


1、python多进程编程背景
python中的多进程最大的好处就是充分利用多核cpu的资源,不像python中的多线程,受制于GIL的限制,从而只能进行cpu分配,在python的多进程中,适合于所有的场合,基本上能用多线程的,那么基本上就能用多进程。
在进行多进程编程的时候,其实和多线程差不多,在多线程的包threading中,存在一个线程类Thread,在其中有三种方法来创建一个线程,启动线程,其实在多进程编程中,存在一个进程类Process,也可以使用那集中方法来使用;在多线程中,内存中的数据是可以直接共享的,例如list等,但是在多进程中,内存数据是不能共享的,从而需要用单独的数据结构来处理共享的数据;在多线程中,数据共享,要保证数据的正确性,从而必须要有所,但是在多进程中,锁的考虑应该很少,因为进程是不共享内存信息的,进程之间的交互数据必须要通过特殊的数据结构,在多进程中,主要的内容如下图:
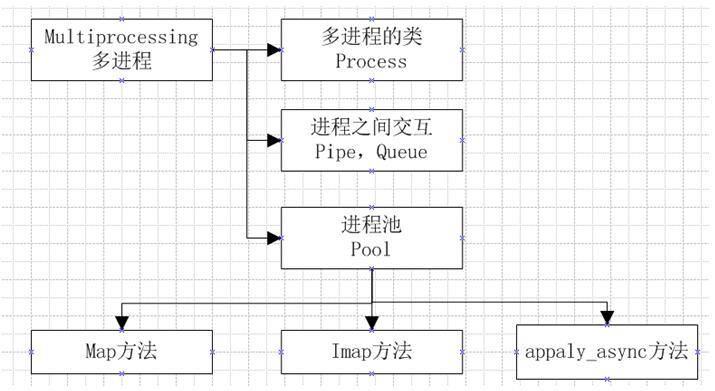
2、多进程的类Process
多进程的类Process和多线程的类Thread差不多的方法,两者的接口基本相同,具体看以下的代码:
#!/usr/bin/env python
from multiprocessing import Process
import os
import time
def func(name):
print 'start a process'
time.sleep(3)
print 'the process parent id :',os.getppid()
print 'the process id is :',os.getpid()
if __name__ =='__main__':
processes = []
for i in range(2):
p = Process(target=func,args=(i,))
processes.append(p)
for i in processes:
i.start()
print 'start all process'
for i in processes:
i.join()
#pass
print 'all sub process is done!'
在上面例子中可以看到,多进程和多线程的API接口是一样一样的,显示创建进程,然后进行start开始运行,然后join等待进程结束。
在需要执行的函数中,打印出了进程的id和pid,从而可以看到父进程和子进程的id号,在linu中,进程主要是使用fork出来的,在创建进程的时候可以查询到父进程和子进程的id号,而在多线程中是无法找到线程的id,执行效果如下:
start all process start a process start a process the process parent id : 8036 the process parent id : 8036 the process id is : 8037 the process id is : 8038 all sub process is done!
在操作系统中查询的id的时候,最好用pstree,清晰:
├─sshd(1508)─┬─sshd(2259)───bash(2261)───python(7520)─┬─python(7521)
│ │ ├─python(7522)
│ │ ├─python(7523)
│ │ ├─python(7524)
│ │ ├─python(7525)
│ │ ├─python(7526)
│ │ ├─python(7527)
│ │ ├─python(7528)
│ │ ├─python(7529)
│ │ ├─python(7530)
│ │ ├─python(7531)
│ │ └─python(7532)
在进行运行的时候,可以看到,如果没有join语句,那么主进程是不会等待子进程结束的,是一直会执行下去,然后再等待子进程的执行。
在多进程的时候,说,我怎么得到多进程的返回值呢?然后写了下面的代码:
#!/usr/bin/env python
import multiprocessing
class MyProcess(multiprocessing.Process):
def __init__(self,name,func,args):
super(MyProcess,self).__init__()
self.name = name
self.func = func
self.args = args
self.res = ''
def run(self):
self.res = self.func(*self.args)
print self.name
print self.res
return (self.res,'kel')
def func(name):
print 'start process...'
return name.upper()
if __name__ == '__main__':
processes = []
result = []
for i in range(3):
p = MyProcess('process',func,('kel',))
processes.append(p)
for i in processes:
i.start()
for i in processes:
i.join()
for i in processes:
result.append(i.res)
for i in result:
print i
尝试从结果中返回值,从而在主进程中得到子进程的返回值,然而,,,并没有结果,后来一想,在进程中,进程之间是不共享内存的 ,那么使用list来存放数据显然是不可行的,进程之间的交互必须依赖于特殊的数据结构,从而以上的代码仅仅是执行进程,不能得到进程的返回值,但是以上代码修改为线程,那么是可以得到返回值的。
3、进程间的交互Queue
进程间交互的时候,首先就可以使用在多线程里面一样的Queue结构,但是在多进程中,必须使用multiprocessing里的Queue,代码如下:
#!/usr/bin/env python
import multiprocessing
class MyProcess(multiprocessing.Process):
def __init__(self,name,func,args):
super(MyProcess,self).__init__()
self.name = name
