有些困难。下一节我们详细介绍具体方法。
如何修复已经编码损坏的数据
在介绍正确方法前,我们先科普一下那些网上流传的所谓的“正确方法”可能会造成的严重后果。
错误方法一
无论从语法还是字面意思来看:ALTER TABLE ... CHARSET=xxx 无疑是最像包治乱码的良药了!而事实上,他对于你已经损坏的数据一点帮助也没有,甚至连已经该表已经创建列的默认字符集都无法改变。我们看下面这个例子
master [localhost] {msandbox} (test) > show create table 10분 안에 MySQL의 잘못된 문제를 이해하고 해결하는 방법을 알아보세요._test;
+--------------+--------------------------------+
| Table | Create Table |
+--------------+--------------------------------+
| 10분 안에 MySQL의 잘못된 문제를 이해하고 해결하는 방법을 알아보세요._test | CREATE TABLE `10분 안에 MySQL의 잘못된 문제를 이해하고 해결하는 방법을 알아보세요._test` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`char_col` varchar(50) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=latin1 |
+--------------+--------------------------------+
1 row in set (0.00 sec)
master [localhost] {msandbox} (test) > alter table 10분 안에 MySQL의 잘못된 문제를 이해하고 해결하는 방법을 알아보세요._test 10분 안에 MySQL의 잘못된 문제를 이해하고 해결하는 방법을 알아보세요.=gbk;
Query OK, 0 rows affected (0.03 sec)
Records: 0 Duplicates: 0 Warnings: 0
master [localhost] {msandbox} (test) > show create table 10분 안에 MySQL의 잘못된 문제를 이해하고 해결하는 방법을 알아보세요._test;
+--------------+--------------------------------+
| Table | Create Table |
+--------------+--------------------------------+
| 10분 안에 MySQL의 잘못된 문제를 이해하고 해결하는 방법을 알아보세요._test | CREATE TABLE `10분 안에 MySQL의 잘못된 문제를 이해하고 해결하는 방법을 알아보세요._test` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`char_col` varchar(50) CHARACTER SET latin1 DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=gbk |
+--------------+--------------------------------+
1 row in set (0.00 sec)可见该语法紧紧修改了表的默认字符集,即只对以后创建的列的默认字符集产生影响,而对已经存在的列和数据没有变化。
错误方法二
ALTER TABLE … CONVERT TO CHARACTER SET … 的相较于方法一来说杀伤力更大,因为从 官方文档的解释 他的作用就是用于对一个表的数据进行编码转换。下面是文档的一小段摘录:
To change the table default character set and all character columns (CHAR, VARCHAR, TEXT) to a new character set, use a statement like this:
ALTER TABLE tbl_name
CONVERT TO CHARACTER SET 10분 안에 MySQL의 잘못된 문제를 이해하고 해결하는 방법을 알아보세요._name [COLLATE collation_name];
而实际上,这句语法只适用于当前并没有乱码,并且不是通过错进错出的方法保存的表。。而对于已经因为错进错出而产生编码错误的表,则会带来更糟的结果。我们用一个实际例子来解释下,这句SQL实际做了什么和他会造成的结果。假设我们有一张编码是latin1的表,且之前通过错进错出存入了UTF-8的数据,但是因为通过terminal仍然能够正常显示。即上文错进错出章节中举例的情况。一段时间使用后我们发现了这个错误,并打算把表的字符集编码改成UTF-8并且不影响原有数据的正常显示。这种情况下使用alter table convert to character set会有这样的后果:
master [localhost] {msandbox} (test) > create table 10분 안에 MySQL의 잘못된 문제를 이해하고 해결하는 방법을 알아보세요._test_latin1 (id int primary key auto_increment, char_col varchar(50)) 10분 안에 MySQL의 잘못된 문제를 이해하고 해결하는 방법을 알아보세요. = latin1;
Query OK, 0 rows affected (0.01 sec)
master [localhost] {msandbox} (test) > set names latin1;
Query OK, 0 rows affected (0.00 sec)
master [localhost] {msandbox} (test) > insert into 10분 안에 MySQL의 잘못된 문제를 이해하고 해결하는 방법을 알아보세요._test_latin1 (char_col) values ('这是中文');
Query OK, 1 row affected (0.01 sec)
