



<i id="dianji" title="播放"></i><i id="dm_count" title="弹幕"></i><i id="stow_count" title="收藏"></i><i id="pt"><span class="v_ctimes" title="硬币数量"></span></i>
回复内容:
用av2047063举例,访问下面的网址:【网址已隐去】@妹空酱 提醒我才想起来。。。。
先去自己申请一个appkey。。。在这里:
bilibili - 提示
然后就可以对bilibiliapi为所欲为了。。。。
B站第三方客户端就是这么开发出来的。。。


可以看到最后两个参数id=av号&page=分p
play后面的18253即为播放数。
==============================
b站有公开api啊。。。。。。。那么麻烦干嘛。。。 答主的第一次就就交在这里了,,,
———————————————————————————————————————
前不久学习了python,正好复习一下
代码如下:
import re,urllib
page=urllib.urlopen('http://m.acg.tv/video/av2046040.html')
HTML=page.read()
re_times=r'
result = re.findall(re_times,HTML)
re_title=r'
(.*)
'title=re.findall(re_title,HTML)
print title[0],'的播放次数为',result[0]
下面以av2046040为例:http://www.bilibili.com/video/av2046040/
可以看到
 使用火狐查看选中部分源代码,如下
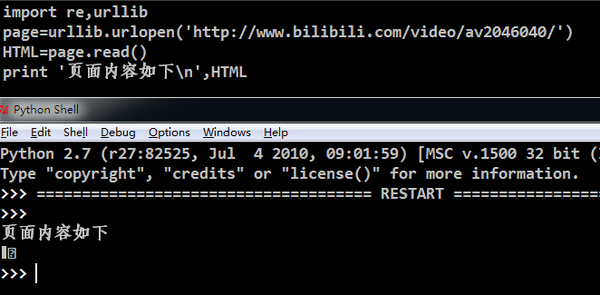
使用火狐查看选中部分源代码,如下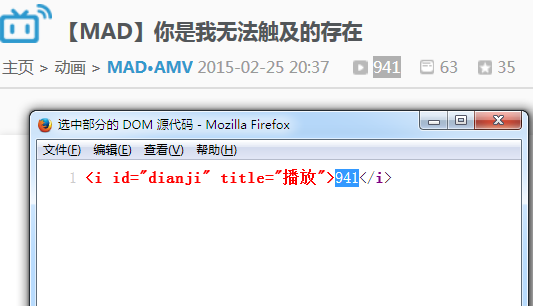 但是我通过python的urllib模块并没有获取到页面内容:
但是我通过python的urllib模块并没有获取到页面内容:page=urllib.urlopen('http://www.bilibili.com/video/av2046040/')
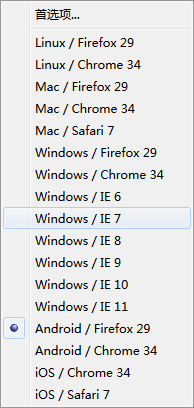
 于是我转换思路,貌似B站的手机版网页可以,
于是我转换思路,貌似B站的手机版网页可以,然后使用火狐的User-Agent Overrider修改浏览器UA为Android FireFox/29
 既可以获得如下界面:
既可以获得如下界面: 获取到页面实际地址后,就可以再次使用火狐查看源代码
获取到页面实际地址后,就可以再次使用火狐查看源代码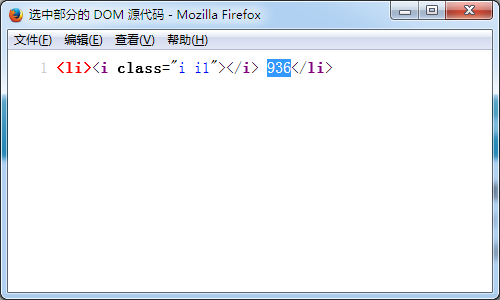 既可以写出正则表达式:
既可以写出正则表达式:re_times=r'
然后正则匹配就好了。
<span class="c"># encoding=utf8</span>
<span class="c"># author:shell-von</span>
<span class="kn">import</span> <span class="nn">requests</span>
<span class="kn">import</span> <span class="nn">re</span>
<span class="n">aid</span> <span class="o">=</span> <span class="s">'3210612'</span>
<span class="n">api_key</span> <span class="o">=</span> <span class="s">"http://interface.bilibili.com/count?key=27f582250563d5d6b11d6833&aid=</span><span class="si">%s</span><span class="s">"</span>
<span class="n">data</span> <span class="o">=</span> <span class="n">requests</span><span class="o">.</span><span class="n">get</span><span class="p">(</span><span class="n">api_key</span> <span class="o">%</span> <span class="n">aid</span><span class="p">)</span><span class="o">.</span><span class="n">content</span>
<span class="n">regex</span> <span class="o">=</span> <span class="s">r"\('(?:.|#)([\w_]+)'\)\.html\('?(\d+)'?\)"</span>
<span class="k">print</span> <span class="nb">dict</span><span class="p">(</span><span class="n">re</span><span class="o">.</span><span class="n">findall</span><span class="p">(</span><span class="n">regex</span><span class="p">,</span> <span class="n">data</span><span class="p">))</span>
以前写过一个。。。。 haogefeifei/get_bilibili_anime · GitHub
这是MATLAB的抓取,其中api可以利用Chrome的开发者工具获得:
haogefeifei/get_bilibili_anime · GitHub
这是MATLAB的抓取,其中api可以利用Chrome的开发者工具获得:<span class="n">aid</span> <span class="p">=</span> <span class="mi">3295561</span><span class="p">;</span>
<span class="n">api</span> <span class="p">=</span> <span class="s">'http://interface.bilibili.com/count?key=b9415053057bb00966665eaa'</span><span class="p">;</span>