self.func = func
self.args = args
self.res = ''
def run(self):
self.res = self.func(*self.args)
def func(name,q):
print 'start process...'
q.put(name.upper())
if __name__ == '__main__':
processes = []
q = multiprocessing.Queue()
for i in range(3):
p = MyProcess('process',func,('kel',q))
processes.append(p)
for i in processes:
i.start()
for i in processes:
i.join()
while q.qsize() > 0:
print q.get()
其实这个是上面例子的改进,在其中,并没有使用什么其他的代码,主要就是使用Queue来保存数据,从而可以达到进程间交换数据的目的。
在进行使用Queue的时候,其实用的是socket,感觉,因为在其中使用的还是发送send,然后是接收recv。
在进行数据交互的时候,其实是父进程和所有的子进程进行数据交互,所有的子进程之间基本是没有交互的,除非,但是,也是可以的,例如,每个进程去Queue中取数据,但是这个时候应该是要考虑锁,不然可能会造成数据混乱。
4、 进程之间交互Pipe
在进程之间交互数据的时候还可以使用Pipe,代码如下:
#!/usr/bin/env python
import multiprocessing
class MyProcess(multiprocessing.Process):
def __init__(self,name,func,args):
super(MyProcess,self).__init__()
self.name = name
self.func = func
self.args = args
self.res = ''
def run(self):
self.res = self.func(*self.args)
def func(name,q):
print 'start process...'
child_conn.send(name.upper())
if __name__ == '__main__':
processes = []
parent_conn,child_conn = multiprocessing.Pipe()
for i in range(3):
p = MyProcess('process',func,('kel',child_conn))
processes.append(p)
for i in processes:
i.start()
for i in processes:
i.join()
for i in processes:
print parent_conn.recv()
在以上代码中,主要是使用Pipe中返回的两个socket来进行传输和接收数据,在父进程中,使用的是parent_conn,在子进程中使用的是child_conn,从而子进程发送数据的方法send,而在父进程中进行接收方法recv
最好的地方在于,明确的知道收发的次数,但是如果某个出现异常,那么估计pipe不能使用了。
5、进程池pool
其实在使用多进程的时候,感觉使用pool是最方便的,在多线程中是不存在pool的。
在使用pool的时候,可以限制每次的进程数,也就是剩余的进程是在排队,而只有在设定的数量的进程在运行,在默认的情况下,进程是cpu的个数,也就是根据multiprocessing.cpu_count()得出的结果。
在poo中,有两个方法,一个是map一个是imap,其实这两方法超级方便,在执行结束之后,可以得到每个进程的返回结果,但是缺点就是每次的时候,只能有一个参数,也就是在执行的函数中,最多是只有一个参数的,否则,需要使用组合参数的方法,代码如下所示:
#!/usr/bin/env python
import multiprocessing
def func(name):
print 'start process'
return name.upper()
if __name__ == '__main__':
p = multiprocessing.Pool(5)
print p.map(func,['kel','smile'])
for i in p.imap(func,['kel','smile']):
print i
在使用map的时候,直接返回的一个是一个list,从而这个list也就是函数执行的结果,而在imap中,返回的是一个由结果组成的迭代器,如果需要使用多个参数的话,那么估计需要*args,从而使用参数args。
在使用apply.async的时候,可以直接使用多个参数,如下所示:
#!/usr/bin/env python
import multiprocessing
import time
def func(name):
print 'start process'
time.sleep(2)
return name.upper()
if __name__ == '__main__':
results = []
p = multiprocessing.Pool(5)
for i in range(7):
res = p.apply_async(func,args=('kel',))
results.append(res)
for i in results:
print i.get(2.1)
在进行得到各个结果的时候,注意使用了一个list来进行append,要不然在得到结果get的时候会阻塞进程,从而将多进程编程了单进程,从而使用了一个list来存放相关的结果,在进行得到get数据的时候,可以设置超时时间,也就是get(timeout=5),这种设置。
总结:
在进行多进程编程的时候,注意进程之间的交互,在执行函数之后,如何得到执行函数的结果,可以使用特殊的数据结构,例如Queue或者Pipe或者其他,在使用pool的时候,可以直接得到结果,map和imap都是直接得到一个list和可迭代对象,而apply_async得到的结果需要用一个list装起来,然后得到每个结果。
以上这篇深入理解python多进程编程就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持脚本之家。

