
프로토타입 소스 코드 열거 가능 부분에 대한 간략한 분석(2)_prototype

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB원래의
- 2016-05-16 17:56:491057검색
앞서 각 메소드에서 언급하지 않은 측면이 하나 있는데, 소스 코드의 $break 및 $continue 입니다. 이 두 변수는 미리 정의되어 있으며 해당 기능은 일반 루프의 break 및 continue 문과 동일합니다. 효율성상의 이유로 일부 작업에서는 컬렉션(배열에 국한되지 않음)을 완전히 순회할 필요가 없으므로 중단 및 계속이 여전히 필요합니다.
루프의 경우 루프를 종료하는 다음 방법을 비교하세요.
코드 복사 코드는 다음과 같습니다.
var array_1 = [1,2,3]
var array_2 = ['a','b','c']
(function(){
for( var i = 0, len = array_1.length; i for(var j = 0, len_j = array_1.length; i if( 'c' === array_2[j]){
break;
}
console.log(array_2[j])
}
}
})(); // a,b,a,b,a,b
(function(){
for(var i = 0, len = array_1.length; i try{
for(var j = 0, len_j = array_1.length; i < len_j; j ){
if('c' === array_2[j]){
throw new Error();
}
console.log(array_2[j]);
}
}catch(e){
console.log('한 단계의 루프 종료')
}
}
})();//a,b,'한 레벨의 루프 종료',a,b,'한 레벨의 루프 종료',a,b,'한 레벨의 루프 종료'
(function() {
try{
for(var i = 0, len = array_1.length; i < len; i ){
for(var j = 0, len_j = array_1. length; i < len_j ; j ){
if('c' === array_2[j]){
thor new Error()
}
console.log(array_2[j ]);
}
}
}catch(e){
console.log('한 단계의 루프 종료')
}
})(); a,b,'루프 한 레벨 종료' 레이어 루프'
해당 루프 레벨에 에러 트랩핑을 넣으면 해당 루프를 중단할 수 있습니다. break 및 break 라벨(goto) 기능을 실현할 수 있습니다. 이러한 애플리케이션 요구 사항 중 하나는 인터럽트를 외부로 이동할 수 있다는 것이며 이는 Enumerable의 요구 사항을 정확히 충족합니다.
Enumerable로 돌아가서 각 (each = function(iterator, context){}) 메서드의 본질은 루프이므로 첫 번째 매개변수 iterator에는 루프가 포함되어 있지 않으므로 break 문이 직접 호출됩니다. A 구문 오류가 보고되므로 프로토타입 소스 코드에서는 위의 두 번째 방법을 사용합니다.
코드 복사 코드는 다음과 같습니다.
Enumerable.each = function(iterator, context ) {
var index = 0;
try{
this._each(function(value){
iterator.call(context, value, index );
}); }catch( e){
if(e != $break){
throw e;
}
}
return this;
한 번 반복자 실행 중에 $break가 발생하면 루프가 중단됩니다. $break가 아니면 해당 오류가 발생하고 프로그램이 더 안정적이 됩니다. 여기서 $break 정의에 대한 특별한 요구 사항은 없습니다. 원하는 대로 변경할 수 있지만 큰 의미는 없습니다.
Enumerable의 일부 메소드는 일부 최신 브라우저에서 구현되었습니다(Chrome 기본 메소드 배열 참조). 비교 차트는 다음과 같습니다.
