


커피 한잔 사주세요😄
*내 게시물은 EMNIST를 설명합니다.
EMNIST()는 아래와 같이 EMNIST 데이터세트를 사용할 수 있습니다.
*메모:
- 첫 번째 인수는 루트(필수 유형:str 또는 pathlib.Path)입니다. *절대경로, 상대경로 모두 가능합니다.
- 두 번째 인수는 분할(필수 유형:str)입니다. *"byclass", "bymerge", "balanced", "letters", "digits" 또는 "mnist"를 설정할 수 있습니다.
- 열차 인수가 있습니다(Optional-Default:False-Type:float):
*메모:
- split="byclass", Split="byclass"의 경우, True이면 train 데이터(697,932개 이미지)가 사용되고, False이면 테스트 데이터(116,323개 이미지)가 사용됩니다.
- split="balanced"의 경우 True이면 학습 데이터(112,800개 이미지)를 사용하고, False이면 테스트 데이터(188,00개 이미지)를 사용합니다.
- split="letters"의 경우, True이면 학습 데이터(124,800개 이미지)가 사용되고, False이면 테스트 데이터(20,800개 이미지)가 사용됩니다.
- split="digits"의 경우, True이면 학습 데이터(240,000개 이미지)가 사용되고, False이면 테스트 데이터(40,000개 이미지)가 사용됩니다.
- split="mnist"의 경우 True이면 학습 데이터(60,000개 이미지)를 사용하고, False이면 테스트 데이터(10,000개 이미지)를 사용합니다.
- Transform 인수(Optional-Default:None-Type:callable)가 있습니다.
- target_transform 인수(Optional-Default:None-Type:callable)가 있습니다.
- 다운로드 인수가 있습니다(Optional-Default:False-Type:bool):
*메모:
- True인 경우 데이터 세트가 인터넷에서 다운로드되어 루트에 추출(압축 해제)됩니다.
- True이고 데이터세트가 이미 다운로드된 경우 추출됩니다.
- True이고 데이터 세트가 이미 다운로드되어 추출된 경우 아무 일도 일어나지 않습니다.
- 데이터 세트가 이미 다운로드되어 추출된 경우 더 빠르므로 False여야 합니다.
- 여기에서 데이터 세트를 수동으로 다운로드하고 추출할 수 있습니다. 데이터/EMNIST/raw/.
- 기본적으로 이미지가 반시계 방향으로 90도 회전 및 반전되는 버그가 있으므로 변환해야 합니다.
from torchvision.datasets import EMNIST
train_data = EMNIST(
root="data",
split="byclass"
)
train_data = EMNIST(
root="data",
split="byclass",
train=True,
transform=None,
target_transform=None,
download=False
)
test_data = EMNIST(
root="data",
split="byclass",
train=False
)
len(train_data), len(test_data)
# 697932 116323
train_data
# Dataset EMNIST
# Number of datapoints: 697932
# Root location: data
# Split: Train
train_data.root
# 'data'
train_data.split
# 'byclass'
train_data.train
# True
print(train_data.transform)
# None
print(train_data.target_transform)
# None
train_data.download
# <bound method emnist.download of dataset emnist number datapoints: root location: data split: train>
train_data[0]
# (<pil.image.image image mode="L" size="28x28">, 35)
train_data[1]
# (<pil.image.image image mode="L" size="28x28">, 36)
train_data[2]
# (<pil.image.image image mode="L" size="28x28">, 6)
train_data[3]
# (<pil.image.image image mode="L" size="28x28">, 3)
train_data[4]
# (<pil.image.image image mode="L" size="28x28">, 22)
train_data.classes
# ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9',
# 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M',
# 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z',
# 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm',
# 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z']
</pil.image.image></pil.image.image></pil.image.image></pil.image.image></pil.image.image></bound>
from torchvision.datasets import EMNIST
train_data = EMNIST(
root="data",
split="byclass",
train=True
)
test_data = EMNIST(
root="data",
split="byclass",
train=False
)
import matplotlib.pyplot as plt
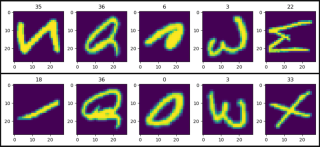
def show_images(data):
plt.figure(figsize=(12, 2))
col = 5
for i, (image, label) in enumerate(data, 1):
plt.subplot(1, col, i)
plt.title(label)
plt.imshow(image)
if i == col:
break
plt.show()
show_images(data=train_data)
show_images(data=test_data)
from torchvision.datasets import EMNIST
from torchvision.transforms import v2
train_data = EMNIST(
root="data",
split="byclass",
train=True,
transform=v2.Compose([
v2.RandomHorizontalFlip(p=1.0),
v2.RandomRotation(degrees=(90, 90))
])
)
test_data = EMNIST(
root="data",
split="byclass",
train=False,
transform=v2.Compose([
v2.RandomHorizontalFlip(p=1.0),
v2.RandomRotation(degrees=(90, 90))
])
)
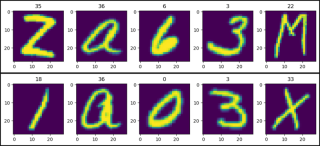
import matplotlib.pyplot as plt
def show_images(data):
plt.figure(figsize=(12, 2))
col = 5
for i, (image, label) in enumerate(data, 1):
plt.subplot(1, col, i)
plt.title(label)
plt.imshow(image)
if i == col:
break
plt.show()
show_images(data=train_data)
show_images(data=test_data)
위 내용은 PyTorch의 EMNIST의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

