
Python 튜토리얼 - ata 구조

- DDD원래의
- 2024-12-23 19:36:15337검색
소개
데이터 구조는 데이터를 정리하는 도구입니다. 저장뿐만 아니라 일부 문제를 해결하기 위해서도 사용됩니다. Python에는 목록, 사전, 튜플 및 집합을 포함한 일부 데이터 구조가 있습니다.
목록
리스트는 인덱스를 사용해 항목을 순차적으로 저장하는 데이터 구조입니다. 목록 데이터 구조의 그림입니다.

Python에서 목록을 만드는 방법은 여러 가지가 있습니다.
- 목록 내에서 직접 값을 초기화합니다.
items = [1,2,3,4]
- 빈 목록을 초기화합니다.
items = []
목록 안의 항목은 인덱스를 통해 직접 접근할 수 있습니다.
items = [1,2,3,4,5] # access item at index 2 result = items[2] print(result) # returns 3
목록 내의 모든 항목은 for 루프를 사용하여 검색할 수 있습니다. 예시입니다.
# create a new list
items = [1,2,3,4,5]
# retrieve each item inside a list
for item in items:
print(item)
출력
1 2 3 4 5
위의 코드를 바탕으로 항목이 할당된 항목이라는 목록이 생성됩니다. 각 항목은 for 루프를 사용하여 검색됩니다.
기본 작업 나열
append() 함수는 목록에 새 항목을 추가합니다. Append() 사용법의 예입니다.
# create empty list
shopping_list = []
# add some items
shopping_list.append("apple")
shopping_list.append("milk")
shopping_list.append("cereal")
# retrieve all items
for item in shopping_list:
print(item)
출력
apple milk cereal
append()는 아래 그림과 같습니다.

append() 함수 외에 insert() 함수는 특정 인덱스에 새 항목을 추가합니다. 예시입니다.
items = ["apple","banana","mango","coffee"]
# add new item at index 1
items.insert(1,"cereal")
# retrieve all items
for item in items:
print(item)
출력
apple cereal banana mango coffee
아래 그림은 insert()를 예시한 것입니다.

