



Excel에서 회귀 분석을 수행하는 방법
Excel에서 회귀 분석을 수행하면 데이터 분석 도구가 활용됩니다. 설치하지 않은 경우 먼저 활성화해야합니다. 파일> 옵션> 추가 인으로 이동하십시오. 하단에서 "Excel Add-Ins"를 선택하고 "GO"를 클릭하십시오. "Analysis Toolpak"옆에있는 상자를 확인하고 "확인"을 클릭하십시오.
이제 선형 회귀를 수행합시다.
- 데이터 준비 : 데이터를 두 열로 구성하십시오. 첫 번째 열은 독립 변수 (x)를 나타내고, 두 번째 열은 종속 변수 (y)를 나타냅니다. 결 측값이 없는지 확인하십시오.
- 데이터 분석에 액세스하십시오. 도구 PAK : "데이터"탭으로 이동하여 "데이터 분석"을 클릭하십시오. "회귀"를 선택하고 "확인"을 클릭하십시오.
-
데이터 입력 : 회귀 대화 상자에서 :
- 입력 y 범위 : 종속 변수 (y) 데이터가 포함 된 범위를 선택하십시오.
- 입력 X 범위 : 독립 변수 (x) 데이터를 포함하는 범위를 선택하십시오.
- 레이블 : 데이터 범위에 열 헤더가 포함 된 경우이 상자를 확인하십시오.
- 신뢰 수준 : 일반적으로 이것을 95%로 남겨 두십시오.
- 출력 범위 : 회귀 출력을 배치하려는 셀을 지정하십시오. 또는 "새로운 워크 시트 플라이"또는 "새로운 통합 문서"를 선택할 수 있습니다.
- 잔차 : 잔차를보고 싶다면이 상자를 확인하십시오 (실제 값과 예측 값의 차이). 다른 옵션 (표준화 된 잔차 등)은 진단에 유용 할 수 있지만 기본 분석을위한 선택 사항입니다.
- 라인 핏 플롯 : 회귀선과 데이터 포인트를 시각적으로 표현한이 상자를 확인하십시오.
- 정상적인 확률 플롯 : 이것은 잔차의 정규성을 평가하는 데 유용합니다.
- "확인"을 클릭하십시오 : Excel은 포괄적 인 회귀 출력 테이블을 생성합니다.
Excel에서 회귀 분석을 수행 할 때 피해야 할 일반적인 함정은 무엇입니까?
Excel에서 회귀 분석을 수행 할 때 몇 가지 함정이 부정확하거나 오해의 소지가있는 결과로 이어질 수 있습니다.
- 잘못된 데이터 준비 : 결 측값, 특이 치 및 비선형 관계는 회귀 모델의 정확도에 크게 영향을 줄 수 있습니다. 분석을 실행하기 전에 특이 치에 대한 데이터를주의 깊게 검사하고 적절하게 처리하십시오 (예 : 제거, 변환). 결 측값은 종종 영향을받는 데이터 포인트의 대치 또는 제거가 필요합니다.
- 가정 무시 : 선형 회귀는 선형성, 오류의 독립성, 동질 세대 성 (일정한 오류 분산) 및 오류의 정규성을 포함한 몇 가지 주요 가정에 의존합니다. 이러한 가정을 위반하면 편향적이고 비효율적 인 추정이 발생할 수 있습니다. 잔류 플롯 (회귀 출력에서 사용 가능)은 이러한 가정을 평가하는 데 도움이 될 수 있습니다.
- 너무 많은 독립 변수를 포함 시키면 과적 으로 너무 적합 할 수 있습니다. 여기서 모델은 샘플 데이터에 매우 적합하지만 새로운 데이터에 대해 제대로하지 못합니다. 단계적 회귀와 같은 기술을 사용하거나 모델 선택 기준 (AIC 또는 BIC와 같은)을 고려하여 parsimonious 모델을 찾습니다.
- 원인과 상관 관계 : 회귀 분석은 원인이 아닌 상관 관계를 보여줍니다. 두 변수가 상관 관계가 있다고해서 하나는 다른 하나를 원인이 아닙니다. 결과에 영향을 줄 수있는 다른 요소를 고려하십시오.
- R- 제곱 오해 : 높은 R- 제곱이 반드시 좋은 모델을 나타내는 것은 아닙니다. 독립 변수에 의해 설명 된 종속 변수의 분산 비율 만 측정합니다. 관련이없는 변수를 가진 높은 R- 제곱은 여전히 열악한 모델입니다.
