



Excel에서 표준 편차를 계산하는 방법
Excel에서 표준 편차를 계산하는 것은 내장 기능을 사용하여 간단합니다. 가장 일반적인 기능은 샘플 표준 편차를 계산하는 STDEV.S 입니다. 데이터가 더 많은 모집단의 샘플을 나타낼 때 사용됩니다. 귀하의 데이터가 전체 인구를 나타내는 경우 STDEV.P 사용하십시오.
이러한 기능을 사용하려면 :
- 셀 선택 : 결과가 나타나려는 빈 셀을 선택하십시오.
- 기능을 입력하십시오 : type
=STDEV.S(range)또는=STDEV.P(range)입력하고 "범위"를 실제 데이터 셀의 범위로 대체하십시오. 예를 들어, 데이터가 셀 A1에서 A10에 있으면=STDEV.S(A1:A10)또는=STDEV.P(A1:A10)입력합니다. - Enter : Excel은 선택한 셀에서 표준 편차를 계산하고 표시합니다.
STDEV.S N-1 (여기서 N 은 데이터 포인트 수)으로 나누어 샘플을 기반으로 모집단 표준 편차의 편견없는 추정치를 제공한다는 것을 기억하십시오. STDEV.P 는 n 으로 나뉘어 전체 인구의 표준 편차를 계산합니다. 데이터가 샘플 또는 전체 모집단을 나타내는 지에 따라 적절한 기능을 선택하십시오.
Excel에서 표준 편차를 계산하는 다른 방법은 무엇입니까?
Excel은 주로 표준 편차 계산을위한 두 가지 기능을 제공합니다.
-
STDEV.S(샘플 표준 편차) : 이 함수는 샘플의 표준 편차를 계산합니다. 전체 인구와 함께 일하지 않는 한 일반적으로 선호되는 방법입니다. √ [σ (xi -x̄) ² / (n -1)], 여기서 xi는 각 데이터 포인트를 나타내고 x̄는 샘플 평균, n은 샘플 크기입니다. (N-1)의 부서는 인구 표준 편차에 대한 편견없는 추정치를 제공합니다. -
STDEV.P(인구 표준 편차) : 이 함수는 전체 인구의 표준 편차를 계산합니다. √ [σ (xi -μ) ² / n], 여기서 xi는 각 데이터 포인트, μ는 모집단 평균, N은 모집단 크기를 사용합니다. 데이터가 관심있는 전체 인구를 대표 할 때만 사용하십시오.
이것들은 기본 기능이지만 다른 Excel 함수를 사용하여 표준 편차를 수동으로 계산 STDEV.P 평균, STDEV.S 차이 등을 계산하는 것이 훨씬 더 효율적이고 오류가 덜 발생합니다.
Excel의 특정 범위의 데이터에 대한 표준 편차를 계산할 수 있습니까?
예, 물론. STDEV.S 및 STDEV.P 함수를 사용하면 표준 편차를 계산하려는 데이터를 포함하는 정확한 셀 범위를 지정할 수 있습니다. 기능의 괄호 안에 셀 범위를 입력하면됩니다.
예를 들어:
-
=STDEV.S(B5:B20)셀 B5에서 B20 셀의 데이터에 대한 샘플 표준 편차를 계산합니다. -
=STDEV.P(A1:D10)A1에서 D10에서 직사각형 범위의 데이터에 대한 모집단 표준 편차를 계산합니다. 여기에는 해당 영역 내의 모든 데이터가 포함됩니다.
명명 된 범위를 포함하여 함수 내에서 유효한 Excel 범위 표기법을 사용할 수 있습니다. 이 유연성을 사용하면 데이터의 특정 하위 집합을 정확하게 분석 할 수 있습니다.
Excel에서 계산 된 표준 편차 값을 어떻게 해석합니까?
표준 편차는 데이터 세트의 분산량 또는 변동성을 나타냅니다. 표준 편차가 높을수록 변동성이 높아져 데이터 포인트가 평균 (평균)에서 더 많이 확산됩니다. 표준 편차가 낮을수록 변동성이 줄어 듭니다. 즉, 데이터 포인트가 평균 주위에 더 밀접하게 클러스터링됩니다.
예를 들어:
- 낮은 표준 편차 : 표준 편차가 낮 으면 대부분의 데이터 포인트가 평균값에 가깝습니다. 이것은 데이터의 일관성 또는 동질성을 나타냅니다.
- 높은 표준 편차 : 표준 편차가 높으면 데이터 포인트가 평균값 주위에 널리 분산되어 있음을 시사합니다. 이것은 데이터의 더 큰 가변성 또는 이질성을 나타냅니다.
표준 편차를 해석 할 때 데이터의 컨텍스트를 고려하는 것이 중요합니다. 측정중인 데이터의 스케일과 특성에 따라 10의 표준 편차가 하나의 데이터 세트에 대해 높지만 다른 데이터 세트의 경우 낮은 것으로 간주 될 수 있습니다. 종종 표준 편차는 데이터의 분포 및 특성에 대한보다 완전한 이해를 제공하기 위해 평균과 함께 사용됩니다.
위 내용은 Excel에서 표준 편차를 계산하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

