
Python에서 간단한 크롤러 기능을 구현하는 예

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB원래의
- 2016-12-05 13:27:121883검색
우리는 매일 인터넷을 검색하다 보면 멋진 사진들을 자주 보게 되는데, 우리는 이 사진들을 저장하고 다운로드하거나 바탕화면이나 디자인 자료로 사용하고 싶어합니다.
가장 일반적인 방법은 마우스 오른쪽 버튼을 클릭하고 다른 이름으로 저장을 선택하는 것입니다. 그러나 일부 사진에는 마우스 오른쪽 버튼을 클릭할 때 다른 이름으로 저장 옵션이 없습니다. 다른 방법은 스크린샷 도구를 사용하여 캡처하는 것이지만 이렇게 하면 사진의 선명도가 떨어집니다. 알았어~! 실제로 페이지 소스 코드를 보려면 마우스 오른쪽 버튼을 클릭하세요.
파이썬을 사용하여 이러한 간단한 크롤러 기능을 구현하고 원하는 코드를 로컬에서 크롤링할 수 있습니다. Python을 사용하여 이러한 함수를 구현하는 방법을 살펴보겠습니다.
1. 전체 페이지 데이터 가져오기
먼저 다운로드할 이미지의 전체 페이지 정보를 얻을 수 있습니다.
getjpg.py
#coding=utf-8
import urllib
def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html
html = getHtml("http://tieba.baidu.com/p/2738151262")
print html
Urllib 모듈은 웹페이지 데이터를 읽기 위한 인터페이스를 제공합니다. 로컬 파일을 읽는 것처럼 www와 ftp에서 데이터를 읽을 수 있습니다. 먼저 getHtml() 함수를 정의합니다.
urllib.urlopen() 메소드는 URL 주소를 여는 데 사용됩니다.
read() 메소드는 URL의 데이터를 읽고 URL을 getHtml() 함수에 전달하고 전체 페이지를 다운로드하는 데 사용됩니다. 프로그램을 실행하면 전체 웹 페이지가 인쇄됩니다.
2. 페이지에서 원하는 데이터를 필터링합니다
Python은 매우 강력한 정규식을 제공합니다. 먼저 Python 정규식에 대해 조금 알아야 합니다.
Baidu Tieba에서 몇 가지 아름다운 배경화면을 발견하고 도구를 보기 위해 이전 섹션으로 이동한다고 가정해 보겠습니다. 다음과 같은 사진 주소를 찾았습니다: src=”http://imgsrc.baidu.com/forum...jpg” pic_ext=”jpeg”
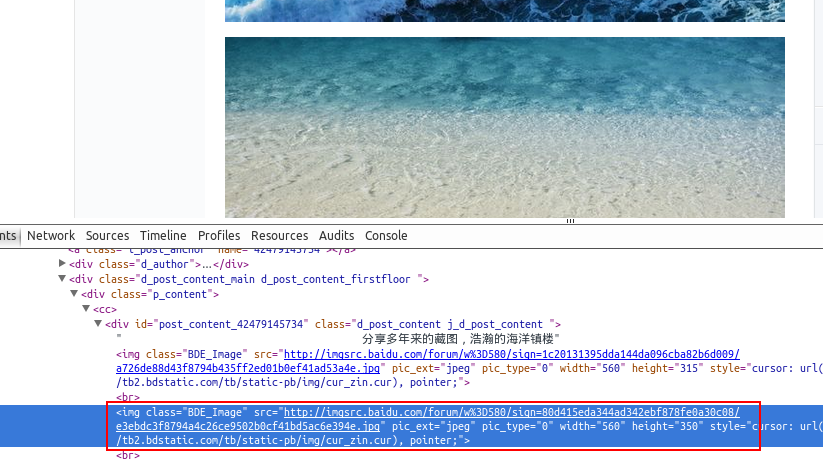
코드를 다음과 같이 수정하세요.
import re
import urllib
def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html
def getImg(html):
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = re.compile(reg)
imglist = re.findall(imgre,html)
return imglist
html = getHtml("http://tieba.baidu.com/p/2460150866")
print getImg(html)
얻은 전체 페이지에서 필요한 이미지 링크를 필터링하기 위해 getImg() 함수를 만들었습니다. re 모듈에는 주로 정규 표현식이 포함되어 있습니다:
re.compile()은 정규식을 정규식 객체로 컴파일할 수 있습니다.
re.findall() 메소드는 html에서 imgre(정규 표현식)가 포함된 데이터를 읽습니다.
스크립트를 실행하면 전체 페이지에 포함된 이미지의 URL 주소를 얻을 수 있습니다.
3. 페이지 필터링된 데이터를 로컬에 저장
for 루프를 통해 필터링된 이미지 주소를 탐색하고 로컬에 저장합니다.
#coding=utf-8
import urllib
import re
def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html
def getImg(html):
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = re.compile(reg)
imglist = re.findall(imgre,html)
x = 0
for imgurl in imglist:
urllib.urlretrieve(imgurl,'%s.jpg' % x)
x+=1
html = getHtml("http://tieba.baidu.com/p/2460150866")
print getImg(html)
여기서 핵심은 urllib.urlretrieve() 메서드를 사용하여 원격 데이터를 로컬에 직접 다운로드하는 것입니다.
얻은 이미지 연결을 for 루프를 통해 탐색합니다. 이미지 파일 이름을 보다 표준화되게 보이도록 이름 지정 규칙은 x 변수에 1을 추가하는 것입니다. 저장 위치는 기본적으로 프로그램의 저장 디렉터리입니다.
프로그램을 실행하면 로컬 디렉터리에 다운로드된 파일을 확인할 수 있습니다.
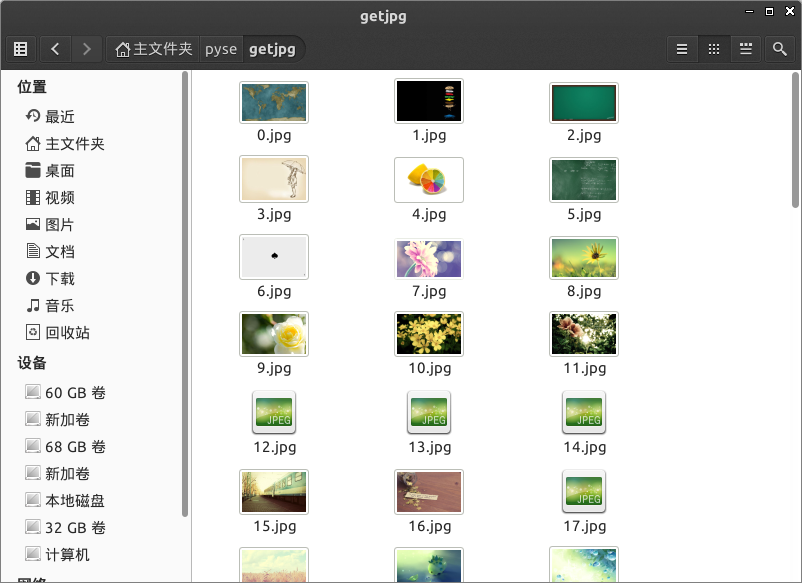
읽어주셔서 감사합니다. 도움이 되기를 바랍니다. 이 사이트를 지원해 주셔서 감사합니다!