


redis实现点击量浏览量
业务描述
CMS文章浏览量(标题被加载量),点击量统计(文章被点击开的量)
以下是本人设计的统计业务,主要技术redis,nodejs,redis应用点击量缓存以减少数据库压力,nodejs通过异步非阻塞机制实现CMS业务逻辑和统计功能区分
传入参数cateid(分类id),articleid(文章id),sourceip(请求源ip)
一、存储策略
1、按时间粒度记录
redis以hash进行存储
HASH
KEY VALUE
time his
0 0
1 10
cateid_arvicleid_t . .
. .
. .
23 230
2、按来源统计
redis同样以hash进行存储,来源区分到省份
HASH
KEY VALUE
provinc his
HEBEI 0
HENAN 10
cateid_arvicleid_p . .
. .
. .
SHANDONG 230
二、数据同步机制
现在只想到通过linux计划任务定时将redis数据同步到数据库
三、缓存数据过期机制
方案一 通过redis自动过期时间
此方案需要在数据同步机制晚一些执行,保证数据入库后,清理过期缓存,现在考虑同步在每日0时执行,那么redis缓存就需要设置24小时多一点
方案二 通过数据库同步机制同时清除
此方案即把同步和清理缓存做在一起,弃用redis过期机制
小弟希望各位大神给指出不妥和优化的地方
在10000在线用户,1000并发的基础上上述redis的存储机制对内存压力是否可行
同步机制和缓存过期机制是否有更好的解决的方案
在此拜谢