<span class="n">data</span> <span class="p">=</span> <span class="n">regexp</span><span class="p">(</span><span class="n">webread</span><span class="p">(</span><span class="n">api</span><span class="p">,</span><span class="s">'aid'</span><span class="p">,</span><span class="n">aid</span><span class="p">),</span><span class="s">'#(\w)+\D*(\d)+'</span><span class="p">,</span><span class="s">'tokens'</span><span class="p">);</span>
<span class="n">data</span> <span class="p">=</span> <span class="p">[</span><span class="n">data</span><span class="p">{:}]</span>
说下大概的思路。0、打开特定的av页面,通过这条语句来找到CID和AID。注意:ctrl + u中能看到的源代码就是能匹配的源代码。
1、发送请求到interface.bilibili.com/player?id=cid:(匹配的CID,要前面的冒号)&aid=(匹配的AID)
2、从获取的xml文件中找到
=====================================================
实际上,我们ctrl + u看到的页面是网站发给我们的其中一个包而已,而最终的结果页面是网站发给我们的多个包组合的结果。
有时候,网站会将数据封装在json或者xml中,然后通过多个请求获取数据,最后在本地用js来进行最后的构建。
因此,页面上看到的内容是最后的结果,如果你要判断这个结果来自于源页面还是json还是xml,就需要通过开发者工具抓抓包,然后自己分析。
总之,逻辑就是:
0、这个数据哪来的? —— 通过抓包分析
1、模拟获取这个数据的过程。 —— 直接访问该数据的来源url
当然还要注意你要传的参数。这个参数从哪些地方获取也需要自己分析。
====================================================
还是举个例子吧。
注意:B站发回的数据是gzip,然而urllib2的urlopen不会自动解压,需要手动处理。
可以参考这个回答:
Does python urllib2 automatically uncompress gzip data fetched from webpage?
随便在首页找了个页面,地址如下:
【爱深黑切】路人女主的玩坏方法~第一弹
import urllib2
import re
from StringIO import StringIO
import gzip
def find_cid_aid(html):
target = re.compile('EmbedPlayer(?P<args>.*?)</script>',re.DOTALL)
cidaid = target.search(html)
cidaid = html[cidaid.start('args'):cidaid.end('args')]
cid = cidaid.find('cid=')
aid = cidaid.find('&aid=')
index = aid
while cidaid[index] != '"':
index += 1
return (cidaid[cid + 4:aid],cidaid[aid + 5:index])
def find_how_many(cid_aid):
target = re.compile(r'<click>(?P<result>.*?)</click>',re.DOTALL)
cid = cid_aid[0]
aid = cid_aid[1]
addr = r'http://interface.bilibili.com/player?id=cid:' + cid + '&aid=' + aid
f = urllib2.urlopen(addr)
res = f.read()
target = target.search(res)
return res[target.start('result'):target.end('result')]
headers = {'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', \
'Accept-Language':'zh-cn,zh;q=0.8,en-us;q=0.5,en;q=0.3', \
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; rv:28.0) Gecko/20100101 Firefox/28.0',\
'Host':'www.bilibili.com', \
'Accept-Encoding':'gzip, deflate', \
'Cache-Control':'max-age=0', \
'Connection':'keep-alive'}
request = urllib2.Request(r'http://www.bilibili.com/video/av2046145/', headers=headers)
html = urllib2.urlopen(request)
if html.info().get('Content-Encoding') == 'gzip':
buf = StringIO(html.read())
f = gzip.GzipFile(fileobj=buf)
html = f.read()
cid_aid = find_cid_aid(html)
print find_how_many(cid_aid)
获取cid aid请求http://interface.bilibili.com/player什么东西抓抓包就知道了
比如说如图一样的懒人眼镜,你懂的~~这里的源码直接可以直接用正则匹配到cid和aid,
cid=1511100&aid=1044050
然后请求
http://interface.bilibili.com/player?id=cid:1511100&aid=1044050
然后被
<click>4611</click>
你在电脑屏幕上面看到的一切都是数据来着啊。B站的网页也只不过是一堆代码而已。稍微获取一下源代码,解gzip压缩,转换一下编码,正则表达式搜索一下,就能出来了,很简单的。

