


# -*- coding: utf8 -*-
#! python
print(repr("测试报警,xxxx是大猪头".decode("UTF8").encode("GBK")).replace("\\x","%"))
注意第一个 decode("UTF8") 要与文件声明的编码一样。
最开始对这个问题的接触,来自于一个Javascript解谜闯关的小游戏,某一关的提示如下:
刚开始的几关都是很简单很简单的哦~~这一关只是简单的字符串变形而已…..
后面是一大长串开头是%5Cu4e0b%5Cu4e00%5Cu5173%5Cu7684这样的字符串。
这种东西以前经常在浏览器的地址栏见到,就是一直不知道怎么转换成能看懂的东东,
网上google了一下,结合python的url解码和unicode解码,解决方式如下:
import urllib escaped_str="%5Cu4e0b%5Cu4e00%5Cu5173%5Cu7684%5Cu9875%5Cu9762%5Cu540d%5Cu5b57%5Cu662f%5Cx20%5Cx69%5Cx32%5Cx6a%5Cx62%5Cx6a%5Cx33%5Cx69%5Cx34%5Cx62%5Cx62%5Cx35%5Cx34%5Cx62%5Cx35%5Cx32%5Cx69%5Cx62%5Cx33%5Cx2e%5Cx68%5Cx74%5Cx6d"
print urllib.unquote(escaped_str).decode('unicode-escape')
最近,我对firefox的autoproxy插件中的gfwlist中的中文词汇(用过代理的同学们,你们懂的)产生了兴趣,然而这些网址都是用url编码的,比如http://zh.wikipedia.org/wiki/%E9%97%A8,需要使用正则表达式将被url编码的中文字符提取出来,写了个小脚本如下:
import urllib
import re
with open("listfile","r") as f:
for url_str in f:
match=re.compile("((%\w{2}){3,})").findall(url_str)
#汉字url编码的样式是:百分号+2个十六进制数,重复3次
if match!=None:
#如果匹配成功,则将提取出的部分转换为中文
for trans in match:
print urllib.unquote(trans[0]),
然而这个脚本仍有一些缺点,对于列表文件中的某些中文字符仍然不能正常解码,比如下面这几行测试代码
import urllib
a="http://zh.wikipedia.org/wiki/%BD%F0%B6"
b="http://zh.wikipedia.org/wiki/%E9%97%A8"
de=urllib.unquote
print de(a),de(b)
输出结果就是前者可以正确解码,而后者不可以,个人觉得原因可能和big5编码有关,如果谁知道什么解决办法,还请告诉我一下~
以下是补充:
de(a).decode(“gbk”,”ignore”)
de(b).decode(“utf8″,”ignore”)
這樣你可以得到這些字串的unicode編碼。
你用的unquote不是decoder, 你需要作必要的decode和encode。我一直用utf8作我默認環境的,我覺得你大概用的gbk吧,所以後者的解碼你那邊失敗了。猜編碼是很累的事情,如果大家都用utf8倒也好,但是有些人習慣了gb。
http://yac163.svn.sourceforge.net/viewvc/yac163/trunk/yac163-nox/Pic.py?revision=198&view=markup
參考我這個很古老code裡面的#102-147行 給每個decode和encode調用加上(…,”ignore”)。
def strdecode( string,charset=None ):
if isinstance(string,unicode):
return string
if charset:
try:
return string.decode(charset)
except UnicodeDecodeError:
return _strdecode(string)
else:
return _strdecode(string)
def _strdecode(string):
try:
return string.decode('utf8')
except UnicodeDecodeError:
try:
return string.decode('gb2312')
except UnicodeDecodeError:
try:
return string.decode('gbk')
except UnicodeDecodeError:
return string.decode('gb18030')
def strencode( string,charset=None ):
if isinstance(string,str):
return string
if charset:
try:
return string.encode(charset)
except UnicodeEncodeError:
return _strencode(string)
else:
return _strencode(string)
def _strencode(string):
try:
return string.encode('utf8')
except UnicodeEncodeError:
try:
return string.encode('gb2312')
except UnicodeEncodeError:
try:
return string.encode('gbk')
except UnicodeEncodeError:
return string.encode('gb18030')