 파이썬 어레이에 어떤 데이터 유형을 저장할 수 있습니까?Apr 27, 2025 am 12:11 AM
파이썬 어레이에 어떤 데이터 유형을 저장할 수 있습니까?Apr 27, 2025 am 12:11 AMPythonlistsCanstoreAnyDatAtype, ArrayModuLearRaysStoreOneType 및 NUMPYARRAYSAREFORNUMERICALPUTATION.1) LISTSAREVERSATILEBUTLESSMEMORY-EFFICENT.2) ARRAYMODUERRAYRAYRAYSARRYSARESARESARESARESARESARESAREDOREDORY-UNFICEDONOUNEOUSDATA.3) NumpyArraysUraysOrcepperperperperperperperperperperperperperperperferperferperferferpercient
 파이썬 어레이에 잘못된 데이터 유형의 값을 저장하려고하면 어떻게됩니까?Apr 27, 2025 am 12:10 AM
파이썬 어레이에 잘못된 데이터 유형의 값을 저장하려고하면 어떻게됩니까?Apr 27, 2025 am 12:10 AMwhenyouattempttoreavalueofthewrongdatatypeinapythonaphonarray, thisiSdueTotheArrayModule의 stricttyPeenforcement, theAllElementStobeofthesAmetypecified bythetypecode.forperformancersassion, arraysaremoreficats the thraysaremoreficats thetheperfication the thraysaremorefications는
 Python Standard Library의 일부는 무엇입니까? 목록 또는 배열은 무엇입니까?Apr 27, 2025 am 12:03 AM
Python Standard Library의 일부는 무엇입니까? 목록 또는 배열은 무엇입니까?Apr 27, 2025 am 12:03 AMPythonlistsarepartoftsandardlardlibrary, whileraysarenot.listsarebuilt-in, 다재다능하고, 수집 할 수있는 반면, arraysarreprovidedByTearRaymoduledlesscommonlyusedDuetolimitedFunctionality.
 스크립트가 잘못된 파이썬 버전으로 실행되는지 확인해야합니까?Apr 27, 2025 am 12:01 AM
스크립트가 잘못된 파이썬 버전으로 실행되는지 확인해야합니까?Apr 27, 2025 am 12:01 AMthescriptIsrunningwithHongpyThonversionDueCorRectDefaultTerpretersEttings.tofixThis : 1) checktheDefaultPyThonVersionUsingPyThon-VersionorPyThon3- version.2) usvirtual-ErondmentsBythePython.9-Mvenvmyenv, 활성화, 및 파괴
 파이썬 어레이에서 수행 할 수있는 일반적인 작업은 무엇입니까?Apr 26, 2025 am 12:22 AM
파이썬 어레이에서 수행 할 수있는 일반적인 작업은 무엇입니까?Apr 26, 2025 am 12:22 AMPythonArraysSupportVariousOperations : 1) SlicingExtractsSubsets, 2) 추가/확장 어드먼트, 3) 삽입 값 삽입 ATSpecificPositions, 4) retingdeletesElements, 5) 분류/ReversingChangesOrder 및 6) ListsompectionScreateNewListSbasedOnsistin
 어떤 유형의 응용 프로그램에서 Numpy Array가 일반적으로 사용됩니까?Apr 26, 2025 am 12:13 AM
어떤 유형의 응용 프로그램에서 Numpy Array가 일반적으로 사용됩니까?Apr 26, 2025 am 12:13 AMNumpyArraysareSentialplosplicationSefficationSefficientNumericalcomputationsanddatamanipulation. Theyarcrucialindatascience, MachineLearning, Physics, Engineering 및 Financeduetotheiribility에 대한 handlarge-scaledataefficivally. forexample, Infinancialanyaly
 파이썬의 목록 위의 배열을 언제 사용 하시겠습니까?Apr 26, 2025 am 12:12 AM
파이썬의 목록 위의 배열을 언제 사용 하시겠습니까?Apr 26, 2025 am 12:12 AMUseanArray.ArrayOveralistInpyThonWhendealingwithhomogeneousData, Performance-CriticalCode, OrinterFacingwithCcode.1) HomogeneousData : ArraysSaveMemorywithtypepletement.2) Performance-CriticalCode : arraysofferbetterporcomanceFornumericalOperations.3) Interf
 모든 목록 작업은 배열에 의해 지원됩니까? 왜 또는 왜 그렇지 않습니까?Apr 26, 2025 am 12:05 AM
모든 목록 작업은 배열에 의해 지원됩니까? 왜 또는 왜 그렇지 않습니까?Apr 26, 2025 am 12:05 AM아니요, NOTALLLISTOPERATIONARESUPPORTEDBYARRARES, andVICEVERSA.1) ArraySDONOTSUPPORTDYNAMICOPERATIONSLIKEPENDORINSERTWITHUTRESIGING, WHITHIMPACTSPERFORMANCE.2) ListSDONOTEECONSTANTTIMECOMPLEXITEFORDITITICCESSLIKEARRAYSDO.


핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)

DVWA
DVWA(Damn Vulnerable Web App)는 매우 취약한 PHP/MySQL 웹 애플리케이션입니다. 주요 목표는 보안 전문가가 법적 환경에서 자신의 기술과 도구를 테스트하고, 웹 개발자가 웹 응용 프로그램 보안 프로세스를 더 잘 이해할 수 있도록 돕고, 교사/학생이 교실 환경 웹 응용 프로그램에서 가르치고 배울 수 있도록 돕는 것입니다. 보안. DVWA의 목표는 다양한 난이도의 간단하고 간단한 인터페이스를 통해 가장 일반적인 웹 취약점 중 일부를 연습하는 것입니다. 이 소프트웨어는

에디트플러스 중국어 크랙 버전
작은 크기, 구문 강조, 코드 프롬프트 기능을 지원하지 않음

SecList
SecLists는 최고의 보안 테스터의 동반자입니다. 보안 평가 시 자주 사용되는 다양한 유형의 목록을 한 곳에 모아 놓은 것입니다. SecLists는 보안 테스터에게 필요할 수 있는 모든 목록을 편리하게 제공하여 보안 테스트를 더욱 효율적이고 생산적으로 만드는 데 도움이 됩니다. 목록 유형에는 사용자 이름, 비밀번호, URL, 퍼징 페이로드, 민감한 데이터 패턴, 웹 셸 등이 포함됩니다. 테스터는 이 저장소를 새로운 테스트 시스템으로 간단히 가져올 수 있으며 필요한 모든 유형의 목록에 액세스할 수 있습니다.

WebStorm Mac 버전
유용한 JavaScript 개발 도구

