
LLM RAG : AI 기반 파일 리더 어시스턴트 생성

- Linda Hamilton원래의
- 2025-03-04 10:40:11508검색
소개
ai는 어디에나 있습니다.
최소한 하루에 한 번 큰 언어 모델 (LLM)과 상호 작용하지 않는 것은 어렵습니다. 챗봇은 여기에 있습니다. 그들은 당신의 앱에 있고, 더 나은 글을 쓰고, 이메일을 작성하고, 이메일을 읽도록 도와줍니다. 글쎄, 그들은 많이합니다.
.
on-of-the-box
를 사용하는 경우 그다지 유용하지 않은 경우-즉, 답을 알지 못할 것입니다. 따라서 조정이 필요합니다.
실제로는 아닙니다. 그때는 검색된 세대 (RAG)가 유용 해지는 시점입니다
rag는 외부 지식 기반에서 정보를 얻는 것을 큰 언어 모델 (LLM)과 결합하는 프레임 워크입니다. AI 모델이보다 정확하고 관련성있는 응답을 생성하는 데 도움이됩니다.<.> 나는 영화를 좋아한다. 과거에 한동안, 나는 오스카상에서 최고의 영화 카테고리 나 최고의 배우 및 여배우에서 어떤 영화가 경쟁하고 있는지 알았습니다. 그리고 나는 그해에 어떤 사람들이 동상을 얻었는지 확실히 알 것입니다. 그러나 지금 나는 그 주제에 대해 모두 녹슬 었습니다. 누가 경쟁하고 있는지 물어 본다면 알지 못할 것입니다. 그리고 내가 당신에게 대답하려고 시도하더라도, 나는 당신에게 약한 반응을 줄 것입니다.
는 사전 처리 된 정보를 LLM에 통합합니다
<em>
> 왜 헝겊을 사용합니까?
<know> 이제 우리는 헝겊 프레임 워크가 무엇인지 알았으므로 왜 우리가 그것을 사용해야하는지 이해해야합니다.
<of> 다음은 다음과 같습니다.
</of></know></em>
<ual> 실제 데이터를 참조하여 사실 정확도를 향상시킵니다
<l> Rag는 LLMS가 처리하고 지식을 통합하여보다 관련성있는 답변을 만들 수 있습니다.
<l> rag는 LLM이 내부 조직 데이터와 같은 추가 지식 기반에 액세스하는 데 도움이 될 수 있습니다.
<l> rag는 LLM이보다 정확한 도메인 별 컨텐츠를 생성하는 데 도움이 될 수 있습니다 <strong>
<reduce> Rag는 지식 격차와 AI 환각을 줄이는 데 도움이 될 수 있습니다
</reduce></strong>
<expl> 이전에 설명했듯이, 나는 Rag Framework를 사용하여 지식 기반에 추가하려는 컨텐츠에 대해 내부 검색 엔진을 제공하고 있다고 말하고 싶습니다.
<strong> 음. 그 모든 것은 매우 흥미 롭습니다. 그러나 헝겊의 적용을 보자. 우리는 AI 기반 PDF 리더 보조원을 만드는 방법을 배웁니다. </strong>
</expl></l></l></l></ual>
PDF 파일을로드하여 텍스트 청크로 분할합니다.
를 생성해야합니다. 계정을 처음 만들 때 무료 크레딧을받을 수 있습니다. 그러나 한동안 가지고 있다면 OpenAI의 API에 액세스하려면 5 달러의 크레딧을 추가해야 할 수도 있습니다. 옵션은 Hugging Face의 임베딩을 사용하는 것입니다
.
.
→ 입력 텍스트가 수신됩니다
2️ 2 → 검색된 문서가 입력에 추가됩니다.
4️ 4 4
데이터 준비
a
.
# Imports
from langchain_community.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
def load_document(pdf):
# Load a PDF
"""
Load a PDF and split it into chunks for efficient retrieval.
:param pdf: PDF file to load
:return: List of chunks of text
"""
loader = PyPDFLoader(pdf)
docs = loader.load()
# Instantiate Text Splitter with Chunk Size of 500 words and Overlap of 100 words so that context is not lost
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=100)
# Split into chunks for efficient retrieval
chunks = text_splitter.split_documents(docs)
# Return
return chunks
# Imports
from langchain_community.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
def load_document(pdf):
# Load a PDF
"""
Load a PDF and split it into chunks for efficient retrieval.