이러한 메서드를 구현할 때 기본 메서드를 빌려 효율성을 높일 수 있습니다. 그러나 소스 코드는 네이티브 부분을 차용하지 않습니다. 아마도 Enumerable을 Array 부분 외에 다른 개체와 혼합해야 하기 때문일 것입니다. 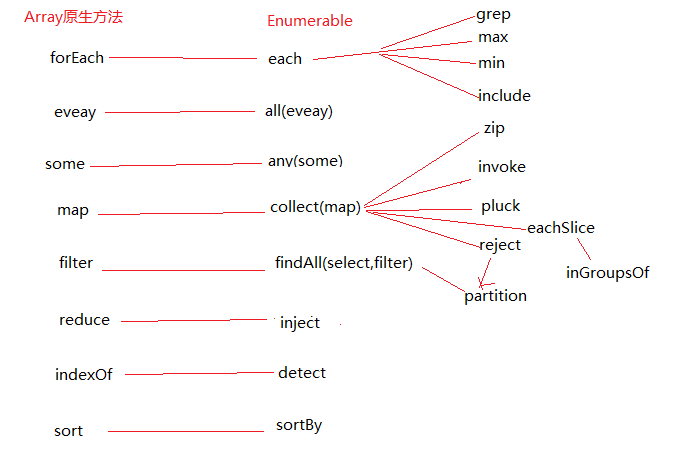
위의 다이어그램을 보면 각각과 맵의 중요성을 명확하게 알 수 있습니다. 맵의 본질은 여전히 각각이지만 각 컬렉션의 각 항목을 순차적으로 처리하고 맵도 각각을 기반으로 합니다. 처리된 결과를 반환합니다. Enumerable 내에서 map은 Collect 메소드의 별칭이고 다른 별칭은 select이며 내부적으로 Collect라는 이름이 사용됩니다.
탐지: all | any | include
이 세 가지 방법은 원본 컬렉션을 처리하지 않으며 반환 값은 모두 부울 유형입니다.
all : Enumerable의 모든 요소가 true와 동일하면 true를 반환하고, 그렇지 않으면 false를 반환합니다.
코드 복사 코드는 다음과 같습니다.
function all(iterator, context) { var result = true; this.each(function(value, index) {
결과 = 결과 && !!iterator.call(context, value, index)
return result
}
all 메소드의 경우 내부에 두 개의 매개변수가 필요하지 않으므로 실제 매개변수 없이 반복자를 대체하고 원래 값을 직접 반환하는 함수를 내부적으로 제공합니다. 이름은 Prototype.K입니다. Prototype.K는 라이브러리의 시작 부분에 정의되어 있으며, Prototype.K = function(x){return x;}입니다. 또한 all 방식에서는 한 항목의 처리 결과가 false인 한 전체 프로세스를 포기(break)할 수 있으므로 본 글의 시작 부분에서 루프를 중단시키는 방식을 사용한다. 최종 형식은 다음과 같습니다.
Prototype.K = function() {};
Enumerable.all = function(iterator, context) {
iterator = iterator || Prototype.K;
var result =
this.each(value; , index) {
result = result && !!iterator.call(context, value, index)
if (!result) throw $break
return result; >}
반환된 최종 결과는 부울 유형입니다. 모두에서 벗어나면 결과를 변경해 보겠습니다.
코드 복사
코드 복사
코드 복사
결과 = 결과 && !!iterator.call(context, value, index)
return result
}
all 메소드의 경우 내부에 두 개의 매개변수가 필요하지 않으므로 실제 매개변수 없이 반복자를 대체하고 원래 값을 직접 반환하는 함수를 내부적으로 제공합니다. 이름은 Prototype.K입니다. Prototype.K는 라이브러리의 시작 부분에 정의되어 있으며, Prototype.K = function(x){return x;}입니다. 또한 all 방식에서는 한 항목의 처리 결과가 false인 한 전체 프로세스를 포기(break)할 수 있으므로 본 글의 시작 부분에서 루프를 중단시키는 방식을 사용한다. 최종 형식은 다음과 같습니다.
코드 복사 코드는 다음과 같습니다.
Prototype.K = function() {};
Enumerable.all = function(iterator, context) {
iterator = iterator || Prototype.K;
var result =
this.each(value; , index) {
result = result && !!iterator.call(context, value, index)
if (!result) throw $break
return result; >}
반환된 최종 결과는 부울 유형입니다. 모두에서 벗어나면 결과를 변경해 보겠습니다.
코드 복사 코드는 다음과 같습니다.
function Collect(iterator, context) { iterator = iterator || Prototype.K; ;
this.each( function(value, index) {
results.push(iterator.call(context, value, index));
}); 결과 반환;
이때 결과는 배열이며, 처리를 중단하지 않고 모든 결과를 저장하고 반환합니다.