------解决思路----------------------
KEY 最好设置成 2014_10_30. cateid_arvicleid_t形式
选择方案二 通过数据库同步机制同时清除 在每天凌晨的2~4点进行同步 因为脚本1.同步脚本可能失败 2.数据量大的时候昨天的0时数据会被今天的0时覆盖
号称1秒10W请求的redis 不惧1000的并发

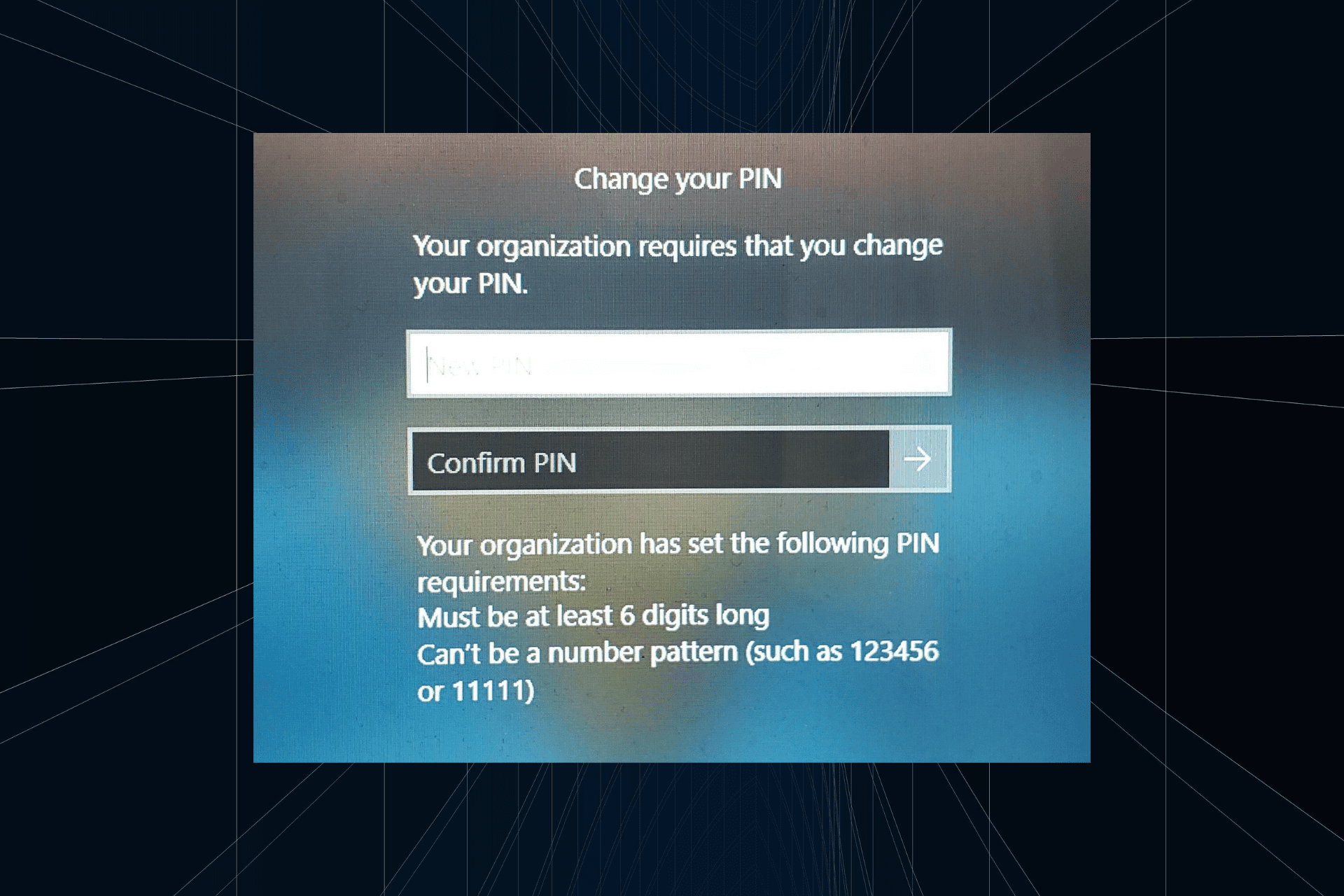 解决方法:您的组织要求您更改 PIN 码Oct 04, 2023 pm 05:45 PM
解决方法:您的组织要求您更改 PIN 码Oct 04, 2023 pm 05:45 PM“你的组织要求你更改PIN消息”将显示在登录屏幕上。当在使用基于组织的帐户设置的电脑上达到PIN过期限制时,就会发生这种情况,在该电脑上,他们可以控制个人设备。但是,如果您使用个人帐户设置了Windows,则理想情况下不应显示错误消息。虽然情况并非总是如此。大多数遇到错误的用户使用个人帐户报告。为什么我的组织要求我在Windows11上更改我的PIN?可能是您的帐户与组织相关联,您的主要方法应该是验证这一点。联系域管理员会有所帮助!此外,配置错误的本地策略设置或不正确的注册表项也可能导致错误。即
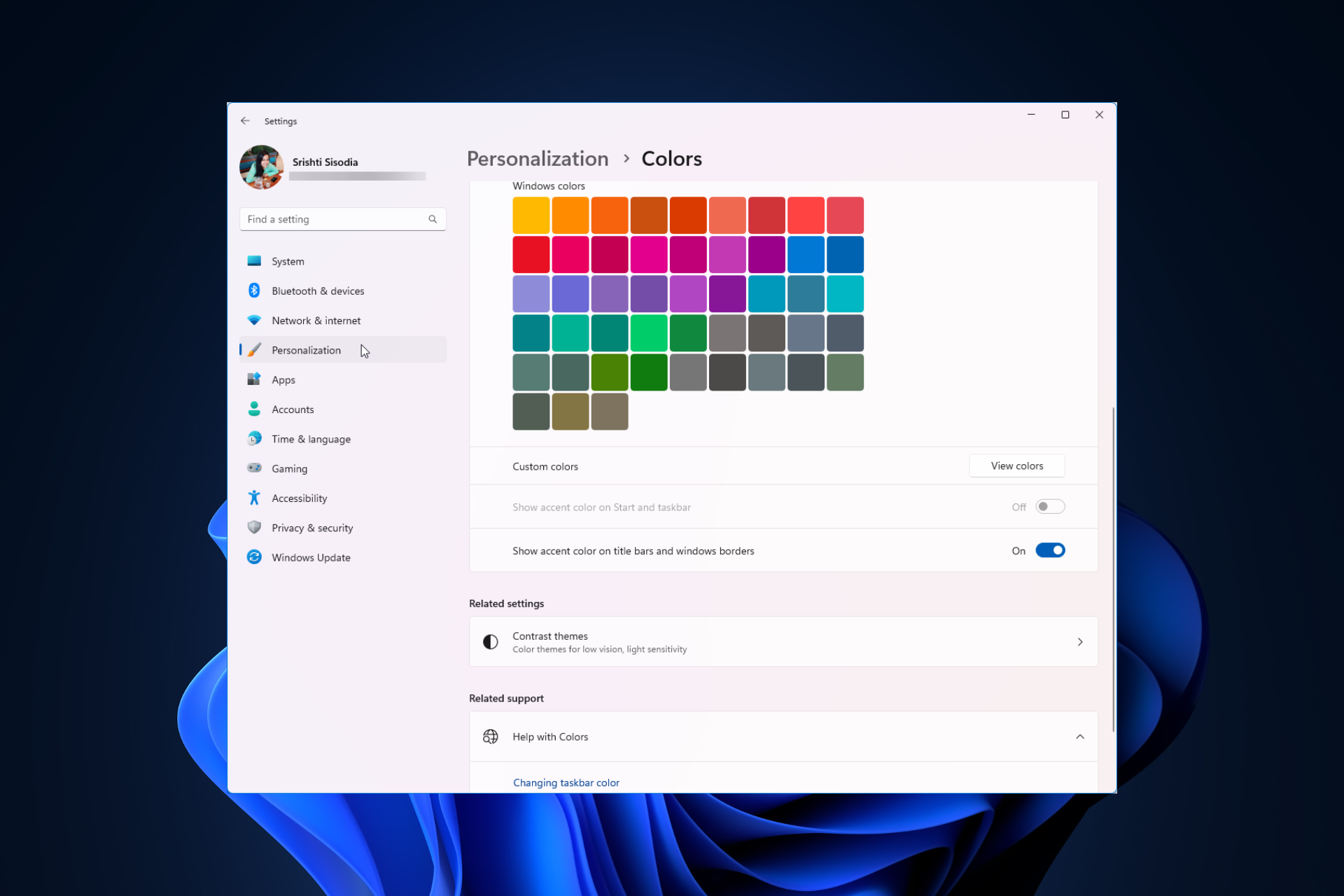 Windows 11 上调整窗口边框设置的方法:更改颜色和大小Sep 22, 2023 am 11:37 AM