master [localhost] {msandbox} (test) > select id,hex(char_col),char_col,char_length(char_col) from 10분 안에 MySQL의 잘못된 문제를 이해하고 해결하는 방법을 알아보세요._test_latin1;
+----+--------------------------+--------------+-----------------------+
| id | hex(char_col) | char_col | char_length(char_col) |
+----+--------------------------+--------------+-----------------------+
| 1 | E8BF99E698AFE4B8ADE69687 | 这是中文 | 12 |
+----+--------------------------+--------------+-----------------------+
1 row in set (0.01 sec)
master [localhost] {msandbox} (test) > alter table 10분 안에 MySQL의 잘못된 문제를 이해하고 해결하는 방법을 알아보세요._test_latin1 convert to character set utf8;
Query OK, 1 row affected (0.04 sec)
Records: 1 Duplicates: 0 Warnings: 0
master [localhost] {msandbox} (test) > set names utf8;
Query OK, 0 rows affected (0.00 sec)
master [localhost] {msandbox} (test) > select id,hex(char_col),char_col,char_length(char_col) from 10분 안에 MySQL의 잘못된 문제를 이해하고 해결하는 방법을 알아보세요._test_latin1;
+----+--------------------------------------------------------+-----------------------------+-----------------------+
| id | hex(char_col) | char_col | char_length(char_col) |
+----+--------------------------------------------------------+-----------------------------+-----------------------+
| 1 | C3A8C2BFE284A2C3A6CB9CC2AFC3A4C2B8C2ADC3A6E28093E280A1 | 这是ä¸æ–‡ | 12 |
+----+--------------------------------------------------------+-----------------------------+-----------------------+
1 row in set (0.00 sec)从这个例子我们可以看出,对于已经错进错出的数据表,这个命令不但没有起到“拨乱反正”的效果,还会彻底将数据糟蹋,连数据的二进制编码都改变了。
正确的方法一 Dump & Reload
这个方法比较笨,但也比较好操作和理解。简单的说分为以下三步:
通过错进错出的方法,导出到文件
用正确的字符集修改新表
将之前导出的文件导回到新表中
还是用上面那个例子举例,我们用UTF-8将数据“错进”到latin1编码的表中。现在需要将表编码修改为UTF-8可以使用以下命令
shell> mysqldump -u root -p -d --skip-set-10분 안에 MySQL의 잘못된 문제를 이해하고 해결하는 방법을 알아보세요. --default-character-set=utf8 test 10분 안에 MySQL의 잘못된 문제를 이해하고 해결하는 방법을 알아보세요._test_latin1 > data.sql #确保导出的文件用文本编辑器在UTF-8编码下查看没有乱码 shell> mysql -uroot -p -e 'create table 10분 안에 MySQL의 잘못된 문제를 이해하고 해결하는 방법을 알아보세요._test_latin1 (id int primary key auto_increment, char_col varchar(50)) 10분 안에 MySQL의 잘못된 문제를 이해하고 해결하는 방법을 알아보세요. = utf8' test shell> mysql -uroot -p --default-character-set=utf8 test < data.sql
正确的方法二 Convert to Binary & Convert Back
这种方法比较取巧,用的是将二进制数据作为中间数据的做法来实现的。由于,MySQL再将有编码意义的数据流,转换为无编码意义的二进制数据的时候并不做实际的数据转换。而从二进制数据准换为带编码的数据时,又会用目标编码做一次编码转换校验。通过这两个特性就相当于在MySQL内部模拟了一次“错出”,将乱码“拨乱反正”了。
还是用上面那个例子举例,我们用UTF-8将数据“错进”到latin1编码的表中。现在需要将表编码修改为UTF-8可以使用以下命令
mysql> ALTER TABLE 10분 안에 MySQL의 잘못된 문제를 이해하고 해결하는 방법을 알아보세요._test_latin1 MODIFY COLUMN char_col VARBINARY(50); mysql> ALTER TABLE 10분 안에 MySQL의 잘못된 문제를 이해하고 해결하는 방법을 알아보세요._test_latin1 MODIFY COLUMN char_col varchar(50) character set utf8;
以上就是10分钟学会理解和解决MySQL乱码问题的内容,更多相关内容请关注PHP中文网(www.php.cn)!