모두: Enumerable의 하나 이상의 요소가 true이면 true를 반환하고, 그렇지 않으면 false를 반환합니다. 원칙은 all과 유사하며 false가 발견되면 작동을 중지합니다. 거짓을 찾는다는 뜻입니다. 만약 사실이라면, 하루라고 부르세요.
this.each( function(value, index) {
results.push(iterator.call(context, value, index));
}); 결과 반환;
이때 결과는 배열이며, 처리를 중단하지 않고 모든 결과를 저장하고 반환합니다.
모두: Enumerable의 하나 이상의 요소가 true이면 true를 반환하고, 그렇지 않으면 false를 반환합니다. 원칙은 all과 유사하며 false가 발견되면 작동을 중지합니다. 거짓을 찾는다는 뜻입니다. 만약 사실이라면, 하루라고 부르세요.
코드 복사
코드는 다음과 같습니다. function any(iterator, context) { iterator = iterator || Prototype.K; var result = false
this.each(function(value, index) { if (result = !!iterator.call(context, value, index))
throw $break;
});
return result;
}
include: 지정된 객체가 Enumerable에 있는지 확인하고 비교합니다. == 연산자에 대한 최적화의 한 단계는 indexOf 메소드를 호출하는 것입니다. 배열의 경우 indexOf가 -1을 반환하면 해당 요소가 컬렉션에 indexOf 메소드가 없다는 의미입니다. 검색하고 비교할 수만 있습니다. 여기서는 검색과 합을 위한 알고리즘이 없고 그냥 하나씩 순회만 하면 쉽게 다시 작성할 수 있지만 일반적으로 사용되지 않으므로 이를 최적화하기 위한 노력은 이루어지지 않은 것으로 추정됩니다. 그래서 결과가 참일 경우 결과가 거짓일 때보다 효율성이 더 높으며 이는 운에 달려 있습니다.
throw $break;
});
return result;
}
include: 지정된 객체가 Enumerable에 있는지 확인하고 비교합니다. == 연산자에 대한 최적화의 한 단계는 indexOf 메소드를 호출하는 것입니다. 배열의 경우 indexOf가 -1을 반환하면 해당 요소가 컬렉션에 indexOf 메소드가 없다는 의미입니다. 검색하고 비교할 수만 있습니다. 여기서는 검색과 합을 위한 알고리즘이 없고 그냥 하나씩 순회만 하면 쉽게 다시 작성할 수 있지만 일반적으로 사용되지 않으므로 이를 최적화하기 위한 노력은 이루어지지 않은 것으로 추정됩니다. 그래서 결과가 참일 경우 결과가 거짓일 때보다 효율성이 더 높으며 이는 운에 달려 있습니다.
코드 복사
코드는 다음과 같습니다. function include(object) { if (Object .isFunction(this.indexOf))//이 판단 함수는 매우 친숙할 것입니다if (this.indexOf(object) != -1) return true;//indexOf가 있으면 <🎜를 호출하면 됩니다. >
var 직접 발견 = false; this.each(function(value) {//여기서 효율성 문제
if (value == object) {
found = true;
throw $ break;
}
});
returnfound;
}
다음은 데이터를 필터링하는 메서드 집합입니다. max | min | discover는 배열을 반환합니다. grep | findAll |ject | max와 min은 숫자 비교에만 국한되지 않고 문자 비교도 가능합니다. max(iterator, context)는 여전히 두 개의 매개변수를 가질 수 있습니다. iterator를 사용하여 먼저 처리한 다음 값을 비교할 수 있습니다. 예를 들어 객체 배열로 제한할 필요가 없다는 것입니다. 특정 규칙에 따라 최대값을 취합니다.
if (value == object) {
found = true;
throw $ break;
}
});
returnfound;
}
다음은 데이터를 필터링하는 메서드 집합입니다. max | min | discover는 배열을 반환합니다. grep | findAll |ject | max와 min은 숫자 비교에만 국한되지 않고 문자 비교도 가능합니다. max(iterator, context)는 여전히 두 개의 매개변수를 가질 수 있습니다. iterator를 사용하여 먼저 처리한 다음 값을 비교할 수 있습니다. 예를 들어 객체 배열로 제한할 필요가 없다는 것입니다. 특정 규칙에 따라 최대값을 취합니다.