Windows 11 上调整窗口边框设置的方法:更改颜色和大小Sep 22, 2023 am 11:37 AMWindows11将清新优雅的设计带到了最前沿;现代界面允许您个性化和更改最精细的细节,例如窗口边框。在本指南中,我们将讨论分步说明,以帮助您在Windows操作系统中创建反映您的风格的环境。如何更改窗口边框设置?按+打开“设置”应用。WindowsI转到个性化,然后单击颜色设置。颜色更改窗口边框设置窗口11“宽度=”643“高度=”500“>找到在标题栏和窗口边框上显示强调色选项,然后切换它旁边的开关。若要在“开始”菜单和任务栏上显示主题色,请打开“在开始”菜单和任务栏上显示主题
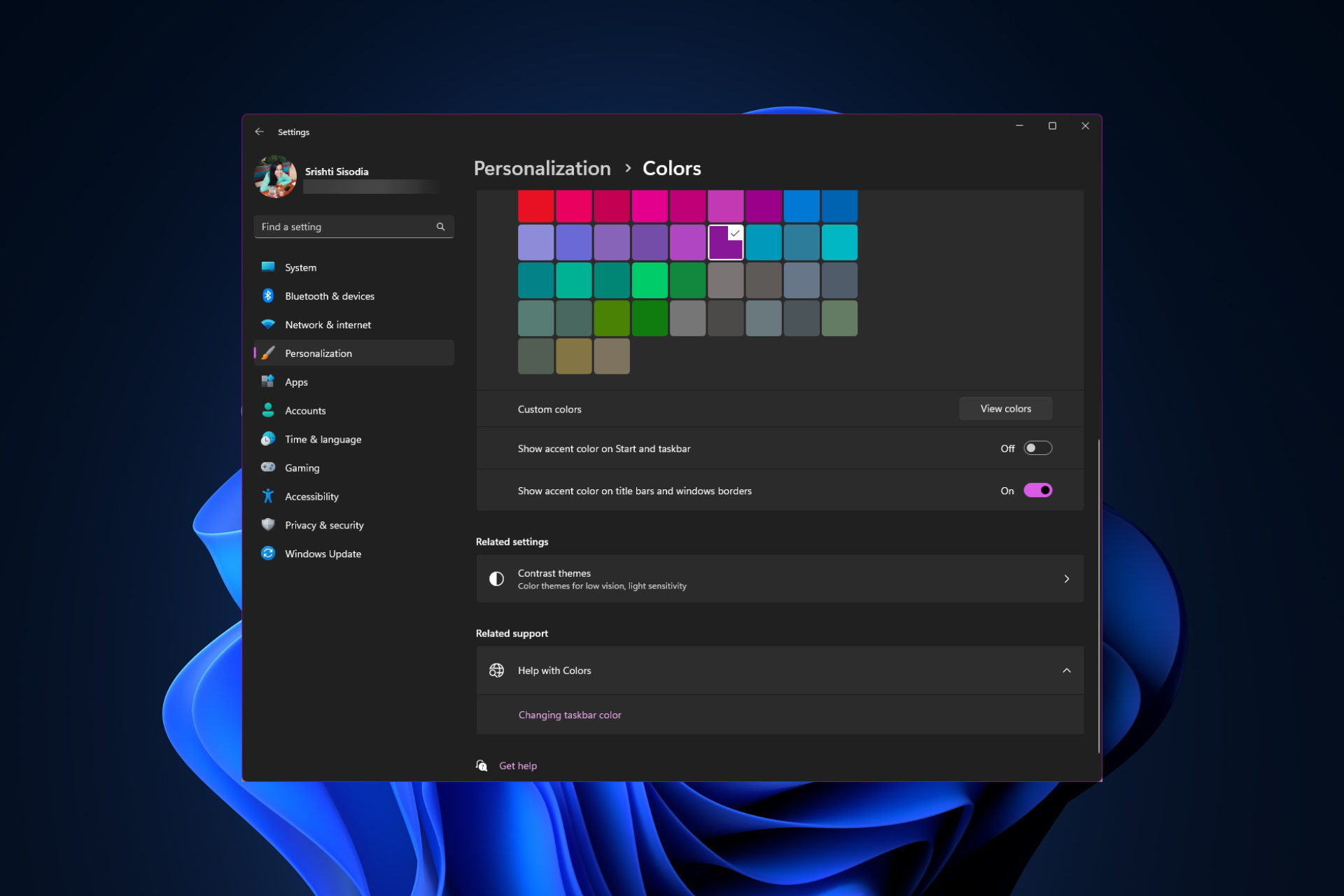 如何在 Windows 11 上更改标题栏颜色?Sep 14, 2023 pm 03:33 PM
如何在 Windows 11 上更改标题栏颜色?Sep 14, 2023 pm 03:33 PM默认情况下,Windows11上的标题栏颜色取决于您选择的深色/浅色主题。但是,您可以将其更改为所需的任何颜色。在本指南中,我们将讨论三种方法的分步说明,以更改它并个性化您的桌面体验,使其具有视觉吸引力。是否可以更改活动和非活动窗口的标题栏颜色?是的,您可以使用“设置”应用更改活动窗口的标题栏颜色,也可以使用注册表编辑器更改非活动窗口的标题栏颜色。若要了解这些步骤,请转到下一部分。如何在Windows11中更改标题栏的颜色?1.使用“设置”应用按+打开设置窗口。WindowsI前往“个性化”,然
 OOBELANGUAGE错误Windows 11 / 10修复中出现问题的问题Jul 16, 2023 pm 03:29 PM