 Python vs. C : 주요 차이점 이해Apr 21, 2025 am 12:18 AM
Python vs. C : 주요 차이점 이해Apr 21, 2025 am 12:18 AMPython과 C는 각각 고유 한 장점이 있으며 선택은 프로젝트 요구 사항을 기반으로해야합니다. 1) Python은 간결한 구문 및 동적 타이핑으로 인해 빠른 개발 및 데이터 처리에 적합합니다. 2) C는 정적 타이핑 및 수동 메모리 관리로 인해 고성능 및 시스템 프로그래밍에 적합합니다.
 Python vs. C : 프로젝트를 위해 어떤 언어를 선택해야합니까?Apr 21, 2025 am 12:17 AM
Python vs. C : 프로젝트를 위해 어떤 언어를 선택해야합니까?Apr 21, 2025 am 12:17 AMPython 또는 C를 선택하는 것은 프로젝트 요구 사항에 따라 다릅니다. 1) 빠른 개발, 데이터 처리 및 프로토 타입 설계가 필요한 경우 Python을 선택하십시오. 2) 고성능, 낮은 대기 시간 및 근접 하드웨어 제어가 필요한 경우 C를 선택하십시오.
 파이썬 목표에 도달 : 매일 2 시간의 힘Apr 20, 2025 am 12:21 AM
파이썬 목표에 도달 : 매일 2 시간의 힘Apr 20, 2025 am 12:21 AM매일 2 시간의 파이썬 학습을 투자하면 프로그래밍 기술을 효과적으로 향상시킬 수 있습니다. 1. 새로운 지식 배우기 : 문서를 읽거나 자습서를 시청하십시오. 2. 연습 : 코드를 작성하고 완전한 연습을합니다. 3. 검토 : 배운 내용을 통합하십시오. 4. 프로젝트 실무 : 실제 프로젝트에서 배운 것을 적용하십시오. 이러한 구조화 된 학습 계획은 파이썬을 체계적으로 마스터하고 경력 목표를 달성하는 데 도움이 될 수 있습니다.
 2 시간 극대화 : 효과적인 파이썬 학습 전략Apr 20, 2025 am 12:20 AM
2 시간 극대화 : 효과적인 파이썬 학습 전략Apr 20, 2025 am 12:20 AM2 시간 이내에 Python을 효율적으로 학습하는 방법 : 1. 기본 지식을 검토하고 Python 설치 및 기본 구문에 익숙한 지 확인하십시오. 2. 변수, 목록, 기능 등과 같은 파이썬의 핵심 개념을 이해합니다. 3. 예제를 사용하여 마스터 기본 및 고급 사용; 4. 일반적인 오류 및 디버깅 기술을 배우십시오. 5. 목록 이해력 사용 및 PEP8 스타일 안내서와 같은 성능 최적화 및 모범 사례를 적용합니다.
 Python과 C : The Hight Language 중에서 선택Apr 20, 2025 am 12:20 AM
Python과 C : The Hight Language 중에서 선택Apr 20, 2025 am 12:20 AMPython은 초보자 및 데이터 과학에 적합하며 C는 시스템 프로그래밍 및 게임 개발에 적합합니다. 1. 파이썬은 간단하고 사용하기 쉽고 데이터 과학 및 웹 개발에 적합합니다. 2.C는 게임 개발 및 시스템 프로그래밍에 적합한 고성능 및 제어를 제공합니다. 선택은 프로젝트 요구와 개인적인 이익을 기반으로해야합니다.
 Python vs. C : 프로그래밍 언어의 비교 분석Apr 20, 2025 am 12:14 AM
Python vs. C : 프로그래밍 언어의 비교 분석Apr 20, 2025 am 12:14 AMPython은 데이터 과학 및 빠른 개발에 더 적합한 반면 C는 고성능 및 시스템 프로그래밍에 더 적합합니다. 1. Python Syntax는 간결하고 학습하기 쉽고 데이터 처리 및 과학 컴퓨팅에 적합합니다. 2.C는 복잡한 구문을 가지고 있지만 성능이 뛰어나고 게임 개발 및 시스템 프로그래밍에 종종 사용됩니다.
 하루 2 시간 : 파이썬 학습의 잠재력Apr 20, 2025 am 12:14 AM
하루 2 시간 : 파이썬 학습의 잠재력Apr 20, 2025 am 12:14 AM파이썬을 배우기 위해 하루에 2 시간을 투자하는 것이 가능합니다. 1. 새로운 지식 배우기 : 목록 및 사전과 같은 1 시간 안에 새로운 개념을 배우십시오. 2. 연습 및 연습 : 1 시간을 사용하여 소규모 프로그램 작성과 같은 프로그래밍 연습을 수행하십시오. 합리적인 계획과 인내를 통해 짧은 시간에 Python의 핵심 개념을 마스터 할 수 있습니다.
 Python vs. C : 학습 곡선 및 사용 편의성Apr 19, 2025 am 12:20 AM
Python vs. C : 학습 곡선 및 사용 편의성Apr 19, 2025 am 12:20 AMPython은 배우고 사용하기 쉽고 C는 더 강력하지만 복잡합니다. 1. Python Syntax는 간결하며 초보자에게 적합합니다. 동적 타이핑 및 자동 메모리 관리를 사용하면 사용하기 쉽지만 런타임 오류가 발생할 수 있습니다. 2.C는 고성능 응용 프로그램에 적합한 저수준 제어 및 고급 기능을 제공하지만 학습 임계 값이 높고 수동 메모리 및 유형 안전 관리가 필요합니다.


핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

에디트플러스 중국어 크랙 버전
작은 크기, 구문 강조, 코드 프롬프트 기능을 지원하지 않음

ZendStudio 13.5.1 맥
강력한 PHP 통합 개발 환경

DVWA
DVWA(Damn Vulnerable Web App)는 매우 취약한 PHP/MySQL 웹 애플리케이션입니다. 주요 목표는 보안 전문가가 법적 환경에서 자신의 기술과 도구를 테스트하고, 웹 개발자가 웹 응용 프로그램 보안 프로세스를 더 잘 이해할 수 있도록 돕고, 교사/학생이 교실 환경 웹 응용 프로그램에서 가르치고 배울 수 있도록 돕는 것입니다. 보안. DVWA의 목표는 다양한 난이도의 간단하고 간단한 인터페이스를 통해 가장 일반적인 웹 취약점 중 일부를 연습하는 것입니다. 이 소프트웨어는

맨티스BT
Mantis는 제품 결함 추적을 돕기 위해 설계된 배포하기 쉬운 웹 기반 결함 추적 도구입니다. PHP, MySQL 및 웹 서버가 필요합니다. 데모 및 호스팅 서비스를 확인해 보세요.

mPDF
mPDF는 UTF-8로 인코딩된 HTML에서 PDF 파일을 생성할 수 있는 PHP 라이브러리입니다. 원저자인 Ian Back은 자신의 웹 사이트에서 "즉시" PDF 파일을 출력하고 다양한 언어를 처리하기 위해 mPDF를 작성했습니다. HTML2FPDF와 같은 원본 스크립트보다 유니코드 글꼴을 사용할 때 속도가 느리고 더 큰 파일을 생성하지만 CSS 스타일 등을 지원하고 많은 개선 사항이 있습니다. RTL(아랍어, 히브리어), CJK(중국어, 일본어, 한국어)를 포함한 거의 모든 언어를 지원합니다. 중첩된 블록 수준 요소(예: P, DIV)를 지원합니다.

