




안녕하세요 여러분, 제 이름은 sea_turt1e입니다.
이 기사에서는 제가 매우 좋아하는 스포츠인 NBA(National Basketball League)에서 선수 케미스트리를 예측하기 위해 머신러닝 모델을 구축하는 과정과 결과를 공유하겠습니다.
개요
- GNN(그래프 신경망)을 사용하여 플레이어 케미스트리를 예측합니다.
- 곡선 아래 면적(AUC)이 평가 지표로 사용됩니다.
- 수렴 시 AUC는 약 0.73입니다.
- 훈련 데이터는 1996-97시즌부터 2021-22시즌까지이며, 테스트에는 2022-23시즌의 데이터가 사용됩니다.
참고: NBA 정보
NBA에 익숙하지 않은 독자에게는 이 기사의 일부가 이해하기 어려울 수 있습니다. "화학반응"은 보다 직관적인 관점에서 이해될 수 있습니다. 또한 이 기사는 NBA에 초점을 맞추고 있지만 이 방법은 다른 스포츠 및 심지어 대인 관계 화학 예측에도 적용될 수 있습니다.
화학반응 예측 결과
먼저 예측 결과를 살펴보겠습니다. 데이터 세트와 기술적인 세부 사항에 대해서는 나중에 자세히 설명하겠습니다.
변과 분수에 대한 설명
화학 반응 예측에서 빨간색 가장자리는 좋은 화학 반응을 나타내고, 검은색 가장자리는 중간 정도의 화학 반응을 나타내며, 파란색 가장자리는 나쁜 화학 반응을 나타냅니다.
옆의 분수는 0~1 범위의 화학 반응 점수를 나타냅니다.
스타선수들의 케미스트리 예측
스타선수들의 케미스트리 예측은 이렇습니다. 그래프에는 같은 팀에서 플레이한 적이 없는 플레이어 쌍만 포함됩니다.
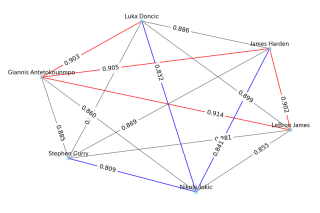
한 번도 같이 뛴 적이 없는 스타플레이어들의 예측을 보면, 결과가 늘 직관적이지 않을 수도 있다.
예를 들어 르브론 제임스와 스테판 커리는 올림픽에서 뛰어난 호흡을 보여 좋은 케미스트리를 보여줬다. 반면 니콜라 요키치는 놀랍게도 다른 선수들과 케미스트리가 좋지 않을 것으로 예상된다.
2022-23시즌 주요 트레이드에 대한 케미스트리 예측
예측을 현실에 더 가깝게 만들기 위해 2022-23 시즌 실제 거래에서 선수 간의 케미스트리를 테스트했습니다.
트레이닝 데이터에는 2022~23시즌의 데이터가 포함되지 않기 때문에 현실적인 인상과 일치하는 예측이 모델의 효율성을 나타낼 수 있습니다.
2022-23시즌에는 몇 가지 중요한 거래가 진행됩니다.
케빈 듀란트, 카이리 어빙, 루이 하치무라 등 핵심 선수들의 예측은 다음과 같습니다.
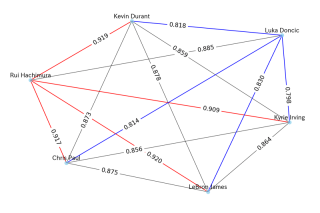
새 팀의 케미스트리 예측은 다음과 같습니다.
- 레이커스: 하치무라 루이 – 르브론 제임스(빨간색 가장자리: 좋은 케미스트리)
- 선즈: 케빈 듀란트 – 크리스 폴(블랙 사이드: 중간 케미스트리)
- 매버릭스: 카이리 어빙 – 루카 돈치치(파란색 면: 열악한 케미스트리)
2022-23시즌의 역학관계를 고려하면 이 결과는 꽤 정확한 것으로 보입니다. (다음 시즌에는 Suns와 Mavericks의 상황이 바뀌었지만)
기술적 세부사항
다음으로 GNN 프레임워크 및 데이터 세트 준비를 포함한 기술적인 측면을 설명하겠습니다.
GNN이란 무엇인가요?
GNN(Graph Neural Network)은 그래프 구조의 데이터를 처리하도록 설계된 네트워크입니다.
이 모델에서는 "플레이어 간의 화학 반응"을 그래프 모서리로 표현하며, 학습 과정은 다음과 같습니다.
- 직접 측면: 어시스트 수가 더 많은 플레이어 쌍입니다.
- 부정적 측면: 어시스트 수가 적은 두 명의 플레이어.
부정적인 에지의 경우 모델은 '어시스트가 낮은 팀원'을 우선시하고 '다른 팀의 선수'의 영향력을 약화시킵니다.
AUC란 무엇인가요?
AUC(area under the curve)는 ROC 곡선 아래의 면적을 말하며 모델 성능을 평가하는 지표로 사용됩니다.
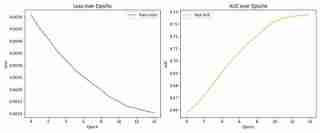
AUC가 1에 가까울수록 정확도가 높아집니다. 이 연구에서 모델의 AUC는 약 0.73으로 중간에서 평균 이상의 결과를 보였습니다.
학습 곡선 및 AUC 진행
다음은 훈련 과정 중 학습 곡선과 AUC 진행 상황입니다.
데이터세트
주요 혁신은 데이터 세트 구성에 있습니다.
케미스트리를 정량화하자면 '높은 어시스트'는 좋은 케미스트리를 의미한다고 가정합니다. 이러한 가정을 바탕으로 데이터 세트는 다음과 같이 구성됩니다.
- 긍정적인 측면: 어시스트 수가 많은 선수.
- 부정적인 측면: 어시스트가 낮은 선수.
또한 어시스트 횟수가 낮은 팀원은 조직력이 좋지 않은 것으로 간주됩니다.
코드 세부정보
모든 코드는 GitHub에서 사용할 수 있습니다.
README의 지침에 따라 학습 과정을 재현하고 여기에 설명된 그래프를 그릴 수 있습니다.
https://www.php.cn/link/867079fcaff2dfddeb29ca1f27853ef7
향후 전망
아직 개선의 여지가 있으며 다음과 같은 목표를 달성할 계획입니다.
-
화학반응의 정의를 확장
- 어시스트 이상의 요소를 통합하여 플레이어 관계를 더욱 정확하게 포착하세요.
-
정확도 향상
- 더 나은 훈련 방법과 확장된 데이터 세트를 통해 AUC를 개선합니다.
-
통합 자연어 처리
- 플레이어 인터뷰와 소셜 미디어 게시물을 분석하여 새로운 관점을 추가하세요.
-
영어로 기사 작성
- 더 넓은 해외 시청자에게 다가가기 위해 콘텐츠를 영어로 게시합니다.
-
그래프 시각화를 위한 GUI 개발
- 사용자가 플레이어의 케미스트리를 대화형으로 탐색할 수 있는 웹 애플리케이션을 만듭니다.
결론
이 글에서는 NBA 선수 케미스트리를 예측하려는 나의 시도를 설명합니다.
아직 모델이 개발 중인 동안, 더욱 개선하여 더욱 흥미로운 결과를 얻을 수 있기를 바랍니다.
댓글 영역에 여러분의 생각과 제안을 남겨주세요!
추가 개선이 필요한 경우 알려주세요!
위 내용은 그래프 신경망을 사용하여 NBA 선수 조직력 예측의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