 PHP : 서버 측 스크립팅 언어 소개Apr 16, 2025 am 12:18 AM
PHP : 서버 측 스크립팅 언어 소개Apr 16, 2025 am 12:18 AMPHP는 동적 웹 개발 및 서버 측 응용 프로그램에 사용되는 서버 측 스크립팅 언어입니다. 1.PHP는 편집이 필요하지 않으며 빠른 발전에 적합한 해석 된 언어입니다. 2. PHP 코드는 HTML에 포함되어 웹 페이지를 쉽게 개발할 수 있습니다. 3. PHP는 서버 측 로직을 처리하고 HTML 출력을 생성하며 사용자 상호 작용 및 데이터 처리를 지원합니다. 4. PHP는 데이터베이스와 상호 작용하고 프로세스 양식 제출 및 서버 측 작업을 실행할 수 있습니다.
 PHP 및 웹 : 장기적인 영향 탐색Apr 16, 2025 am 12:17 AM
PHP 및 웹 : 장기적인 영향 탐색Apr 16, 2025 am 12:17 AMPHP는 지난 수십 년 동안 네트워크를 형성했으며 웹 개발에서 계속 중요한 역할을 할 것입니다. 1) PHP는 1994 년에 시작되었으며 MySQL과의 원활한 통합으로 인해 개발자에게 최초의 선택이되었습니다. 2) 핵심 기능에는 동적 컨텐츠 생성 및 데이터베이스와의 통합이 포함되며 웹 사이트를 실시간으로 업데이트하고 맞춤형 방식으로 표시 할 수 있습니다. 3) PHP의 광범위한 응용 및 생태계는 장기적인 영향을 미쳤지 만 버전 업데이트 및 보안 문제에 직면 해 있습니다. 4) PHP7의 출시와 같은 최근 몇 년간의 성능 향상을 통해 현대 언어와 경쟁 할 수 있습니다. 5) 앞으로 PHP는 컨테이너화 및 마이크로 서비스와 같은 새로운 도전을 다루어야하지만 유연성과 활발한 커뮤니티로 인해 적응력이 있습니다.
 PHP를 사용하는 이유는 무엇입니까? 설명 된 장점과 혜택Apr 16, 2025 am 12:16 AM
PHP를 사용하는 이유는 무엇입니까? 설명 된 장점과 혜택Apr 16, 2025 am 12:16 AMPHP의 핵심 이점에는 학습 용이성, 강력한 웹 개발 지원, 풍부한 라이브러리 및 프레임 워크, 고성능 및 확장 성, 크로스 플랫폼 호환성 및 비용 효율성이 포함됩니다. 1) 배우고 사용하기 쉽고 초보자에게 적합합니다. 2) 웹 서버와 우수한 통합 및 여러 데이터베이스를 지원합니다. 3) Laravel과 같은 강력한 프레임 워크가 있습니다. 4) 최적화를 통해 고성능을 달성 할 수 있습니다. 5) 여러 운영 체제 지원; 6) 개발 비용을 줄이기위한 오픈 소스.
 신화를 폭로 : PHP가 실제로 죽은 언어입니까?Apr 16, 2025 am 12:15 AM
신화를 폭로 : PHP가 실제로 죽은 언어입니까?Apr 16, 2025 am 12:15 AMPHP는 죽지 않았습니다. 1) PHP 커뮤니티는 성능 및 보안 문제를 적극적으로 해결하고 PHP7.x는 성능을 향상시킵니다. 2) PHP는 최신 웹 개발에 적합하며 대규모 웹 사이트에서 널리 사용됩니다. 3) PHP는 배우기 쉽고 서버가 잘 수행되지만 유형 시스템은 정적 언어만큼 엄격하지 않습니다. 4) PHP는 컨텐츠 관리 및 전자 상거래 분야에서 여전히 중요하며 생태계는 계속 발전하고 있습니다. 5) Opcache 및 APC를 통해 성능을 최적화하고 OOP 및 설계 패턴을 사용하여 코드 품질을 향상시킵니다.
 PHP vs. Python 토론 : 어느 것이 더 낫습니까?Apr 16, 2025 am 12:03 AM
PHP vs. Python 토론 : 어느 것이 더 낫습니까?Apr 16, 2025 am 12:03 AMPHP와 Python에는 고유 한 장점과 단점이 있으며 선택은 프로젝트 요구 사항에 따라 다릅니다. 1) PHP는 웹 개발, 배우기 쉽고 풍부한 커뮤니티 리소스에 적합하지만 구문은 현대적이지 않으며 성능과 보안에주의를 기울여야합니다. 2) Python은 간결한 구문과 배우기 쉬운 데이터 과학 및 기계 학습에 적합하지만 실행 속도 및 메모리 관리에는 병목 현상이 있습니다.
 PHP의 목적 : 동적 웹 사이트 구축Apr 15, 2025 am 12:18 AM
PHP의 목적 : 동적 웹 사이트 구축Apr 15, 2025 am 12:18 AMPHP는 동적 웹 사이트를 구축하는 데 사용되며 해당 핵심 기능에는 다음이 포함됩니다. 1. 데이터베이스와 연결하여 동적 컨텐츠를 생성하고 웹 페이지를 실시간으로 생성합니다. 2. 사용자 상호 작용 및 양식 제출을 처리하고 입력을 확인하고 작업에 응답합니다. 3. 개인화 된 경험을 제공하기 위해 세션 및 사용자 인증을 관리합니다. 4. 성능을 최적화하고 모범 사례를 따라 웹 사이트 효율성 및 보안을 개선하십시오.
 PHP : 데이터베이스 및 서버 측 로직 처리Apr 15, 2025 am 12:15 AM
PHP : 데이터베이스 및 서버 측 로직 처리Apr 15, 2025 am 12:15 AMPHP는 MySQLI 및 PDO 확장 기능을 사용하여 데이터베이스 작업 및 서버 측 로직 프로세싱에서 상호 작용하고 세션 관리와 같은 기능을 통해 서버 측로 로직을 처리합니다. 1) MySQLI 또는 PDO를 사용하여 데이터베이스에 연결하고 SQL 쿼리를 실행하십시오. 2) 세션 관리 및 기타 기능을 통해 HTTP 요청 및 사용자 상태를 처리합니다. 3) 트랜잭션을 사용하여 데이터베이스 작업의 원자력을 보장하십시오. 4) SQL 주입 방지, 디버깅을 위해 예외 처리 및 폐쇄 연결을 사용하십시오. 5) 인덱싱 및 캐시를 통해 성능을 최적화하고, 읽을 수있는 코드를 작성하고, 오류 처리를 수행하십시오.
 PHP에서 SQL 주입을 어떻게 방지합니까? (준비된 진술, pdo)Apr 15, 2025 am 12:15 AM
PHP에서 SQL 주입을 어떻게 방지합니까? (준비된 진술, pdo)Apr 15, 2025 am 12:15 AMPHP에서 전처리 문과 PDO를 사용하면 SQL 주입 공격을 효과적으로 방지 할 수 있습니다. 1) PDO를 사용하여 데이터베이스에 연결하고 오류 모드를 설정하십시오. 2) 준비 방법을 통해 전처리 명세서를 작성하고 자리 표시자를 사용하여 데이터를 전달하고 방법을 실행하십시오. 3) 쿼리 결과를 처리하고 코드의 보안 및 성능을 보장합니다.


핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

mPDF
mPDF는 UTF-8로 인코딩된 HTML에서 PDF 파일을 생성할 수 있는 PHP 라이브러리입니다. 원저자인 Ian Back은 자신의 웹 사이트에서 "즉시" PDF 파일을 출력하고 다양한 언어를 처리하기 위해 mPDF를 작성했습니다. HTML2FPDF와 같은 원본 스크립트보다 유니코드 글꼴을 사용할 때 속도가 느리고 더 큰 파일을 생성하지만 CSS 스타일 등을 지원하고 많은 개선 사항이 있습니다. RTL(아랍어, 히브리어), CJK(중국어, 일본어, 한국어)를 포함한 거의 모든 언어를 지원합니다. 중첩된 블록 수준 요소(예: P, DIV)를 지원합니다.

Eclipse용 SAP NetWeaver 서버 어댑터
Eclipse를 SAP NetWeaver 애플리케이션 서버와 통합합니다.

WebStorm Mac 버전
유용한 JavaScript 개발 도구

MinGW - Windows용 미니멀리스트 GNU
이 프로젝트는 osdn.net/projects/mingw로 마이그레이션되는 중입니다. 계속해서 그곳에서 우리를 팔로우할 수 있습니다. MinGW: GCC(GNU Compiler Collection)의 기본 Windows 포트로, 기본 Windows 애플리케이션을 구축하기 위한 무료 배포 가능 가져오기 라이브러리 및 헤더 파일로 C99 기능을 지원하는 MSVC 런타임에 대한 확장이 포함되어 있습니다. 모든 MinGW 소프트웨어는 64비트 Windows 플랫폼에서 실행될 수 있습니다.

VSCode Windows 64비트 다운로드
Microsoft에서 출시한 강력한 무료 IDE 편집기