 Excel의 중간 공식 - 실제 예Apr 11, 2025 pm 12:08 PM
Excel의 중간 공식 - 실제 예Apr 11, 2025 pm 12:08 PM이 튜토리얼은 중간 기능을 사용하여 Excel에서 수치 데이터의 중앙값을 계산하는 방법을 설명합니다. 중앙 경향의 주요 척도 인 중앙값은 데이터 세트의 중간 값을 식별하여 Central Tenden의보다 강력한 표현을 제공합니다.
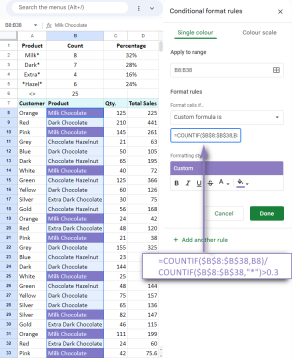 Google 스프레드 시트 Countif 기능은 공식 예제와 함께합니다Apr 11, 2025 pm 12:03 PM
Google 스프레드 시트 Countif 기능은 공식 예제와 함께합니다Apr 11, 2025 pm 12:03 PM마스터 Google Sheets Countif : 포괄적 인 가이드 이 안내서는 Google 시트의 다목적 카운티프 기능을 탐색하여 간단한 셀 카운팅 이외의 응용 프로그램을 보여줍니다. 우리는 정확하고 부분적인 경기에서 Han에 이르기까지 다양한 시나리오를 다룰 것입니다.
 Excel 공유 통합 문서 : 여러 사용자를위한 Excel 파일을 공유하는 방법Apr 11, 2025 am 11:58 AM
Excel 공유 통합 문서 : 여러 사용자를위한 Excel 파일을 공유하는 방법Apr 11, 2025 am 11:58 AM이 튜토리얼은 다양한 방법, 액세스 제어 및 갈등 해결을 다루는 Excel 통합 문서 공유에 대한 포괄적 인 안내서를 제공합니다. Modern Excel 버전 (2010, 2013, 2016 및 이후) 협업 편집을 단순화하여 M에 대한 필요성을 제거합니다.
 Excel을 JPG로 변환하는 방법 - 이미지 파일로 .xls 또는 .xlsx를 저장Apr 11, 2025 am 11:31 AM
Excel을 JPG로 변환하는 방법 - 이미지 파일로 .xls 또는 .xlsx를 저장Apr 11, 2025 am 11:31 AM이 자습서는 .xls 파일을 .jpg 이미지로 변환하는 다양한 방법을 탐색하여 내장 된 Windows 도구와 무료 온라인 변환기를 모두 포함합니다. 프레젠테이션을 만들거나 스프레드 시트 데이터를 단단히 공유하거나 문서를 디자인해야합니까? YO를 변환합니다
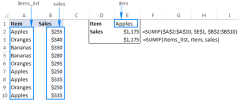 Excel 이름 및 명명 범위 : 공식에서 정의 및 사용 방법Apr 11, 2025 am 11:13 AM
Excel 이름 및 명명 범위 : 공식에서 정의 및 사용 방법Apr 11, 2025 am 11:13 AM이 튜토리얼은 Excel 이름의 기능을 명확히하고 셀, 범위, 상수 또는 공식의 이름을 정의하는 방법을 보여줍니다. 또한 정의 된 이름을 편집, 필터링 및 삭제하는 것도 다룹니다. Excel 이름은 엄청나게 유용하지만 종종 오버로입니다