- 다중 공학 성 점검하지 않음 : 독립 변수가 높은 상관 관계가있는 경우 불안정하고 신뢰할 수없는 회귀 계수로 이어질 수 있습니다. 분산 인플레이션 요인 (VIF)을 사용한 다중 공선 성을 확인하십시오. Excel은 VIF를 직접 계산하지는 않지만 다른 통계 소프트웨어 또는 추가 기능을 사용하여 계산할 수 있습니다.
R- 제곱 값과 기타 회귀 출력을 Excel에서 어떻게 해석 할 수 있습니까?
Excel 회귀 출력은 몇 가지 주요 통계를 제공합니다.
- R- 제곱 : 독립 변수에 의해 설명 된 종속 변수의 분산 비율을 나타냅니다. 높은 R- 제곱 (1에 가까운)은 더 잘 맞는 것을 나타냅니다. 그러나 앞에서 언급했듯이 좋은 모델의 유일한 지표는 아닙니다.
- 조정 된 R- 제곱 : 모델의 독립 변수 수를 조정하는 수정 된 R- 제곱 버전. 관련이없는 변수의 포함을 처벌하며 일반적으로 R- 제곱보다 선호됩니다.
- 회귀 계수 (계수) : 종속 변수에 대한 각각의 독립 변수의 추정 효과를 나타냅니다. 예를 들어, "x"에 대한 2의 계수는 "x"의 1 단위 증가가 다른 변수를 일정하게 유지하는 "y"의 2 단위 증가와 관련이 있음을 의미합니다.
- 표준 오류 : 추정 회귀 계수의 변동성을 측정합니다. 표준 오류가 더 작은 것은보다 정확한 추정치를 나타냅니다.
- T-Statistic 및 P- 값 : 각 회귀 계수의 통계적 유의성을 테스트하는 데 사용됩니다. 낮은 p- 값 (일반적으로 0.05 미만)은 계수가 통계적으로 유의하다는 것을 시사합니다. 즉, 모집단에서는 0이 아닐 것입니다.
- F-statistic 및 p- 값 : 회귀 모델의 전반적인 중요성을 테스트합니다. 낮은 p- 값은 모델 전체가 통계적으로 유의하다는 것을 나타냅니다.
- 잔차 : 종속 변수의 실제와 예측 값의 차이. 잔차를 검사하면 회귀 모델의 가정을 평가하는 데 도움이됩니다.
다른 유형의 데이터에 대한 Excel에서 회귀 분석을위한 몇 가지 대안적인 방법은 무엇입니까?
선형 회귀가 널리 사용되지만 모든 유형의 데이터에 항상 적합한 것은 아닙니다. Excel은 대체 방법에 대한 제한된 직접 지원을 제공하지만보다 고급 기술을 위해 추가 인 또는 기타 소프트웨어를 사용할 수 있습니다.
- 비선형 회귀 : 변수 간의 관계가 비선형 인 경우 비선형 회귀가 필요할 수 있습니다. Excel은 이것을 직접 지원하지 않지만 Solver Add-in을 사용하여 가장 적합한 비선형 모델을 찾을 수 있습니다.
- 로지스틱 회귀 : 이진 의존 변수 (예 : 0 또는 1)의 경우 로지스틱 회귀가 적절합니다. Excel에는이를위한 내장 기능이 없지만 추가 인 또는 기타 통계 소프트웨어를 사용할 수 있습니다.
- 포아송 회귀 : 카운트 데이터에 사용됩니다 (예 : 이벤트 수). 다시, Excel은 이것을 직접 지원하지 않지만 외부 소프트웨어가 필요합니다.
- 시계열 분석 : 시간이 지남에 따라 수집 된 데이터의 경우 ARIMA 모델과 같은 시계열 분석 기술이 더 적합합니다. Excel의 기능은 여기서 제한됩니다. 특수 통계 소프트웨어가 권장됩니다.
- 데이터 변환 : 선형 회귀를 적용하기 전에 모델의 가정을 충족 시키거나 비선형 관계를 선형화하려면 데이터 (예 : 로그 변환)를 변환해야 할 수도 있습니다. Excel은 다양한 데이터 변환에 대한 기능을 제공합니다.
적용하기 전에 항상 데이터를 신중하게 고려하고 통계 방법의 가정과 한계를 연구해야합니다. 복잡한 분석의 경우 R 또는 SPSS와 같은보다 전문화 된 통계 소프트웨어 패키지를 사용하는 것을 고려하십시오.
위 내용은 Excel에서 회귀 분석을 수행하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

