
전문가의 혼합이란 무엇입니까?

- William Shakespeare원래의
- 2025-03-14 10:03:10696검색
전문가 (MOE) 모델의 혼합은 효율성과 확장 성을 향상시켜 LLM (Lange Language Model)에 혁명을 일으키고 있습니다. 이 혁신적인 아키텍처는 모델을 특수 하위 네트워크 또는 "전문가"로 나눕니다. 입력에 기초하여 관련 전문가의 하위 집합 만 활성화함으로써 MOE 모델은 계산 비용을 비례 적으로 증가시키지 않으면 서 용량을 크게 향상시킵니다. 이 선택적 활성화는 자원 사용을 최적화하고 자연어 처리, 컴퓨터 비전 및 권장 시스템과 같은 다양한 분야에서 복잡한 작업을 처리 할 수 있습니다. 이 기사는 MOE 모델, 기능, 인기있는 예 및 Python 구현을 탐구합니다.
이 기사는 Data Science Blogathon의 일부입니다.
목차 :
- 전문가 (Moes)의 혼합은 무엇입니까?
- 딥 러닝의 Moes
- MOE 모델은 어떻게 작동합니까?
- 저명한 Moe 기반 모델
- Moes의 파이썬 구현
- 다른 MOE 모델의 출력 비교
- DBRX
- Deepseek-V2
- 자주 묻는 질문
전문가 (Moes)의 혼합은 무엇입니까?
MOE 모델은 단일 대형 모델 대신 여러 개의 작고 전문화 된 모델을 사용하여 기계 학습을 향상시킵니다. 각 작은 모델은 특정 문제 유형에서 탁월합니다. "의사 결정자"(게이팅 메커니즘)는 각 작업에 적합한 모델을 선택하여 전반적인 성능을 향상시킵니다. 변압기를 포함한 최신 딥 러닝 모델은 데이터를 처리하고 결과를 후속 층으로 전달하는 계층 상호 연결된 장치 ( "뉴런")를 사용합니다. Moe는 복잡한 문제를 특수 구성 요소 ( "전문가")로 나누어 각각의 특정 측면을 다루어 이것을 반영합니다.
MOE 모델의 주요 장점 :
- 밀도가 높은 모델에 비해 더 빠른 사전 훈련.
- 유사한 매개 변수 계수로도 빠른 추론.
- 메모리에있는 모든 전문가의 동시 스토리지로 인한 높은 VRAM 수요.
MOE 모델은 전문가 (전문화 된 소규모 신경 네트워크)와 라우터 (입력을 기반으로 관련 전문가를 활성화 함)의 두 가지 주요 부분으로 구성됩니다. 이 선택적 활성화는 효율성을 높입니다.
딥 러닝의 Moes
딥 러닝에서 MOE는 복잡한 문제를 해결하여 신경망 성능을 향상시킵니다. 단일 대형 모델 대신 다른 입력 데이터 측면을 전문으로하는 여러 개의 작은 "전문가"모델을 사용합니다. 게이팅 네트워크는 각 입력에 사용할 전문가 (들)가 효율성과 효율성을 향상시키는 전문가를 결정합니다.
MOE 모델은 어떻게 작동합니까?
MOE 모델은 다음과 같이 작동합니다.
- 다수의 전문가 : 이 모델에는 여러 개의 작은 신경망 ( "전문가")이 포함되어 있으며 각각의 특정 입력 유형 또는 작업에 대해 교육을 받았습니다.
- 게이팅 네트워크 : 별도의 신경망 (게이팅 네트워크)은 각 입력에 사용할 전문가 (들)를 결정하여 최종 출력에 대한 각 전문가의 기여를 표시하기 위해 가중치를 할당합니다.
- 동적 라우팅 : 게이팅 네트워크는 각 입력에 대해 가장 관련성이 높은 전문가를 동적으로 선택하여 효율성을 최적화합니다.
- 출력 결합 : 선택한 전문가의 출력은 게이팅 네트워크의 지정된 가중치를 기반으로 결합하여 최종 예측을 생성합니다.
