



比如说有个name列和一个eamil列,如果数据库里面有条记录的这两列的值相同(我说的是这条记录的对应的那两列的值相同,并不是同一条记录里面两列值相同)的话就自动删除其他多余的列而保留最新的那一条(也就是ID最小的那个,ID是一个自增主键)
——————————————————
也就是说表里面有两条记录的name都是admin,email都是abc@163.com,我只想保留其中一条,这该怎么做
回复内容:
其实你会用英文搜索的话。可以很方便在stack overflow上 找到相关的信息 真的学CS的就不要用百度了 用google你会发现一个不一样的世界的随便贴一个
sql - How can I remove duplicate rows?
稍微讲一下其中一个思路(里面有很多很好的答案 你可以自己去看)
就是做一个group by 保留其中id 最大的(你说自增长 id最大的应该就是最新的)就可以了
具体sql query 可以这样写
<span class="k">delete</span> <span class="k">from</span> <span class="n">test</span> <span class="k">where</span> <span class="n">id</span> <span class="k">not</span> <span class="k">in</span><span class="p">(</span>
<span class="k">select</span> <span class="n">name</span><span class="p">,</span><span class="n">email</span><span class="p">,</span><span class="k">max</span><span class="p">(</span><span class="n">id</span><span class="p">)</span> <span class="k">from</span> <span class="n">test</span>
<span class="k">group</span> <span class="k">by</span> <span class="n">name</span><span class="p">,</span><span class="n">email</span> <span class="k">having</span> <span class="n">id</span> <span class="k">is</span> <span class="k">not</span> <span class="k">null</span><span class="p">)</span>
distinct
如果要保留id的最小值,例如:数据:
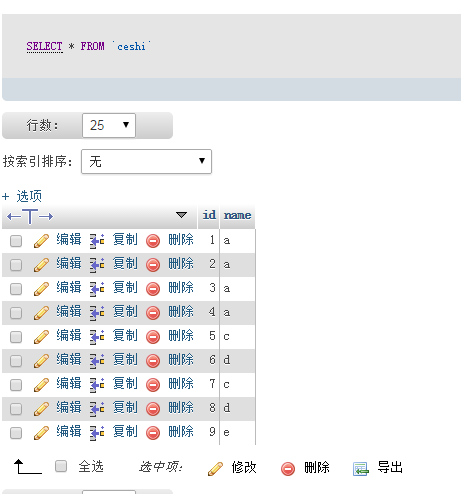

执行sql:select count(*) as count ,name,id from ceshi group by name
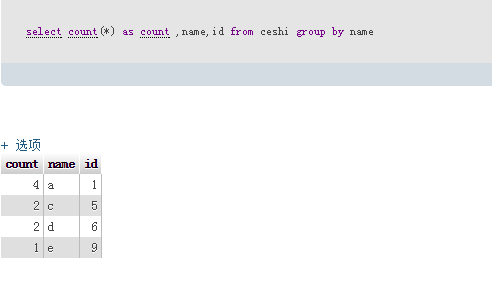 最后要删除的sql为:delete from ceshi where id not in (select count(*) as count ,name,id from ceshi group by name)
最后要删除的sql为:delete from ceshi where id not in (select count(*) as count ,name,id from ceshi group by name)如果想保留id的最大值:
简单的办法是:delete from ceshi where id not in (select count(*) as count ,name,id from (select * from ceshi order by id desc) group by name) distinct 其实非常的简单,只需要把你这张表当成两张表来处理就行了。
DELETE p1 from TABLE p1, TABLE p2 WHERE p1.name = p2.name AND p1.email = p2.email AND p1.id 这里有个问题,题主说保留最新的那一条(也就是ID最小的那个),既然是递增,最新的不应该是最大的那条吗?
上面的的语句,p1.id '即可。
当然是用group by,count可以更精准控制重复n次的情况。不过目测楼主需求应该只要把重复的删掉,保留最新的就可以了。 DELETE FROM table WHERE id not in ( SELECT
tb.id FROM ( SELECT tmp.* FROM table tmp ) tb GROUP BY tb.field1, tb.field2,… );
table是表名,field是要去重的字段。 新建一个表,设置name,email为唯一索引,然后重新插入旧表数据