OOBELANGUAGE错误Windows 11 / 10修复中出现问题的问题Jul 16, 2023 pm 03:29 PM您是否在Windows安装程序页面上看到“出现问题”以及“OOBELANGUAGE”语句?Windows的安装有时会因此类错误而停止。OOBE表示开箱即用的体验。正如错误提示所表示的那样,这是与OOBE语言选择相关的问题。没有什么可担心的,你可以通过OOBE屏幕本身的漂亮注册表编辑来解决这个问题。快速修复–1.单击OOBE应用底部的“重试”按钮。这将继续进行该过程,而不会再打嗝。2.使用电源按钮强制关闭系统。系统重新启动后,OOBE应继续。3.断开系统与互联网的连接。在脱机模式下完成OOBE的所
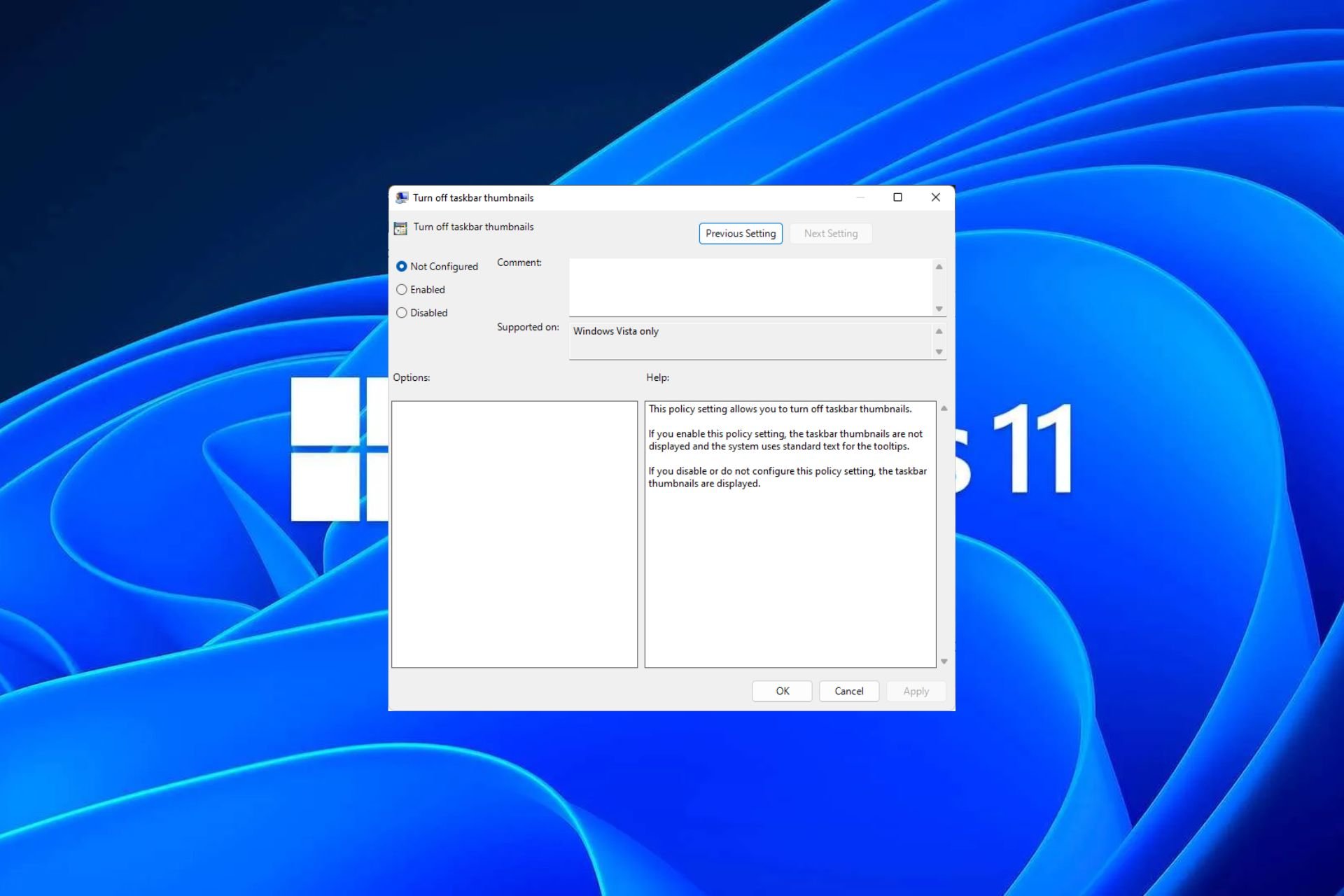 Windows 11 上启用或禁用任务栏缩略图预览的方法Sep 15, 2023 pm 03:57 PM
Windows 11 上启用或禁用任务栏缩略图预览的方法Sep 15, 2023 pm 03:57 PM任务栏缩略图可能很有趣,但它们也可能分散注意力或烦人。考虑到您将鼠标悬停在该区域的频率,您可能无意中关闭了重要窗口几次。另一个缺点是它使用更多的系统资源,因此,如果您一直在寻找一种提高资源效率的方法,我们将向您展示如何禁用它。不过,如果您的硬件规格可以处理它并且您喜欢预览版,则可以启用它。如何在Windows11中启用任务栏缩略图预览?1.使用“设置”应用点击键并单击设置。Windows单击系统,然后选择关于。点击高级系统设置。导航到“高级”选项卡,然后选择“性能”下的“设置”。在“视觉效果”选