 PHP函数介绍—get_headers(): 获取URL的响应头信息Jul 25, 2023 am 09:05 AM
PHP函数介绍—get_headers(): 获取URL的响应头信息Jul 25, 2023 am 09:05 AMPHP函数介绍—get_headers():获取URL的响应头信息概述:在PHP开发中,我们经常需要获取网页或远程资源的响应头信息。PHP函数get_headers()能够方便地获取目标URL的响应头信息,并以数组形式返回。本文将介绍get_headers()函数的用法,以及提供一些相关的代码示例。get_headers()函数的用法:get_header
 为什么NameResolutionError(self.host, self, e) from e,怎么解决Mar 01, 2024 pm 01:20 PM
为什么NameResolutionError(self.host, self, e) from e,怎么解决Mar 01, 2024 pm 01:20 PM报错的原因NameResolutionError(self.host,self,e)frome是由urllib3库中的异常类型,这个错误的原因是DNS解析失败,也就是说,试图解析的主机名或IP地址无法找到。这可能是由于输入的URL地址不正确,或者DNS服务器暂时不可用导致的。如何解决解决此错误的方法可能有以下几种:检查输入的URL地址是否正确,确保它是可访问的确保DNS服务器可用,您可以尝试在命令行中使用"ping"命令来测试DNS服务器是否可用尝试使用IP地址而不是主机名来访问网站如果是在代理
 怎样透过几个步骤获取您的 Steam ID?May 08, 2023 pm 11:43 PM
怎样透过几个步骤获取您的 Steam ID?May 08, 2023 pm 11:43 PM现在很多热爱游戏的windows用户都进入了Steam客户端,可以搜索、下载和玩任何好游戏。但是,许多用户的个人资料可能具有完全相同的名称,这使得查找个人资料或什至将Steam个人资料链接到其他第三方帐户或加入Steam论坛以共享内容变得困难。为配置文件分配了一个唯一的17位id,它保持不变,用户无法随时更改,而用户名或自定义URL可以更改。无论如何,一些用户并不知道他们的Steamid,这对于了解这一点非常重要。如果您也不知道如何找到您帐户的Steamid,请不要惊慌。在这篇文
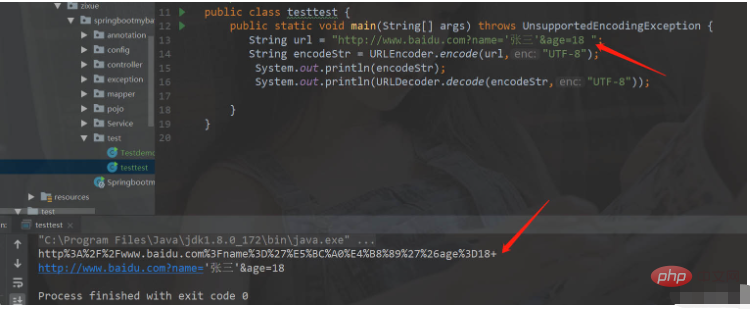 如何在Java中使用URL编码和解码May 08, 2023 pm 05:46 PM
如何在Java中使用URL编码和解码May 08, 2023 pm 05:46 PM使用url进行编码和解码编码和解码的类java.net.URLDecoder.decode(url,解码格式)解码器.解码方法。转化成普通字符串,URLEncoder.decode(url,编码格式)将普通字符串变成指定格式的字符串packagecom.zixue.springbootmybatis.test;importjava.io.UnsupportedEncodingException;importjava.net.URLDecoder;importjava.net.URLEncoder
 html和url的区别是什么Mar 06, 2024 pm 03:06 PM
html和url的区别是什么Mar 06, 2024 pm 03:06 PM区别:1、定义不同,url是是统一资源定位符,而html是超文本标记语言;2、一个html中可以有很多个url,而一个url中只能存在一个html页面;3、html指的是网页,而url指的是网站地址。
 Scrapy优化技巧:如何减少重复URL的爬取,提高效率Jun 22, 2023 pm 01:57 PM
Scrapy优化技巧:如何减少重复URL的爬取,提高效率Jun 22, 2023 pm 01:57 PMScrapy是一个功能强大的Python爬虫框架,可以用于从互联网上获取大量的数据。但是,在进行Scrapy开发时,经常会遇到重复URL的爬取问题,这会浪费大量的时间和资源,影响效率。本文将介绍一些Scrapy优化技巧,以减少重复URL的爬取,提高Scrapy爬虫的效率。一、使用start_urls和allowed_domains属性在Scrapy爬虫中,可
 SpringBoot多controller如何添加URL前缀May 12, 2023 pm 06:37 PM
SpringBoot多controller如何添加URL前缀May 12, 2023 pm 06:37 PM前言在某些情况下,服务的controller中前缀是一致的,例如所有URL的前缀都为/context-path/api/v1,需要为某些URL添加统一的前缀。能想到的处理办法为修改服务的context-path,在context-path中添加api/v1,这样修改全局的前缀能够解决上面的问题,但存在弊端,如果URL存在多个前缀,例如有些URL需要前缀为api/v2,就无法区分了,如果服务中的一些静态资源不想添加api/v1,也无法区分。下面通过自定义注解的方式实现某些URL前缀的统一添加。一、
 url是啥意思Aug 04, 2023 am 11:43 AM
url是啥意思Aug 04, 2023 am 11:43 AMurl是“Uniform Resource Locator”的缩写,中文意为“统一资源定位符”。URL是通过互联网来定位和访问特定资源的地址,常见于网页浏览和HTTP请求中。URL的主要作用是定位和访问互联网上的资源,这些资源可以是网页、图片、视频、文档或其他文件。


핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

Dreamweaver Mac版
시각적 웹 개발 도구

DVWA
DVWA(Damn Vulnerable Web App)는 매우 취약한 PHP/MySQL 웹 애플리케이션입니다. 주요 목표는 보안 전문가가 법적 환경에서 자신의 기술과 도구를 테스트하고, 웹 개발자가 웹 응용 프로그램 보안 프로세스를 더 잘 이해할 수 있도록 돕고, 교사/학생이 교실 환경 웹 응용 프로그램에서 가르치고 배울 수 있도록 돕는 것입니다. 보안. DVWA의 목표는 다양한 난이도의 간단하고 간단한 인터페이스를 통해 가장 일반적인 웹 취약점 중 일부를 연습하는 것입니다. 이 소프트웨어는

드림위버 CS6
시각적 웹 개발 도구

에디트플러스 중국어 크랙 버전
작은 크기, 구문 강조, 코드 프롬프트 기능을 지원하지 않음

SublimeText3 Linux 새 버전
SublimeText3 Linux 최신 버전
뜨거운 주제
 1371
1371 523919
523919