 Excel의 중간 공식 - 실제 예Apr 11, 2025 pm 12:08 PM
Excel의 중간 공식 - 실제 예Apr 11, 2025 pm 12:08 PM이 튜토리얼은 중간 기능을 사용하여 Excel에서 수치 데이터의 중앙값을 계산하는 방법을 설명합니다. 중앙 경향의 주요 척도 인 중앙값은 데이터 세트의 중간 값을 식별하여 Central Tenden의보다 강력한 표현을 제공합니다.
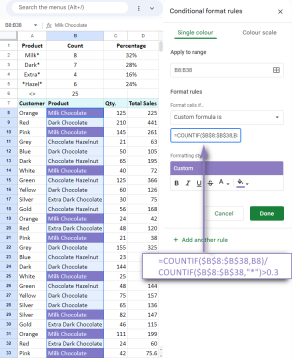 Google 스프레드 시트 Countif 기능은 공식 예제와 함께합니다Apr 11, 2025 pm 12:03 PM
Google 스프레드 시트 Countif 기능은 공식 예제와 함께합니다Apr 11, 2025 pm 12:03 PM마스터 Google Sheets Countif : 포괄적 인 가이드 이 안내서는 Google 시트의 다목적 카운티프 기능을 탐색하여 간단한 셀 카운팅 이외의 응용 프로그램을 보여줍니다. 우리는 정확하고 부분적인 경기에서 Han에 이르기까지 다양한 시나리오를 다룰 것입니다.
 Excel 공유 통합 문서 : 여러 사용자를위한 Excel 파일을 공유하는 방법Apr 11, 2025 am 11:58 AM
Excel 공유 통합 문서 : 여러 사용자를위한 Excel 파일을 공유하는 방법Apr 11, 2025 am 11:58 AM이 튜토리얼은 다양한 방법, 액세스 제어 및 갈등 해결을 다루는 Excel 통합 문서 공유에 대한 포괄적 인 안내서를 제공합니다. Modern Excel 버전 (2010, 2013, 2016 및 이후) 협업 편집을 단순화하여 M에 대한 필요성을 제거합니다.
 Excel을 JPG로 변환하는 방법 - 이미지 파일로 .xls 또는 .xlsx를 저장Apr 11, 2025 am 11:31 AM
Excel을 JPG로 변환하는 방법 - 이미지 파일로 .xls 또는 .xlsx를 저장Apr 11, 2025 am 11:31 AM이 자습서는 .xls 파일을 .jpg 이미지로 변환하는 다양한 방법을 탐색하여 내장 된 Windows 도구와 무료 온라인 변환기를 모두 포함합니다. 프레젠테이션을 만들거나 스프레드 시트 데이터를 단단히 공유하거나 문서를 디자인해야합니까? YO를 변환합니다
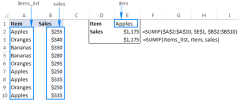 Excel 이름 및 명명 범위 : 공식에서 정의 및 사용 방법Apr 11, 2025 am 11:13 AM
Excel 이름 및 명명 범위 : 공식에서 정의 및 사용 방법Apr 11, 2025 am 11:13 AM이 튜토리얼은 Excel 이름의 기능을 명확히하고 셀, 범위, 상수 또는 공식의 이름을 정의하는 방법을 보여줍니다. 또한 정의 된 이름을 편집, 필터링 및 삭제하는 것도 다룹니다. Excel 이름은 엄청나게 유용하지만 종종 오버로입니다
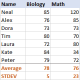 표준 편차 Excel : 기능 및 공식 예제Apr 11, 2025 am 11:01 AM
표준 편차 Excel : 기능 및 공식 예제Apr 11, 2025 am 11:01 AM이 튜토리얼은 표준 편차와 평균의 표준 오차의 차이점을 명확히하여 표준 편차 계산을위한 최적의 Excel 함수를 안내합니다. 설명 통계에서 평균 및 표준 편차는 Intrinsi입니다.
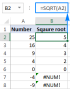 Excel의 제곱근 : SQRT 기능 및 기타 방법Apr 11, 2025 am 10:34 AM
Excel의 제곱근 : SQRT 기능 및 기타 방법Apr 11, 2025 am 10:34 AM이 Excel 튜토리얼은 정사각형 뿌리와 Nth 뿌리를 계산하는 방법을 보여줍니다. 제곱근을 찾는 것은 일반적인 수학적 작동이며 Excel은 몇 가지 방법을 제공합니다. Excel에서 사각형 뿌리를 계산하는 방법 : SQRT 기능 사용 : the
 Google Sheets Basics : Google 스프레드 시트에서 작업하는 방법을 배우십시오.Apr 11, 2025 am 10:23 AM
Google Sheets Basics : Google 스프레드 시트에서 작업하는 방법을 배우십시오.Apr 11, 2025 am 10:23 AMGoogle Sheets : 초보자 가이드의 힘을 잠금 해제하십시오 이 튜토리얼은 MS Excel에 대한 강력하고 다양한 대안 인 Google Sheets의 기본 사항을 소개합니다. 스프레드 시트를 쉽게 관리하고, 주요 기능을 활용하며, 협업하는 방법에 대해 알아보십시오.


핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

ZendStudio 13.5.1 맥
강력한 PHP 통합 개발 환경

맨티스BT
Mantis는 제품 결함 추적을 돕기 위해 설계된 배포하기 쉬운 웹 기반 결함 추적 도구입니다. PHP, MySQL 및 웹 서버가 필요합니다. 데모 및 호스팅 서비스를 확인해 보세요.

SecList
SecLists는 최고의 보안 테스터의 동반자입니다. 보안 평가 시 자주 사용되는 다양한 유형의 목록을 한 곳에 모아 놓은 것입니다. SecLists는 보안 테스터에게 필요할 수 있는 모든 목록을 편리하게 제공하여 보안 테스트를 더욱 효율적이고 생산적으로 만드는 데 도움이 됩니다. 목록 유형에는 사용자 이름, 비밀번호, URL, 퍼징 페이로드, 민감한 데이터 패턴, 웹 셸 등이 포함됩니다. 테스터는 이 저장소를 새로운 테스트 시스템으로 간단히 가져올 수 있으며 필요한 모든 유형의 목록에 액세스할 수 있습니다.

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

DVWA
DVWA(Damn Vulnerable Web App)는 매우 취약한 PHP/MySQL 웹 애플리케이션입니다. 주요 목표는 보안 전문가가 법적 환경에서 자신의 기술과 도구를 테스트하고, 웹 개발자가 웹 응용 프로그램 보안 프로세스를 더 잘 이해할 수 있도록 돕고, 교사/학생이 교실 환경 웹 응용 프로그램에서 가르치고 배울 수 있도록 돕는 것입니다. 보안. DVWA의 목표는 다양한 난이도의 간단하고 간단한 인터페이스를 통해 가장 일반적인 웹 취약점 중 일부를 연습하는 것입니다. 이 소프트웨어는