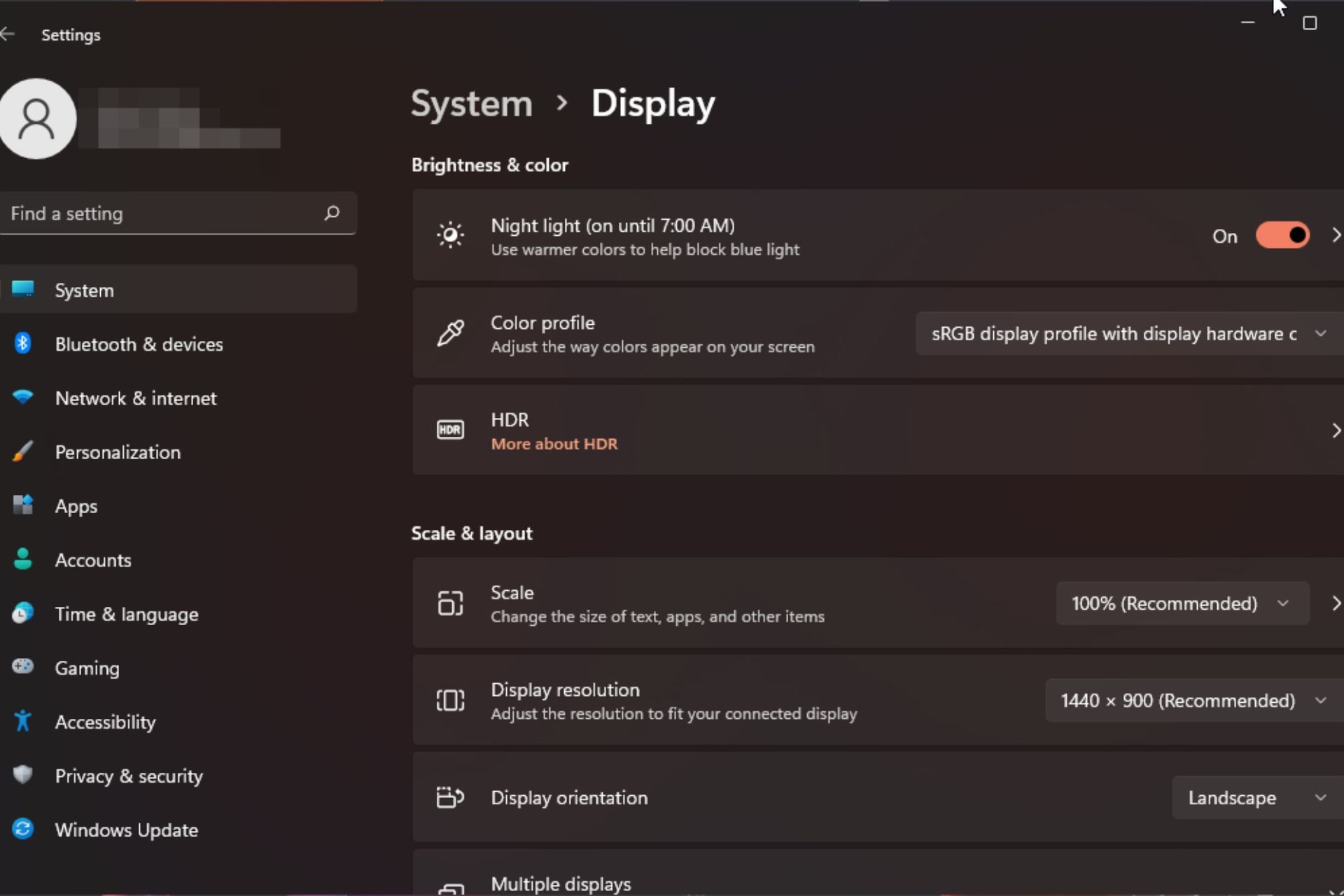 Windows 11 上的显示缩放比例调整指南Sep 19, 2023 pm 06:45 PM
Windows 11 上的显示缩放比例调整指南Sep 19, 2023 pm 06:45 PM在Windows11上的显示缩放方面,我们都有不同的偏好。有些人喜欢大图标,有些人喜欢小图标。但是,我们都同意拥有正确的缩放比例很重要。字体缩放不良或图像过度缩放可能是工作时真正的生产力杀手,因此您需要知道如何对其进行自定义以充分利用系统功能。自定义缩放的优点:对于难以阅读屏幕上的文本的人来说,这是一个有用的功能。它可以帮助您一次在屏幕上查看更多内容。您可以创建仅适用于某些监视器和应用程序的自定义扩展配置文件。可以帮助提高低端硬件的性能。它使您可以更好地控制屏幕上的内容。如何在Windows11
 10种在 Windows 11 上调整亮度的方法Dec 18, 2023 pm 02:21 PM
10种在 Windows 11 上调整亮度的方法Dec 18, 2023 pm 02:21 PM屏幕亮度是使用现代计算设备不可或缺的一部分,尤其是当您长时间注视屏幕时。它可以帮助您减轻眼睛疲劳,提高易读性,并轻松有效地查看内容。但是,根据您的设置,有时很难管理亮度,尤其是在具有新UI更改的Windows11上。如果您在调整亮度时遇到问题,以下是在Windows11上管理亮度的所有方法。如何在Windows11上更改亮度[10种方式解释]单显示器用户可以使用以下方法在Windows11上调整亮度。这包括使用单个显示器的台式机系统以及笔记本电脑。让我们开始吧。方法1:使用操作中心操作中心是访问