 파이썬 : 편집과 해석에 대한 깊은 다이빙May 12, 2025 am 12:14 AM
파이썬 : 편집과 해석에 대한 깊은 다이빙May 12, 2025 am 12:14 AMPythonusesahybridmodelofilationandlostretation : 1) ThePyThoninterPretreCeterCompileSsourcodeIntOplatform-IndependentBecode.
 Python은 해석 된 또는 편집 된 언어입니까? 왜 중요한가?May 12, 2025 am 12:09 AM
Python은 해석 된 또는 편집 된 언어입니까? 왜 중요한가?May 12, 2025 am 12:09 AMPythonisbothingretedandcompiled.1) 1) it 'scompiledtobytecodeforportabilityacrossplatforms.2) thebytecodeisthentenningreted, withfordiNamictyTeNgreted, WhithItmayBowerShiledlanguges.

 루프를위한 것 및 기간 : 실용 가이드May 12, 2025 am 12:07 AM
루프를위한 것 및 기간 : 실용 가이드May 12, 2025 am 12:07 AMforloopsareusedwhendumberofitessiskNowninadvance, whilewhiloopsareusedwhentheationsdepernationsorarrays.2) whiloopsureatableforscenarioScontiLaspecOndCond
 파이썬 : 진정으로 해석 되었습니까? 신화를 파악합니다May 12, 2025 am 12:05 AM
파이썬 : 진정으로 해석 되었습니까? 신화를 파악합니다May 12, 2025 am 12:05 AMpythonisnotpurelynlogreted; itusesahybrideprophorfbyodecodecompilationandruntime -INGRETATION.1) pythoncompilessourcecodeintobytecode, thepythonVirtualMachine (pvm)
 동일한 요소를 가진 Python Concatenate 목록May 11, 2025 am 12:08 AM
동일한 요소를 가진 Python Concatenate 목록May 11, 2025 am 12:08 AMToconcatenatelistsinpythonwithesameElements, 사용 : 1) OperatorTokeEpduplicates, 2) asettoremovedUplicates, or3) listComperensionForControlOverDuplicates, 각 methodHasDifferentPerferformanCeanDorderImpestications.
 해석 대 컴파일 언어 : Python 's PlaceMay 11, 2025 am 12:07 AM
해석 대 컴파일 언어 : Python 's PlaceMay 11, 2025 am 12:07 AMPythonisancerpretedLanguage, 비판적 요소를 제시하는 PytherfaceLockelimitationsIncriticalApplications.1) 해석 된 언어와 같은 thePeedBackandbackandrapidProtoTyping.2) CompilledlanguagesLikec/C transformt 해석
 루프를 위해 및 while 루프 : 파이썬에서 언제 각각을 사용합니까?May 11, 2025 am 12:05 AM
루프를 위해 및 while 루프 : 파이썬에서 언제 각각을 사용합니까?May 11, 2025 am 12:05 AMuseforloopswhhenmerfiterationsiskNownInAdvance 및 WhileLoopSweHeniTesslationsDepoyConditionismet whilEroopsSuitsCenarioswhereTheLoopScenarioswhereTheLoopScenarioswhereTheLoopScenarioswhereTherInatismet, 유용한 광고 인 푸트 gorit


핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

SublimeText3 Linux 새 버전
SublimeText3 Linux 최신 버전

WebStorm Mac 버전
유용한 JavaScript 개발 도구

