



Linux 시스템의 head 명령은 파일 정보를 처리하고 추출하는 강력한 도구입니다. 이 기사에서는 기본 구문에서 고급 기능에 이르기까지 head 명령의 힘을 마스터하기위한 자세한 안내서를 제공하여 head 명령의 숙련 된 사용자가됩니다.
head 명령 기본 사항
head 명령은 파일 또는 표준 입력의 시작을 표시하기위한 Linux의 유틸리티입니다. 큰 파일을 분석하고 관련 데이터를 효율적으로 추출하는 데 특히 적합합니다.
구문 및 사용
head 명령의 구문은 다음과 같습니다.
헤드 [옵션] ... [파일] ...
명령의 출력 형식 및 동작을 제어하기 위해 다양한 옵션을 지정할 수 있습니다.
핵심 기능
첫 번째 n 줄 표시 : 파일에서 첫 번째 N 줄을 추출하려면 다음 명령을 사용하십시오.
헤드 -n
이 기능은 파일 내용을 빠르게 미리보기하거나 데이터 요약을 가져와야 할 때 유용합니다.
기본 행의 행을 표시하십시오. 행 카운트가 지정되지 않은 경우 head 명령은 기본적으로 처음 10 줄을 표시합니다. 이 기본 동작은 -n 옵션을 사용하여 변경할 수 있습니다.
고급 기능
여러 파일 결합 : 여러 파일의 시작을 동시에 보려면 head 명령을 사용하고 여러 파일 이름을 매개 변수로 사용할 수 있습니다. 예를 들어:
머리 <file> <file> </file></file>
이를 통해 여러 파일의 초기 콘텐츠를 쉽게 비교할 수 있습니다.
-C 옵션 사용 : 행 수에 추가하여 -c 옵션을 사용하여 특정 바이트 수를 추출 할 수도 있습니다. 예를 들어:
Head -c <bytes> <filename></filename></bytes>
이 기능은 이진 파일을 처리하거나 특정 데이터 블록을 추출해야 할 때 매우 중요합니다.
최적화 된 출력 및 사용
Filenames 억제 : 기본적으로 head 명령은 파일 이름과 추출 된 라인을 표시합니다. 그러나 파일 이름을 표시하지 않고도 줄을 보려면 -q 또는 --quiet 옵션을 사용할 수 있습니다.
다른 명령과 결합 : head 명령은 다른 Linux 명령과 완벽하게 통합되어 강력한 데이터 처리 파이프 라인을 구축 할 수 있습니다. 예를 들어, 명령의 출력을 head 명령에 입력하여 데이터에 대한보다 세분화 된 분석을 수행 할 수 있습니다.
실제 예
다음은 head 명령의 실제 예입니다.
- 파일의 처음 20 줄 추출 :
head -n 20 filename.txt - 여러 파일의 초기 줄보기 :
head file1.txt file2.txt file3.txt - 이진 파일의 첫 100 바이트 표시 :
head -c 100 binaryfile.bin
요약
이 기사에서는 Linux의 head Command에 대해 설명합니다. 기본 구문 및 고급 기능을 이해함으로써 파일에서 귀중한 정보를 효율적으로 추출 할 수 있습니다. 이 지식을 통해 데이터 처리 흐름을 최적화하고 Linux의 능력을 향상시킬 수 있습니다. Linux 여행에 새로운 가능성을 열기 위해 head 명령의 힘을 활용하십시오.
위 내용은 HEAD 명령의 전력 마스터 링 : Linux에서 효율적인 데이터 처리 잠금 해제의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