 如何在Safari中关闭iPhone的隐私浏览身份验证?Nov 29, 2023 pm 11:21 PM
如何在Safari中关闭iPhone的隐私浏览身份验证?Nov 29, 2023 pm 11:21 PM在iOS17中,Apple为其移动操作系统引入了几项新的隐私和安全功能,其中之一是能够要求对Safari中的隐私浏览选项卡进行二次身份验证。以下是它的工作原理以及如何将其关闭。在运行iOS17或iPadOS17的iPhone或iPad上,如果您在Safari浏览器中打开了任何“无痕浏览”标签页,然后退出会话或App,Apple的浏览器现在需要面容ID/触控ID认证或密码才能再次访问它们。换句话说,如果有人在解锁您的iPhone或iPad时拿到了它,他们仍然无法在不知道您的密码的情况下查看您的隐私


핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

PhpStorm 맥 버전
최신(2018.2.1) 전문 PHP 통합 개발 도구

Dreamweaver Mac版
시각적 웹 개발 도구

SecList
SecLists는 최고의 보안 테스터의 동반자입니다. 보안 평가 시 자주 사용되는 다양한 유형의 목록을 한 곳에 모아 놓은 것입니다. SecLists는 보안 테스터에게 필요할 수 있는 모든 목록을 편리하게 제공하여 보안 테스트를 더욱 효율적이고 생산적으로 만드는 데 도움이 됩니다. 