 鸿蒙原生应用随机诗词Feb 19, 2024 pm 01:36 PM
鸿蒙原生应用随机诗词Feb 19, 2024 pm 01:36 PM想了解更多关于开源的内容,请访问:51CTO鸿蒙开发者社区https://ost.51cto.com运行环境DAYU200:4.0.10.16SDK:4.0.10.15IDE:4.0.600一、创建应用点击File->newFile->CreateProgect。选择模版:【OpenHarmony】EmptyAbility:填写项目名,shici,应用包名com.nut.shici,应用存储位置XXX(不要有中文,特殊字符,空格)。CompileSDK10,Model:Stage。Device
 Python如何使用email、smtplib、poplib、imaplib模块收发邮件May 16, 2023 pm 11:44 PM
Python如何使用email、smtplib、poplib、imaplib模块收发邮件May 16, 2023 pm 11:44 PM一封电子邮件的旅程是:MUA:MailUserAgent——邮件用户代理。(即类似Outlook的电子邮件软件)MTA:MailTransferAgent——邮件传输代理,就是那些Email服务提供商,比如网易、新浪等等。MDA:MailDeliveryAgent——邮件投递代理。Email服务提供商的某个服务器发件人->MUA->MTA->MTA->若
 comcn和com有什么区别May 12, 2023 pm 04:08 PM
comcn和com有什么区别May 12, 2023 pm 04:08 PMcomcn和com的区别:1、comcn和com在含义等方面有区别,在访问速度上没有区别;2、comcn属于国际域名,是全球通用顶级域名,供商业机构使用,而cn是中国的公司域名,国内商业机构,国内域名,必须企业才可以备案;3、搜索的优先顺序是cn先会去搜索.cn,找到.cn服务器后,再由.cn服务器搜索.com;4、cn由cnnic中国互联网中心管理,com的管理机构在国外。
 php提交表单通过后,弹出的对话框怎样在当前页弹出,该如何解决Jun 13, 2016 am 10:23 AM
php提交表单通过后,弹出的对话框怎样在当前页弹出,该如何解决Jun 13, 2016 am 10:23 AMphp提交表单通过后,弹出的对话框怎样在当前页弹出php提交表单通过后,弹出的对话框怎样在当前页弹出而不是在空白页弹出?想实现这样的效果:而不是空白页弹出:------解决方案--------------------如果你的验证用PHP在后端,那么就用Ajax;仅供参考:HTML code<form name="myform"
 springboot admin监控的作用和使用方法是什么May 25, 2023 pm 06:52 PM
springboot admin监控的作用和使用方法是什么May 25, 2023 pm 06:52 PM适用场景:1、项目规模不大2、用户量不是很大、并发要求不强3、无专门运维力量4、精致的团队规模对于一些常规的项目,或者企业职责分工不是非常明确的单位来说。往往一个系统从需求到设计,开发,测试到最终上线,运维。往往80%的任务由开发团队来完成。由此,开发人员除了要实现系统的功能,还要为客户进行问题咨询答疑以及生产问题解决。试想,一个应用上线后,没有任何监控措施。跟开着一辆没有任何仪表盘的汽车一样,这样上路,任何人都没有安全感。如何在极简和追求效率上做平衡是一件特别值得思考的事情。一、Springb
 您需要admin提供的权限才能对此文件进行更改怎么解决Jul 26, 2023 am 10:56 AM
您需要admin提供的权限才能对此文件进行更改怎么解决Jul 26, 2023 am 10:56 AM您需要admin提供的权限才能对此文件进行更改解决方法:1、在登录界面选择管理员账户并输入密码后,就可以顺利对文件进行修改了;2、可以通过右键点击文件选择“以管理员身份运行”的方式解决;3、修改文件权限,右键点击文件,选择“属性”,点击“安全”选项卡,然后点击“编辑”按钮,选择自己的用户名,然后勾选“完全控制”选项;4、利用命令提示符解决问题;5、设置UA权限。
 如何使用Flask-Admin实现后台管理界面Aug 03, 2023 pm 11:30 PM
如何使用Flask-Admin实现后台管理界面Aug 03, 2023 pm 11:30 PM如何使用Flask-Admin实现后台管理界面背景介绍:随着网站和应用程序的发展,后台管理界面越来越重要。在开发过程中,我们经常需要一个方便快捷的后台管理界面来管理数据、用户和其他重要信息。Flask-Admin是一个功能强大且易于使用的Flask扩展,可以帮助我们快速实现后台管理界面。Flask-Admin是基于Flask和SQLAlchemy的一个开源项
 win10邮箱如何插入附件教程Jan 07, 2024 pm 12:14 PM
win10邮箱如何插入附件教程Jan 07, 2024 pm 12:14 PM很多用户在日常生活中都需要发送邮件来进行工作,有些更是需要附加各种插件资料进行交流,那么该怎么插入附件呢?下面就一起来看看详细的教程吧。win10邮箱如何插入附件:1、打开邮箱2、点击左上角的“新邮件”图标3、点击右上角“插入”4、点击右上角“附件”5、选择需要的“附件”6、完成即可


핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

SublimeText3 영어 버전
권장 사항: Win 버전, 코드 프롬프트 지원!

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

WebStorm Mac 버전
유용한 JavaScript 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)

SublimeText3 Linux 새 버전
SublimeText3 Linux 최신 버전
뜨거운 주제
 1374
1374 523919
523919