목록 내의 항목을 업데이트하는 것은 간단합니다. 항목의 인덱스를 지정한 다음 업데이트된 항목으로 변경하면 됩니다.
# create a list
drinks = ["milkshake","black tea","banana milk","mango juice"]
# update value at index 2
drinks[2] = "chocolate milk"
print(f"value at index 2: {drinks[2]}")
출력
value at index 2: chocolate milk
remove() 함수는 목록에서 항목을 제거합니다. 예시입니다.
items = ["apple","banana","mango","coffee"]
# remove "mango"
items.remove("mango")
# remove item at index 1
items.remove(items[1])
print("after removed")
for item in items:
print(item)
출력
after removed apple coffee
목록의 시작 인덱스와 끝 인덱스를 지정하여 목록 내의 항목을 선택할 수 있습니다. 목록에서 항목을 선택하는 기본 구조입니다.
list_name[start:end]
항목은 시작 인덱스부터 끝 인덱스까지 선택되지만 끝 인덱스는 포함되지 않습니다. 목록에서 항목을 선택하는 예시입니다.
items = ["apple","mango","papaya","coconut","banana"]
# select items from index 1 up to but not including index 3
selected = items[1:3]
# show all items
print(f"all items: {items}")
# show the selected items
print(f"selected: {selected}")
출력
all items: ['apple', 'mango', 'papaya', 'coconut', 'banana'] selected: ['mango', 'papaya']
목록 이해
List Comprehension은 목록을 생성하는 "기능적" 방법입니다. List Comprehension을 이해하기 위해 반복적 접근 방식을 사용하여 짝수 값을 포함하는 목록을 만드는 예를 살펴보겠습니다.
evens = []
for i in range(1,11):
evens.append(i*2)
print(evens)
출력
items = [1,2,3,4]
위 코드를 기반으로 for 루프를 사용한 반복 접근 방식을 사용하여 짝수를 생성합니다. 위의 예는 목록 이해를 사용하여도 달성할 수 있습니다. 리스트 컴프리헨션을 이용하여 짝수를 생성하는 예제입니다.
items = []
출력
items = [1,2,3,4,5] # access item at index 2 result = items[2] print(result) # returns 3
위의 코드를 기반으로 목록 이해 방식은 이전 반복 방식보다 더 간결한 코드와 동일한 결과를 제공합니다.
목록 이해는 if 분기와 함께 사용할 수 있습니다. 이 예에서는 특정 조건에 따라 특정 값을 필터링하는 데 List Comprehension이 사용됩니다.
# create a new list
items = [1,2,3,4,5]
# retrieve each item inside a list
for item in items:
print(item)
출력
1 2 3 4 5
이전 예의 반복 버전입니다.
# create empty list
shopping_list = []
# add some items
shopping_list.append("apple")
shopping_list.append("milk")
shopping_list.append("cereal")
# retrieve all items
for item in shopping_list:
print(item)
다차원 목록
목록은 행렬과 같은 다차원 접근 방식으로 저장될 수 있습니다. 숫자 행렬을 저장하기 위해 다차원 목록을 선언하는 예입니다.
apple milk cereal
기본 목록의 인덱스를 나타내는 x를 지정하고 중첩 목록 내의 항목 인덱스를 나타내는 y를 지정하여 이중 대괄호([x][y])를 사용하여 항목에 액세스할 수 있습니다. 숫자행렬의 그림입니다.
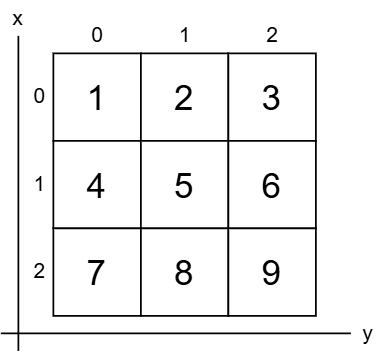
중첩된 for 루프를 활용하여 다차원 목록 내의 항목을 검색할 수 있습니다.
items = ["apple","banana","mango","coffee"]
# add new item at index 1
items.insert(1,"cereal")
# retrieve all items
for item in items:
print(item)
출력
apple cereal banana mango coffee
사전
사전은 레코드를 키-값 쌍으로 저장하는 데이터 구조입니다. 각 키는 고유해야 하며 중복 값은 허용됩니다. 이는 사전 데이터 구조를 보여줍니다.