- 효율성 및 확장 성 : MOE 모델은 각 입력에 대해 소수의 전문가 만 활성화되어 계산 비용을 줄이기 때문에 효율적입니다. 입력 당 계산을 크게 증가시키지 않고 더 복잡한 작업을 처리하기 위해 더 많은 전문가를 추가하여 확장 성을 달성합니다.
저명한 Moe 기반 모델
성능을 유지하면서 LLM의 효율적인 스케일링으로 인해 MOE 모델은 AI에서 점점 더 중요 해지고 있습니다. 주목할만한 예인 Mixtral 8x7b는 희소 한 MOE 아키텍처를 사용하여 각 입력에 대한 전문가의 하위 집합 만 활성화하여 상당한 효율성 이득을 초래합니다.
믹스 트랄 8x7b
Mixtral 8x7b는 디코더 전용 변압기입니다. 입력 토큰은 벡터에 내장되어 디코더 층을 통해 처리됩니다. 출력은 각 위치가 단어로 점유 될 확률로 텍스트 충전 및 예측을 가능하게합니다. 각각의 디코더 층에는주의 메커니즘 (문맥 정보)과 전문가 (SMOE) 섹션 (각 단어 벡터를 개별적으로 처리 함)의 희소 혼합물이 있습니다. 스모이 레이어는 여러 층 ( "전문가")을 사용하고 각 입력에 대해 가장 관련성이 높은 전문가의 출력의 가중 합계가 취해집니다.
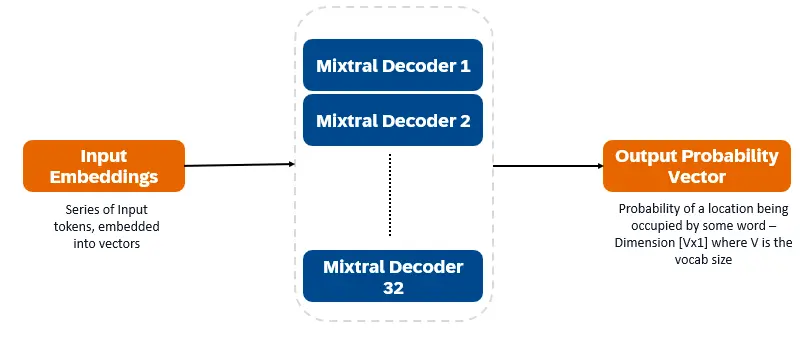
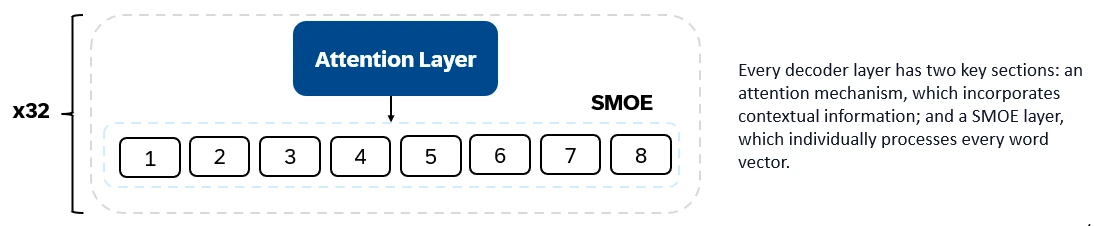
Mixtral 8x7b의 주요 기능 :
- 총 전문가 : 8
- 활발한 전문가 : 2
- 디코더 층 : 32
- 어휘 크기 : 32000
- 임베딩 크기 : 4096
- 전문가 크기 : 각각 56 억 매개 변수 (공유 구성 요소의 총 7 억)
- 활성 매개 변수 : 128 억
- 컨텍스트 길이 : 32k 토큰
Mixtral 8x7b는 텍스트 생성, 이해력, 번역, 요약 등이 뛰어납니다.