코드 복사
코드는 다음과 같습니다. console.dir([{값 : 3},{값 : 1 },{값 : 2}].max(function(item){ return item.value; }));//3
소스 코드의 구현을 상상할 수 있으므로 직접 비교하면 구현은 다음과 같습니다.
코드 복사 코드는 다음과 같습니다. function max() { var result this.each(function(value) { if (result) == null || value >= result) //result==null은 첫 번째 비교
result = value })
return result;
확장 후 값은 더욱 value = (반복 처리 후 반환 값)이 됩니다.
function max(iterator, context) {
iterator = iterator || Prototype.K
this.each(function(value, index) {
value = iterator.call(context, value, index);
if (result == null || value >= result)
result = value
return result;
}
min도 같은 원리입니다. detector와 any의 원리는 비슷합니다. any는 true를 찾으면 true를 반환하고, detector는 true를 찾으면 true 조건을 만족하는 값을 반환합니다. 소스코드는 게시되지 않습니다. grep은 친숙해 보입니다. unix/linux 도구이고 그 기능도 매우 친숙합니다. 지정된 정규식과 일치하는 모든 요소를 반환합니다. 그러나 unix/linux에서는 문자열만 처리할 수 있습니다. 여기에서는 범위가 확장되지만 기본 형식은 변경되지 않습니다. 컬렉션의 각 항목이 문자열인 경우 구현은 다음과 같습니다.
여기서 value는 문자열이고 match는 String의 메서드입니다. 이제 지원되는 유형을 확장해야 합니다. 또는 각 값을 제공합니다. 일치 방법을 추가하거나 양식을 변환합니다. 분명히 첫 번째 유형의 노이즈가 너무 커서 저자는 마음을 바꿨습니다.
if (filter.match(value))
이런 식으로 필터에 값이 무엇이든 관계없이 해당 일치 방법은 위의 RegExp 개체에 일치 방법이 없으므로 작성자는 소스 코드에서 RegExp 개체를 확장했습니다.
RegExp.prototype.match = RegExp.prototype.test
위의 일치는 본질적으로 문자열 일치와 다릅니다. 이런 방식으로 값이 객체인 경우 필터는 해당 객체를 감지하기 위한 일치 메서드만 제공하면 됩니다.
return result;
확장 후 값은 더욱 value = (반복 처리 후 반환 값)이 됩니다.
코드 복사 코드는 다음과 같습니다. 다음 :
function max(iterator, context) {
iterator = iterator || Prototype.K
this.each(function(value, index) {
value = iterator.call(context, value, index);
if (result == null || value >= result)
result = value
return result;
}
min도 같은 원리입니다. detector와 any의 원리는 비슷합니다. any는 true를 찾으면 true를 반환하고, detector는 true를 찾으면 true 조건을 만족하는 값을 반환합니다. 소스코드는 게시되지 않습니다. grep은 친숙해 보입니다. unix/linux 도구이고 그 기능도 매우 친숙합니다. 지정된 정규식과 일치하는 모든 요소를 반환합니다. 그러나 unix/linux에서는 문자열만 처리할 수 있습니다. 여기에서는 범위가 확장되지만 기본 형식은 변경되지 않습니다. 컬렉션의 각 항목이 문자열인 경우 구현은 다음과 같습니다.
코드 복사 코드는 다음과 같습니다.