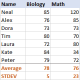 표준 편차 Excel : 기능 및 공식 예제Apr 11, 2025 am 11:01 AM
표준 편차 Excel : 기능 및 공식 예제Apr 11, 2025 am 11:01 AM이 튜토리얼은 표준 편차와 평균의 표준 오차의 차이점을 명확히하여 표준 편차 계산을위한 최적의 Excel 함수를 안내합니다. 설명 통계에서 평균 및 표준 편차는 Intrinsi입니다.
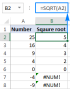 Excel의 제곱근 : SQRT 기능 및 기타 방법Apr 11, 2025 am 10:34 AM
Excel의 제곱근 : SQRT 기능 및 기타 방법Apr 11, 2025 am 10:34 AM이 Excel 튜토리얼은 정사각형 뿌리와 Nth 뿌리를 계산하는 방법을 보여줍니다. 제곱근을 찾는 것은 일반적인 수학적 작동이며 Excel은 몇 가지 방법을 제공합니다. Excel에서 사각형 뿌리를 계산하는 방법 : SQRT 기능 사용 : the
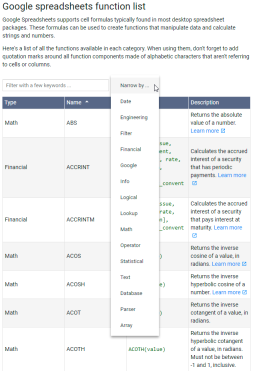 Google Sheets Basics : Google 스프레드 시트에서 작업하는 방법을 배우십시오.Apr 11, 2025 am 10:23 AM
Google Sheets Basics : Google 스프레드 시트에서 작업하는 방법을 배우십시오.Apr 11, 2025 am 10:23 AMGoogle Sheets : 초보자 가이드의 힘을 잠금 해제하십시오 이 튜토리얼은 MS Excel에 대한 강력하고 다양한 대안 인 Google Sheets의 기본 사항을 소개합니다. 스프레드 시트를 쉽게 관리하고, 주요 기능을 활용하며, 협업하는 방법에 대해 알아보십시오.


핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

PhpStorm 맥 버전
최신(2018.2.1) 전문 PHP 통합 개발 도구

Eclipse용 SAP NetWeaver 서버 어댑터
Eclipse를 SAP NetWeaver 애플리케이션 서버와 통합합니다.

MinGW - Windows용 미니멀리스트 GNU
이 프로젝트는 osdn.net/projects/mingw로 마이그레이션되는 중입니다. 계속해서 그곳에서 우리를 팔로우할 수 있습니다. MinGW: GCC(GNU Compiler Collection)의 기본 Windows 포트로, 기본 Windows 애플리케이션을 구축하기 위한 무료 배포 가능 가져오기 라이브러리 및 헤더 파일로 C99 기능을 지원하는 MSVC 런타임에 대한 확장이 포함되어 있습니다. 모든 MinGW 소프트웨어는 64비트 Windows 플랫폼에서 실행될 수 있습니다.

VSCode Windows 64비트 다운로드
Microsoft에서 출시한 강력한 무료 IDE 편집기

