


개요
PDF 데이터 추출 비즈니스 로직을 작업 코드로 변환하는 Python 스크립트를 작성했습니다.
이 스크립트는 10개월 동안(2024년 1월부터 10월까지) 관리인 명세서 PDF 71페이지에서 테스트되었습니다. PDF 처리를 완료하는 데 약 4초가 걸렸습니다. 수동으로 처리하는 것보다 훨씬 빠릅니다.

제가 보기에는 출력이 올바르고 코드에 오류가 발생하지 않은 것 같습니다.
아래에는 세 가지 CSV 출력의 스냅샷이 나와 있습니다. 민감한 데이터는 회색으로 표시되어 있습니다.
스냅샷 1: 보유 주식
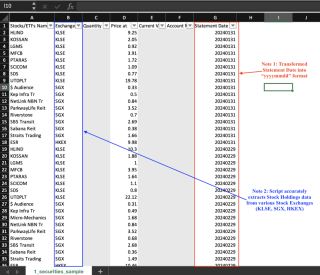
스냅샷 2: 펀드 보유

스냅샷 3: 현금 보유

이 워크플로는 CSV 파일을 생성하기 위해 수행한 광범위한 단계를 보여줍니다.
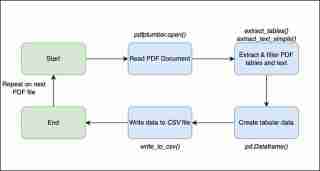
이제 비즈니스 로직을 파이썬으로 코드로 변환하는 방법을 좀 더 자세히 설명하겠습니다.
1단계: PDF 문서 읽기
pdfplumber의 open() 함수를 사용했습니다.
# Open the PDF file with pdfplumber.open(file_path) as pdf:
file_path는 pdfplumber에게 어떤 파일을 열 것인지 알려주는 선언된 변수입니다.
2.0단계: 각 페이지에서 테이블 추출 및 필터링
extract_tables() 함수는 각 페이지에서 모든 테이블을 추출하는 힘든 작업을 수행합니다.
기본 논리에 대해 잘 알지는 못하지만 기능이 꽤 잘 작동했다고 생각합니다. 예를 들어, 아래 두 스냅샷은 추출된 테이블과 원본(PDF에서)을 보여줍니다
스냅샷 A: VS Code 터미널의 출력

스냅샷 B: PDF 표

그런 다음 나중에 특정 테이블에서 데이터를 "선택"할 수 있도록 각 테이블에 고유하게 레이블을 지정해야 했습니다.
이상적인 옵션은 각 테이블의 제목을 사용하는 것이었습니다. 하지만 제목 좌표를 결정하는 것은 제 능력 밖의 일이었습니다.
해결 방법으로 처음 세 열의 헤더를 연결하여 각 테이블을 식별했습니다. 예를 들어 스냅샷 B의 Stock Holdings 테이블에는 Stocks/ETFsnNameExchangeQuantity
라는 레이블이 지정되어 있습니다.⚠️이 접근 방식에는 심각한 단점이 있습니다. 처음 세 개의 헤더 이름이 모든 테이블을 충분히 고유하게 만들지는 못합니다. 다행히 이는 관련 없는 테이블에만 영향을 미칩니다.
2.1단계: 표가 아닌 텍스트 추출, 필터링 및 변환
필요한 특정 값인 계좌 번호 및 명세서 날짜는 각 PDF의 1페이지에 있는 하위 문자열이었습니다.
예를 들어 "계좌 번호 M1234567"에는 계좌 번호 "M1234567"이 포함됩니다.

Python의 re 라이브러리를 사용하고 ChatGPT를 통해 적합한 정규식("regex")을 제안했습니다. 정규식은 각 문자열을 두 그룹으로 나누고 두 번째 그룹에는 원하는 데이터를 넣습니다.
명세서 날짜 및 계좌 번호 문자열에 대한 정규식
# Open the PDF file with pdfplumber.open(file_path) as pdf:
다음으로 명세서 날짜를 "yyyymmdd" 형식으로 변환했습니다. 이렇게 하면 데이터를 더 쉽게 쿼리하고 정렬할 수 있습니다.
regex_date=r'Statement for \b([A-Za-z]{3}-\d{4})\b'
regex_acc_no=r'Account Number ([A-Za-z]\d{7})'
match_date는 정규식과 일치하는 문자열이 발견되었을 때 선언되는 변수입니다.
3단계: 표 형식 데이터 만들기
이 시점에서 관련 데이터 포인트를 추출하는 하드 야드가 거의 완료되었습니다.
다음으로 pandas의 DataFrame() 함수를 사용하여 2단계와 3단계의 출력을 기반으로 테이블 형식의 데이터를 생성했습니다. 불필요한 열과 행을 삭제하는 데에도 이 기능을 사용했습니다.
최종 결과를 쉽게 CSV에 기록하거나 데이터베이스에 저장할 수 있습니다.
4단계: CSV 파일에 데이터 쓰기
Python의 write_to_csv() 함수를 사용하여 각 데이터프레임을 CSV 파일에 기록했습니다.
if match_date:
# Convert string to a mmm-yyyy date
date_obj=datetime.strptime(match_date.group(1),"%b-%Y")
# Get last day of the month
last_day=calendar.monthrange(date_obj.year,date_obj.month[1]
# Replace day with last day of month
last_day_of_month=date_obj.replace(day=last_day)
statement_date=last_day_of_month.strftime("%Y%m%d")
df_cash_selected는 Cash Holdings 데이터 프레임이고 file_cash_holdings는 Cash Holdings CSV의 파일 이름입니다.
➡️ 데이터베이스 노하우를 습득한 후 적절한 데이터베이스에 데이터를 작성하겠습니다.
다음 단계
이제 관리인 명세서 PDF에서 테이블 및 텍스트 데이터를 추출하기 위한 작업 스크립트가 준비되었습니다.
계속 진행하기 전에 스크립트가 예상대로 작동하는지 확인하기 위해 몇 가지 테스트를 실행하겠습니다.
--종료
위 내용은 # | PDF 데이터 추출 자동화: 빌드의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