사전을 만드는 방법에는 여러 가지가 있습니다.
- 초기화된 레코드로 사전을 만듭니다.
# create a list
drinks = ["milkshake","black tea","banana milk","mango juice"]
# update value at index 2
drinks[2] = "chocolate milk"
print(f"value at index 2: {drinks[2]}")
- 빈 사전을 만듭니다.
value at index 2: chocolate milk
사전 내부의 모든 레코드는 for 루프를 사용하여 검색할 수 있습니다. 예시입니다.
items = ["apple","banana","mango","coffee"]
# remove "mango"
items.remove("mango")
# remove item at index 1
items.remove(items[1])
print("after removed")
for item in items:
print(item)
출력
after removed apple coffee
사전 기본 작업
사전 안에 새 항목을 삽입하려면 항목의 키-값 쌍을 지정하세요. 키가 고유한지 확인하세요.
list_name[start:end]
사전 내부에 새로운 항목을 삽입하는 예시입니다.
items = ["apple","mango","papaya","coconut","banana"]
# select items from index 1 up to but not including index 3
selected = items[1:3]
# show all items
print(f"all items: {items}")
# show the selected items
print(f"selected: {selected}")
출력
all items: ['apple', 'mango', 'papaya', 'coconut', 'banana'] selected: ['mango', 'papaya']
사전 내의 항목을 업데이트하려면 항목의 키를 지정한 다음 업데이트된 값을 삽입하세요.
evens = []
for i in range(1,11):
evens.append(i*2)
print(evens)
출력
[2, 4, 6, 8, 10, 12, 14, 16, 18, 20]
사전의 키와 값은 다양한 방법을 사용하여 독립적으로 액세스할 수 있습니다.
evens = [x*2 for x in range(1,11)] # using list comprehension print(evens)
출력
items = [1,2,3,4]
pop() 메소드는 주어진 키를 기반으로 사전에서 항목을 제거합니다.
items = []
출력
items = [1,2,3,4,5] # access item at index 2 result = items[2] print(result) # returns 3
clear() 메소드는 사전 내부의 모든 항목을 제거합니다.
# create a new list
items = [1,2,3,4,5]
# retrieve each item inside a list
for item in items:
print(item)
출력
1 2 3 4 5
튜플
튜플은 많은 값을 저장하기 위한 불변 데이터 구조입니다. 튜플에는 변경 가능한 값이 포함될 수 있습니다. 새로운 튜플을 생성하는 방법은 두 가지가 있습니다.
- 할당된 값으로 튜플을 만듭니다.
# create empty list
shopping_list = []
# add some items
shopping_list.append("apple")
shopping_list.append("milk")
shopping_list.append("cereal")
# retrieve all items
for item in shopping_list:
print(item)
출력
apple milk cereal
- 빈 튜플을 만듭니다.
items = ["apple","banana","mango","coffee"]
# add new item at index 1
items.insert(1,"cereal")
# retrieve all items
for item in items:
print(item)
튜플 기본 작업
튜플은 불변입니다. 즉, 일단 생성되면 해당 값을 변경하거나 업데이트할 수 없습니다.
apple cereal banana mango coffee
튜플의 값은 "튜플 압축 풀기"를 사용하여 검색할 수 있습니다(이 개념은 JavaScript의 객체 구조 분해와 유사합니다).
언팩 시 언팩된 값의 크기는 튜플의 크기와 동일해야 합니다.
# create a list
drinks = ["milkshake","black tea","banana milk","mango juice"]
# update value at index 2
drinks[2] = "chocolate milk"
print(f"value at index 2: {drinks[2]}")
출력
value at index 2: chocolate milk
세트
세트는 고유한 항목만 포함하는 순서가 지정되지 않은 데이터 구조입니다. 세트를 만드는 방법은 다양합니다.
items = ["apple","banana","mango","coffee"]
# remove "mango"
items.remove("mango")
# remove item at index 1
items.remove(items[1])
print("after removed")
for item in items:
print(item)
set() 함수를 사용하여 빈 집합을 만들 수 있습니다.
after removed apple coffee
설정된 데이터 구조는 중복된 값을 자동으로 제거합니다.
list_name[start:end]
출력
items = ["apple","mango","papaya","coconut","banana"]
# select items from index 1 up to but not including index 3
selected = items[1:3]
# show all items
print(f"all items: {items}")
# show the selected items
print(f"selected: {selected}")
집합 내부의 값은 for 루프를 사용하여 액세스할 수 있습니다.
all items: ['apple', 'mango', 'papaya', 'coconut', 'banana'] selected: ['mango', 'papaya']
출력
evens = []
for i in range(1,11):
evens.append(i*2)
print(evens)
기본 작업 설정
집합 데이터 구조는 합집합, 교집합, 차이, 대칭차 등 다양한 연산을 제공합니다.
합집합 연산은 두 세트의 모든 항목을 반환합니다.

[2, 4, 6, 8, 10, 12, 14, 16, 18, 20]
출력
evens = [x*2 for x in range(1,11)] # using list comprehension print(evens)
교집합 연산은 집합의 교집합에 존재하는 모든 항목을 반환합니다.

[2, 4, 6, 8, 10, 12, 14, 16, 18, 20]
출력
samples = [12,32,55,10,2,57,66] result = [s for s in samples if s % 4 == 0] # using list comprehension print(result)
차이 연산은 특정 세트에만 존재하는 모든 항목을 반환합니다.