DBRX
DBRX (Databricks)는 차세대 예측을 사용하여 트랜스포머 기반 디코더 전용 LLM입니다. 세분화 된 MOE 아키텍처 (132B 총 매개 변수, 36B 활성)를 사용합니다. 12T 토큰의 텍스트 및 코드 데이터에서 미리 훈련되었습니다. DBRX는 많은 소규모 전문가 (16 명의 전문가, 입력 당 4 명)를 사용하여 세밀하게 입자했습니다.
DBRX의 주요 건축 기능 :
- 세밀한 전문가 : 단일 FFN은 세그먼트로 나뉘며 각각은 전문가 역할을합니다.
- 기타 기술 : 로터리 위치 인코딩 (로프), 게이트 선형 유닛 (GLU) 및 그룹화 된 쿼리주의 (GQA).
DBRX의 주요 기능 :
- 총 전문가 : 16
- 레이어 당 활성 전문가 : 4
- 디코더 층 : 24
- 활성 매개 변수 : 360 억
- 총 매개 변수 : 132 억
- 컨텍스트 길이 : 32k 토큰
DBRX는 코드 생성, 복잡한 언어 이해 및 수학적 추론에 탁월합니다.
Deepseek-V2
DeepSeek-V2는 세밀한 전문가와 공유 전문가 (항상 Active)를 사용하여 보편적 지식을 통합합니다.
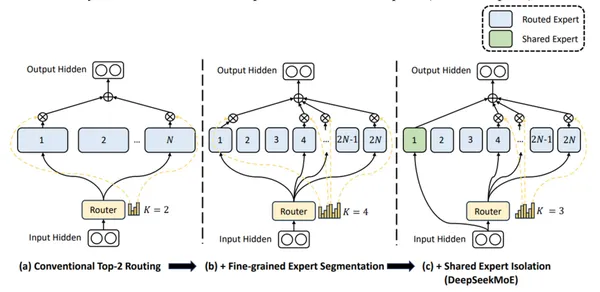
DeepSeek-V2의 주요 기능 :
- 총 매개 변수 : 236 억
- 활성 매개 변수 : 210 억
- 레이어 당 라우팅 된 전문가 : 160 (2 선택)
- 계층 당 공유 전문가 : 2
- 레이어 당 활성 전문가 : 8
- 디코더 층 : 60
- 컨텍스트 길이 : 128K 토큰
DeepSeek-V2는 대화, 콘텐츠 생성 및 코드 생성에 능숙합니다.
(Python 구현 및 출력 비교 섹션은 긴 코드 예제 및 자세한 분석이므로 간결하게 제거되었습니다.)
자주 묻는 질문
Q1. 전문가 (MOE) 모델의 혼합은 무엇입니까? A. MOE 모델은 희소 아키텍처를 사용하여 각 작업에 대해 가장 관련성이 높은 전문가 만 활성화하여 계산 자원 사용이 줄어 듭니다.
Q2. MOE 모델과의 상충 관계는 무엇입니까? A. MOE 모델은 모든 전문가를 메모리에 저장하고 계산 능력 및 메모리 요구 사항을 균형을 잡기 위해 상당한 VRAM이 필요합니다.
Q3. Mixtral 8x7b의 활성 매개 변수 수는 무엇입니까? A. Mixtral 8x7b에는 128 억 개의 활성 매개 변수가 있습니다.
Q4. DBRX는 다른 MOE 모델과 어떻게 다릅니 까? A. DBRX는 더 작은 전문가와 함께 세밀한 MOE 접근법을 사용합니다.
Q5. DeepSeek-V2를 구별하는 것은 무엇입니까? A. DeepSeek-V2는 세분화 된 및 공유 전문가와 큰 매개 변수 세트 및 긴 컨텍스트 길이를 결합합니다.
결론
MOE 모델은 딥 러닝에 대한 매우 효율적인 접근 방식을 제공합니다. 상당한 VRAM이 필요하지만 전문가의 선택적 활성화는 다양한 영역에서 복잡한 작업을 처리하기위한 강력한 도구가됩니다. Mixtral 8x7b, DBRX 및 DeepSeek-V2는이 분야에서 각각 고유 한 강점과 응용 분야에서 상당한 발전을 나타냅니다.
위 내용은 전문가의 혼합이란 무엇입니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!