 파이썬에서 튜플 이해력이 가능합니까? 그렇다면, 어떻게 그리고 그렇지 않다면?Apr 28, 2025 pm 04:34 PM
파이썬에서 튜플 이해력이 가능합니까? 그렇다면, 어떻게 그리고 그렇지 않다면?Apr 28, 2025 pm 04:34 PM기사는 구문 모호성으로 인해 파이썬에서 튜플 이해의 불가능성에 대해 논의합니다. 튜플을 효율적으로 생성하기 위해 튜플 ()을 사용하는 것과 같은 대안이 제안됩니다. (159 자)
 파이썬의 모듈과 패키지는 무엇입니까?Apr 28, 2025 pm 04:33 PM
파이썬의 모듈과 패키지는 무엇입니까?Apr 28, 2025 pm 04:33 PM이 기사는 파이썬의 모듈과 패키지, 차이점 및 사용법을 설명합니다. 모듈은 단일 파일이고 패키지는 __init__.py 파일이있는 디렉토리이며 관련 모듈을 계층 적으로 구성합니다.
 파이썬에서 Docstring이란 무엇입니까?Apr 28, 2025 pm 04:30 PM
파이썬에서 Docstring이란 무엇입니까?Apr 28, 2025 pm 04:30 PM기사는 Python의 Docstrings, 사용법 및 혜택에 대해 설명합니다. 주요 이슈 : 코드 문서 및 접근성에 대한 문서의 중요성.
 람다 기능이란 무엇입니까?Apr 28, 2025 pm 04:28 PM
람다 기능이란 무엇입니까?Apr 28, 2025 pm 04:28 PM기사는 Lambda 기능, 일반 기능과의 차이 및 프로그래밍 시나리오에서의 유틸리티에 대해 설명합니다. 모든 언어가 그들을 지원하는 것은 아닙니다.
 휴식은 무엇입니까, 계속해서 파이썬을 통과합니까?Apr 28, 2025 pm 04:26 PM
휴식은 무엇입니까, 계속해서 파이썬을 통과합니까?Apr 28, 2025 pm 04:26 PM기사는 파괴, 계속 및 Python을 통과시켜 루프 실행 및 프로그램 흐름을 제어하는 역할을 설명합니다.
 파이썬의 패스는 무엇입니까?Apr 28, 2025 pm 04:25 PM
파이썬의 패스는 무엇입니까?Apr 28, 2025 pm 04:25 PM이 기사는 기능 및 클래스와 같은 코드 구조에서 자리 표시 자로 사용되는 NULL 작업 인 Python의 'Pass'명령문에 대해 설명하여 구문 오류없이 향후 구현을 허용합니다.
 파이썬에서 인수로 기능을 전달할 수 있습니까?Apr 28, 2025 pm 04:23 PM
파이썬에서 인수로 기능을 전달할 수 있습니까?Apr 28, 2025 pm 04:23 PM기사는 파이썬의 인수와 같은 기능을 전달하는 것에 대해 논의하며, 모듈성과 같은 이점 및 분류 및 장식기와 같은 사용 사례를 강조합니다.
 파이썬에서 //의 차이점은 무엇입니까?Apr 28, 2025 pm 04:21 PM
파이썬에서 //의 차이점은 무엇입니까?Apr 28, 2025 pm 04:21 PM기사는 Python의 / 및 // 연산자에 대해 논의합니다 : / True Division, // for floor division. 주요 이슈는 차이점과 사용 사례를 이해하는 것입니다. 문자 수 : 158


핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

드림위버 CS6
시각적 웹 개발 도구

PhpStorm 맥 버전
최신(2018.2.1) 전문 PHP 통합 개발 도구

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)