Enumerable.grep = function(filter) { if(typeof filter == 'string'){
filter = new RegExp(filter)
}
var 결과 = [];
this.each(function(value,index){
if(value.match(filter)){
results.push(value);
}
} )
return results;
};
그러나 더 넓은 범위의 애플리케이션을 구현하려면 먼저 처리해야 할 컬렉션이 있습니다. 고려해야 할 것은 호출 형식입니다. 위의 구현을 살펴보면 다음 문장에 주목하세요.
if(value.match(filter)) filter = new RegExp(filter)
}
var 결과 = [];
this.each(function(value,index){
if(value.match(filter)){
results.push(value);
}
} )
return results;
};
그러나 더 넓은 범위의 애플리케이션을 구현하려면 먼저 처리해야 할 컬렉션이 있습니다. 고려해야 할 것은 호출 형식입니다. 위의 구현을 살펴보면 다음 문장에 주목하세요.
여기서 value는 문자열이고 match는 String의 메서드입니다. 이제 지원되는 유형을 확장해야 합니다. 또는 각 값을 제공합니다. 일치 방법을 추가하거나 양식을 변환합니다. 분명히 첫 번째 유형의 노이즈가 너무 커서 저자는 마음을 바꿨습니다.
if (filter.match(value))
이런 식으로 필터에 값이 무엇이든 관계없이 해당 일치 방법은 위의 RegExp 개체에 일치 방법이 없으므로 작성자는 소스 코드에서 RegExp 개체를 확장했습니다.
RegExp.prototype.match = RegExp.prototype.test
위의 일치는 본질적으로 문자열 일치와 다릅니다. 이런 방식으로 값이 객체인 경우 필터는 해당 객체를 감지하기 위한 일치 메서드만 제공하면 됩니다.
코드 복사 코드는 다음과 같습니다.
function grep(filter, iterator, context ) { iterator = iterator || Prototype.K;
var results = []
if (Object.isString(filter))
filter = new RegExp .escape( filter));
this.each(function(value, index) {
if (filter.match(value))//네이티브 필터에 일치 방법이 없습니다.
결과 .push( iterator.call(context, value, index));
});
return results
}
결과를 처리한 다음 이를 반환합니다. 이것이 반복자 매개변수의 역할입니다. max 메소드와 달리 grep은 기본 작업을 수행할 때 반복자를 사용하여 결과를 처리합니다. Max는 기본 작업을 수행하기 전에 반복자를 사용하여 소스 데이터를 처리합니다. grep의 필터가 max의 반복자를 대체하기 때문입니다. findAll은 grep의 향상된 버전입니다. grep을 읽어보면 findAll은 매우 간단합니다. Reject는 정확히 반대 효과를 갖는 findAll의 쌍둥이 버전입니다. 파티션은 findAll 거부, 부모-자식 결합 버전입니다. Xiaoxi Shanzi에서 재인쇄할 때 표시해 주십시오. [http://www.cnblogs.com/xesam/]
var results = []
if (Object.isString(filter))
filter = new RegExp .escape( filter));
this.each(function(value, index) {
if (filter.match(value))//네이티브 필터에 일치 방법이 없습니다.
결과 .push( iterator.call(context, value, index));
});
return results
}
결과를 처리한 다음 이를 반환합니다. 이것이 반복자 매개변수의 역할입니다. max 메소드와 달리 grep은 기본 작업을 수행할 때 반복자를 사용하여 결과를 처리합니다. Max는 기본 작업을 수행하기 전에 반복자를 사용하여 소스 데이터를 처리합니다. grep의 필터가 max의 반복자를 대체하기 때문입니다. findAll은 grep의 향상된 버전입니다. grep을 읽어보면 findAll은 매우 간단합니다. Reject는 정확히 반대 효과를 갖는 findAll의 쌍둥이 버전입니다. 파티션은 findAll 거부, 부모-자식 결합 버전입니다. Xiaoxi Shanzi에서 재인쇄할 때 표시해 주십시오. [http://www.cnblogs.com/xesam/]
성명:
본 글의 내용은 네티즌들의 자발적인 기여로 작성되었으며, 저작권은 원저작자에게 있습니다. 본 사이트는 이에 상응하는 법적 책임을 지지 않습니다. 표절이나 침해가 의심되는 콘텐츠를 발견한 경우 admin@php.cn으로 문의하세요.