목록 유형에는 사용자 이름, 비밀번호, URL, 퍼징 페이로드, 민감한 데이터 패턴, 웹 셸 등이 포함됩니다. 테스터는 이 저장소를 새로운 테스트 시스템으로 간단히 가져올 수 있으며 필요한 모든 유형의 목록에 액세스할 수 있습니다.

DVWA
DVWA(Damn Vulnerable Web App)는 매우 취약한 PHP/MySQL 웹 애플리케이션입니다. 주요 목표는 보안 전문가가 법적 환경에서 자신의 기술과 도구를 테스트하고, 웹 개발자가 웹 응용 프로그램 보안 프로세스를 더 잘 이해할 수 있도록 돕고, 교사/학생이 교실 환경 웹 응용 프로그램에서 가르치고 배울 수 있도록 돕는 것입니다. 보안. DVWA의 목표는 다양한 난이도의 간단하고 간단한 인터페이스를 통해 가장 일반적인 웹 취약점 중 일부를 연습하는 것입니다. 이 소프트웨어는

MinGW - Windows용 미니멀리스트 GNU
이 프로젝트는 osdn.net/projects/mingw로 마이그레이션되는 중입니다. 계속해서 그곳에서 우리를 팔로우할 수 있습니다. MinGW: GCC(GNU Compiler Collection)의 기본 Windows 포트로, 기본 Windows 애플리케이션을 구축하기 위한 무료 배포 가능 가져오기 라이브러리 및 헤더 파일로 C99 기능을 지원하는 MSVC 런타임에 대한 확장이 포함되어 있습니다. 모든 MinGW 소프트웨어는 64비트 Windows 플랫폼에서 실행될 수 있습니다.