:param pdf: PDF file to load
:return: List of chunks of text
"""
loader = PyPDFLoader(pdf)
docs = loader.load()
# Instantiate Text Splitter with Chunk Size of 500 words and Overlap of 100 words so that context is not lost
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=100)
# Split into chunks for efficient retrieval
chunks = text_splitter.split_documents(docs)
# Return
return chunks
# Imports
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
from langchain.chains import create_retrieval_chain
from langchain_openai import ChatOpenAI
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain_core.prompts import ChatPromptTemplate
from scripts.secret import OPENAI_KEY
from scripts.document_loader import load_document
import streamlit as st
그리고 이것은 당신이 파일 리더 ai 어시스턴트를 볼 수있는 gif입니다! # Create a Streamlit app
st.title("AI-Powered Document Q&A")
# Load document to streamlit
uploaded_file = st.file_uploader("Upload a PDF file", type="pdf")
# If a file is uploaded, create the TextSplitter and vector database
if uploaded_file :
# Code to work around document loader from Streamlit and make it readable by langchain
temp_file = "./temp.pdf"
with open(temp_file, "wb") as file:
file.write(uploaded_file.getvalue())
file_name = uploaded_file.name
# Load document and split it into chunks for efficient retrieval.
chunks = load_document(temp_file)
# Message user that document is being processed with time emoji
st.write("Processing document... :watch:") 사용자 query 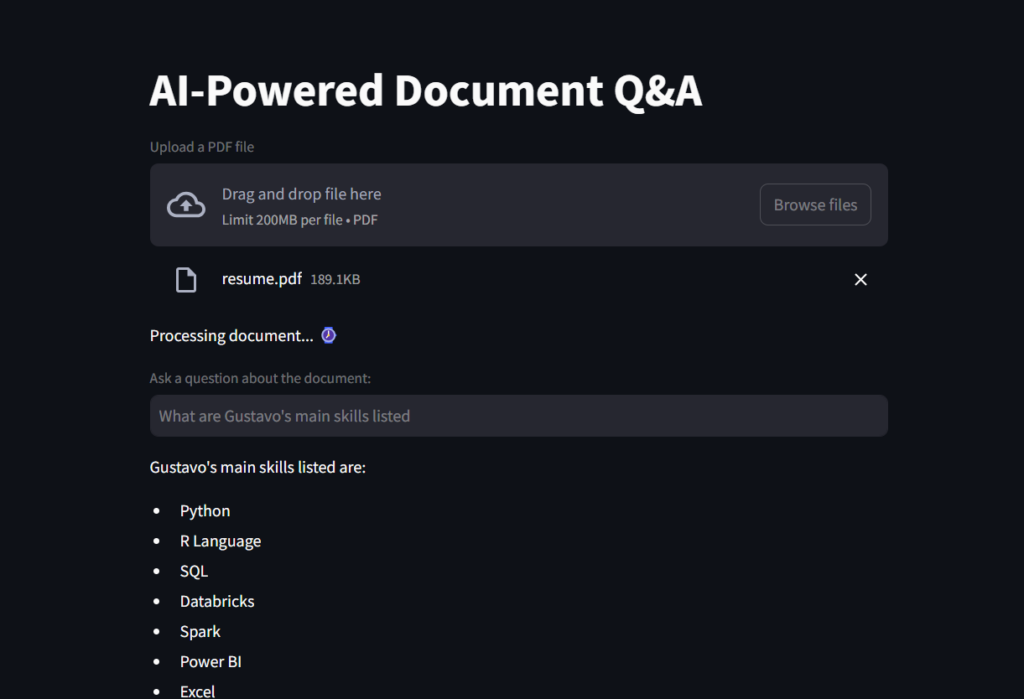 encment context
encment context  → LLM은 결합 된 입력을 처리하고 답을 생성합니다.
→ LLM은 결합 된 입력을 처리하고 답을 생성합니다.
나에 대해
위 내용은 LLM RAG : AI 기반 파일 리더 어시스턴트 생성의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!