[12, 32]
출력
samples = [12,32,55,10,2,57,66]
result = []
for s in samples:
if s % 4 == 0:
result.append(s)
print(result)
대칭 차분 연산은 두 세트 중 하나에 존재하지만 교집합에는 존재하지 않는 모든 항목을 반환합니다.

matrix = [ [1,2,3], [4,5,6], [7,8,9], ]
출력
items = [1,2,3,4]
기능 소개
이 함수는 코드 중복을 줄이고 복잡한 작업을 구성하는 것을 목표로 하는 명령이 포함된 호출 가능한 단위입니다. void 함수(반환 값 없음)와 값을 반환하는 함수의 두 가지 유형이 있습니다.
파이썬의 기본 함수 구조입니다.
items = []
파이썬에서 void 함수(반환값 없음)의 예입니다.
items = [1,2,3,4,5] # access item at index 2 result = items[2] print(result) # returns 3
출력
# create a new list
items = [1,2,3,4,5]
# retrieve each item inside a list
for item in items:
print(item)
위 코드를 바탕으로 hello()라는 함수가 생성됩니다. 함수 이름 뒤에 괄호()를 붙여서 함수를 호출합니다.
반환값을 갖는 함수의 예시입니다.
1 2 3 4 5
출력
# create empty list
shopping_list = []
# add some items
shopping_list.append("apple")
shopping_list.append("milk")
shopping_list.append("cereal")
# retrieve all items
for item in shopping_list:
print(item)
위의 코드를 기반으로 두 숫자의 합을 계산하는 add()라는 함수가 생성됩니다. add() 함수의 반환 값은 결과 변수 내에 저장됩니다.
반환 값 기능을 사용할 때는 반환 값이 사용되고 있는지 확인하세요.
파이썬의 함수에 관한 주제는 별도의 장에서 자세히 설명하겠습니다.
예 - 간단한 할 일 목록 애플리케이션
간단한 할 일 목록 애플리케이션을 만들어 보겠습니다. 이 애플리케이션은 목록을 할일 저장 공간으로 사용하고 더욱 깔끔한 코드를 위해 기능을 활용합니다.
첫 번째 단계는 uuid 패키지를 가져오고 할 일 레코드를 저장하기 위한 todos라는 목록을 만드는 것입니다. uuid 패키지는 todo 레코드의 식별자(ID)로 사용됩니다.
apple milk cereal
그런 다음 모든 할일 기록을 검색하는 view_todos() 함수를 만듭니다. 모든 할 일 레코드는 for 루프를 사용하여 검색됩니다.
items = ["apple","banana","mango","coffee"]
# add new item at index 1
items.insert(1,"cereal")
# retrieve all items
for item in items:
print(item)
지정된 ID로 할일 레코드를 검색하는 view_todo() 함수를 만듭니다. 각 할일 레코드는 for 루프 내에서 검사되어 현재 할 일 ID가 지정된 ID와 같은지 확인합니다. 일치하면 할 일 기록이 표시됩니다.
apple cereal banana mango coffee
새 할일을 생성하려면 create_todo() 함수를 생성하세요. 할 일 레코드는 ID와 제목 필드가 있는 사전으로 표시됩니다.
# create a list
drinks = ["milkshake","black tea","banana milk","mango juice"]
# update value at index 2
drinks[2] = "chocolate milk"
print(f"value at index 2: {drinks[2]}")
할 일을 업데이트하려면 update_todo() 함수를 만드세요. 이 함수에서는 지정된 ID별로 할일 레코드를 업데이트합니다.
value at index 2: chocolate milk
할일을 삭제하려면 delete_todo() 함수를 만드세요. 해당 기능은 지정된 ID의 할일 기록을 삭제하는 기능입니다.
items = ["apple","banana","mango","coffee"]
# remove "mango"
items.remove("mango")
# remove item at index 1
items.remove(items[1])
print("after removed")
for item in items:
print(item)
마지막으로 애플리케이션의 메인 메뉴를 표시하는 display_menu()라는 함수를 만듭니다.
after removed apple coffee
전체 코드입니다.
list_name[start:end]
어플리케이션의 출력입니다.

출처
- Python의 데이터 구조
이 기사가 Python을 배우는 데 도움이 되기를 바랍니다. 피드백이 있으시면 댓글로 알려주세요.
위 내용은 Python 튜토리얼 - ata 구조의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!