
데이터 대치를위한 Pandas Fillna ()

- Jennifer Aniston원래의
- 2025-03-17 10:46:08881검색
누락 데이터를 처리하는 것은 데이터 분석 및 기계 학습의 중요한 단계입니다. 데이터 입력 오류 또는 고유 한 데이터 제한과 같은 다양한 소스에서 비롯된 결 측값은 분석 정확도 및 모델 신뢰성에 심각하게 영향을 줄 수 있습니다. 강력한 Python 라이브러리 인 Pandas는 효과적인 결측 데이터 대치를위한 다양한 도구 인 fillna() 방법을 제공합니다. 이 방법을 사용하면 결 측값을 다양한 전략으로 바꾸어 분석을위한 데이터 완전성을 보장 할 수 있습니다.

목차
- 데이터의 대치 란 무엇입니까?
- 데이터 대치의 중요성
- 데이터 세트 왜곡
- 머신 러닝 라이브러리 제한
- 모델 성능 영향
- 데이터 세트 완전성 복원
- Pandas
fillna()이해-
fillna()구문
-
-
fillna()가있는 데이터 대치 기술- 이전/다음 값을 사용합니다
- 최대/최소값의 대치
- 평균 대치
- 중간 대치
- 이동 평균 대치
- 둥근 평균 대치
- 고정 가치의 대치
- 결론
- 자주 묻는 질문
데이터의 대치 란 무엇입니까?
데이터 대치는 데이터 세트 내에서 누락 된 데이터 포인트를 채우는 기술입니다. 누락 데이터는 많은 분석 방법과 완전한 데이터 세트가 필요한 기계 학습 알고리즘에 중대한 도전을 제기합니다. 대치는 사용 가능한 데이터를 기반으로 결 측값을 그럴듯한 대체물로 추정하고 대체함으로써이를 해결합니다.
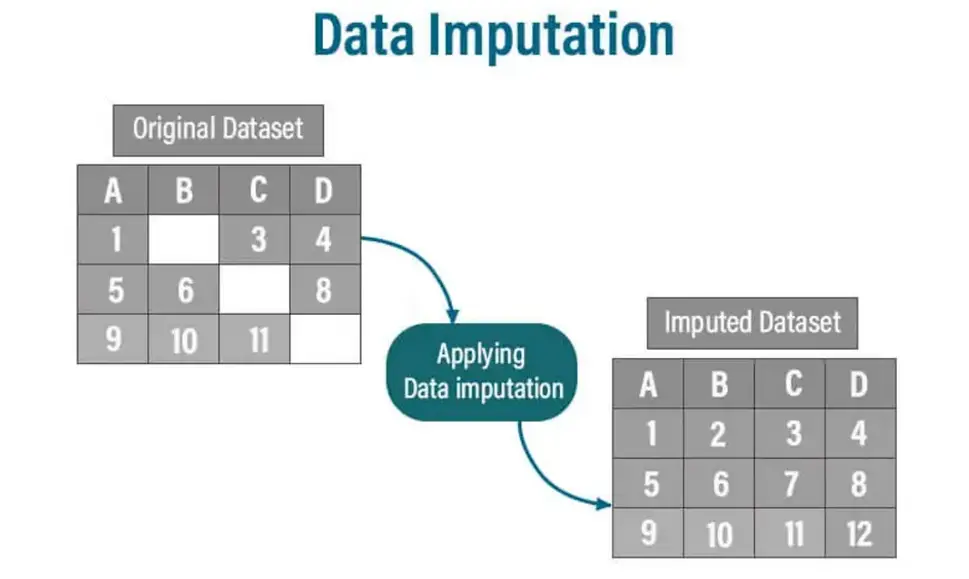
데이터의 대치가 중요한 이유는 무엇입니까?
몇 가지 주요 이유는 데이터 대치의 중요성을 강조합니다.
- 데이터 세트 왜곡 : 누락 된 데이터는 가변 분포를 기울여 데이터 무결성을 손상시킬 수 있습니다. 이것은 부정확 한 결론으로 이어질 수 있습니다.
- 머신 러닝 라이브러리 제약 조건 : 많은 기계 학습 라이브러리는 완전한 데이터 세트를 가정합니다. 결 측값은 오류를 유발하거나 알고리즘 실행을 방지 할 수 있습니다.
- 모델 성능 영향 : 누락 된 데이터는 편향을 도입하여 신뢰할 수없는 예측과 통찰력을 초래합니다.
- 데이터 세트 완전성 : 데이터가 제한된 상황에서는 소량의 누락 된 정보조차도 분석에 큰 영향을 줄 수 있습니다. 대치는 사용 가능한 모든 정보를 보존하는 데 도움이됩니다.
Pandas fillna() 이해
Pandas fillna() 메소드는 데이터 프레임 또는 시리즈의 NaN (숫자가 아님) 값을 대체하도록 설계되었습니다. 다양한 대치 전략을 제공합니다.
fillna() 구문

주요 매개 변수에는 value (교체 값), method (예 : 전방 채우기를위한 'ffill', 후진 채우기를위한 'bfill'), axis , inplace , limit 및 downcast 포함됩니다.
다른 대치 기술에 fillna() 사용합니다
fillna() 사용하여 몇 가지 대치 기술을 구현할 수 있습니다.
- 다음 또는 이전 값 : 순차 데이터의 경우이 방법은 가장 가까운 유효한 값을 사용합니다.
- 최대 또는 최소값 : 데이터가 제한 될 때 유용합니다.
- 평균 대치 : 결 측값을 열 평균으로 대체합니다. 특이 치에 민감합니다.
- 중간 대치 : 결 측값을 열 중앙값으로 대체합니다. 평균보다 이상치에 더 강력합니다.
- 이동 평균 대치 : 주변 값의 평균을 사용합니다. 시계열 데이터에 효과적입니다.
- 둥근 평균 대치 : 둥근 평균으로 대체하여 데이터 정밀도를 유지하는 데 유용합니다.
- 고정 값 대치 : 미리 정해진 값 (예 : 0, '알 수없는')으로 대체합니다.
(원래 텍스트 코드 예제의 구조와 내용을 반영하여 각 기술에 대한 코드 예제가 여기에 포함됩니다.)
결론
효과적인 결측 데이터 처리는 신뢰할 수있는 데이터 분석 및 기계 학습에 필수적입니다. Pandas ' fillna() 메소드는 강력하고 유연한 솔루션을 제공하여 다양한 데이터 유형과 컨텍스트에 맞는 다양한 대치 전략을 제공합니다. 올바른 방법을 선택하는 것은 데이터 세트의 특성과 분석 목표에 따라 다릅니다.
자주 묻는 질문
(FAQ 섹션은 원래 텍스트의 내용을 반영하여 유지됩니다.)
위 내용은 데이터 대치를위한 Pandas Fillna ()의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!