 다양한 작업에 대한 성능은 Linux와 Windows간에 어떻게 다릅니 까?May 14, 2025 am 12:03 AM
다양한 작업에 대한 성능은 Linux와 Windows간에 어떻게 다릅니 까?May 14, 2025 am 12:03 AMLinux는 서버 및 개발 환경에서 잘 작동하는 반면 Windows는 데스크탑 및 게임에서 더 잘 수행됩니다. 1) Linux의 파일 시스템은 많은 작은 파일을 처리 할 때 잘 수행됩니다. 2) Linux는 높은 동시성 및 높은 처리량 네트워크 시나리오에서 훌륭하게 수행합니다. 3) Linux 메모리 관리는 서버 환경에서 더 많은 장점이 있습니다. 4) Linux는 명령 줄 및 스크립트 작업을 실행할 때 효율적이며 Windows는 그래픽 인터페이스 및 멀티미디어 응용 프로그램에서 더 잘 수행합니다.
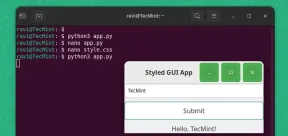 pygobject를 사용하여 Linux에서 GUI 애플리케이션을 만드는 방법May 13, 2025 am 11:09 AM
pygobject를 사용하여 Linux에서 GUI 애플리케이션을 만드는 방법May 13, 2025 am 11:09 AM그래픽 사용자 인터페이스 (GUI) 응용 프로그램 작성은 아이디어를 활성화시키고 프로그램을보다 사용자 친화적으로 만들 수있는 환상적인 방법입니다. PygoBject는 개발자가
 아치 리눅스에서 phpmyadmin으로 램프 스택을 설치하는 방법May 13, 2025 am 11:01 AM
아치 리눅스에서 phpmyadmin으로 램프 스택을 설치하는 방법May 13, 2025 am 11:01 AMArch Linux는 유연한 최첨단 시스템 환경을 제공하며 소규모 비 크리티컬 시스템에서 웹 애플리케이션을 개발하는 데 강력하게 적합한 솔루션입니다.
 Arch Linux에 Lemp (Nginx, Php, Mariadb)를 설치하는 방법May 13, 2025 am 10:43 AM
Arch Linux에 Lemp (Nginx, Php, Mariadb)를 설치하는 방법May 13, 2025 am 10:43 AM최첨단 소프트웨어를 수용하는 롤링 릴리스 모델로 인해 Arch Linux는 유지 보수, 지속적인 업그레이드 및 현명한 FI를위한 추가 시간이 필요하기 때문에 신뢰할 수있는 네트워크 서비스를 제공하기 위해 서버로 설계 및 개발되지 않았습니다.
![12 Linux 콘솔 [터미널] 파일 관리자](https://img.php.cn/upload/article/001/242/473/174710245395762.png?x-oss-process=image/resize,p_40) 12 Linux 콘솔 [터미널] 파일 관리자May 13, 2025 am 10:14 AM
12 Linux 콘솔 [터미널] 파일 관리자May 13, 2025 am 10:14 AMLinux 콘솔 파일 관리자는 일상적인 작업, 로컬 컴퓨터에서 파일을 관리 할 때 또는 원격 제품에 연결할 때 매우 도움이 될 수 있습니다. 디렉토리의 비주얼 콘솔 표현은 파일/폴더 작업 및 SAV를 신속하게 수행하는 데 도움이됩니다.
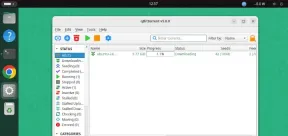 QBITTORRENT : 강력한 오픈 소스 비트 토렌트 클라이언트May 13, 2025 am 10:12 AM
QBITTORRENT : 강력한 오픈 소스 비트 토렌트 클라이언트May 13, 2025 am 10:12 AMQBITTORRENT는 사용자가 인터넷을 통해 파일을 다운로드하고 공유 할 수있는 인기있는 오픈 소스 비트 토렌트 클라이언트입니다. 최신 버전 인 QBITTORRENT 5.0은 최근에 출시되었으며 새로운 기능과 개선 사항이 제공됩니다. 이 기사는 할 것입니다
 아치 Linux에서 Nginx Virtual Hosts, Phpmyadmin 및 SSL 설정May 13, 2025 am 10:03 AM
아치 Linux에서 Nginx Virtual Hosts, Phpmyadmin 및 SSL 설정May 13, 2025 am 10:03 AM이전 Arch Linux Lemp 기사는 네트워크 서비스 설치 (NGINX, PHP, MYSQL 및 PHPMYADMIN)와 MySQL Server 및 PhpmyAdmin에 필요한 최소 보안 구성에서 기본 사항을 다루었습니다. 이 주제는 엄격하게 Forme과 관련이 있습니다
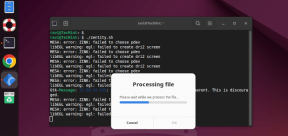 Zenity : 쉘 스크립트에서 GTK 대화 상자 구축May 13, 2025 am 09:38 AM
Zenity : 쉘 스크립트에서 GTK 대화 상자 구축May 13, 2025 am 09:38 AMZenity는 명령 줄을 사용하여 Linux에서 그래픽 대화 상자를 만들 수있는 도구입니다. 그래픽 사용자 인터페이스 (GUI)를 만들기위한 툴킷 인 GTK를 사용하여 스크립트에 시각적 요소를 쉽게 추가 할 수 있습니다. Zenity는 매우 u 일 수 있습니다


핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SecList
SecLists는 최고의 보안 테스터의 동반자입니다. 보안 평가 시 자주 사용되는 다양한 유형의 목록을 한 곳에 모아 놓은 것입니다. SecLists는 보안 테스터에게 필요할 수 있는 모든 목록을 편리하게 제공하여 보안 테스트를 더욱 효율적이고 생산적으로 만드는 데 도움이 됩니다. 목록 유형에는 사용자 이름, 비밀번호, URL, 퍼징 페이로드, 민감한 데이터 패턴, 웹 셸 등이 포함됩니다. 테스터는 이 저장소를 새로운 테스트 시스템으로 간단히 가져올 수 있으며 필요한 모든 유형의 목록에 액세스할 수 있습니다.

맨티스BT
Mantis는 제품 결함 추적을 돕기 위해 설계된 배포하기 쉬운 웹 기반 결함 추적 도구입니다. PHP, MySQL 및 웹 서버가 필요합니다. 데모 및 호스팅 서비스를 확인해 보세요.

ZendStudio 13.5.1 맥
강력한 PHP 통합 개발 환경

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

