


소개
저는 현재 강력한 오픈소스 크리에이티브 드로잉 보드를 관리하고 있습니다. 이 드로잉 보드에는 많은 흥미로운 브러시와 보조 드로잉 기능이 통합되어 있어 사용자가 새로운 드로잉 효과를 경험할 수 있습니다. 모바일이든 PC이든 더 나은 인터랙티브 경험과 효과 표시를 즐길 수 있습니다.
이 글에서는 Transformers.js를 결합하여 배경 제거 및 이미지 마킹 분할을 구현하는 방법을 자세히 설명하겠습니다. 결과는 다음과 같습니다

링크: https://songlh.top/paint-board/
Github: https://github.com/LHRUN/paint-board Star ⭐️에 오신 것을 환영합니다
Transformers.js
Transformers.js는 서버측 계산에 의존하지 않고 브라우저에서 직접 실행할 수 있는 Hugging Face Transformers를 기반으로 하는 강력한 JavaScript 라이브러리입니다. 이는 모델을 로컬에서 실행하여 효율성을 높이고 배포 및 유지 관리 비용을 줄일 수 있음을 의미합니다.
현재 Transformers.js는 다양한 도메인을 포괄하는 Hugging Face에 1000개 모델을 제공하고 있으며, 이는 이미지 처리, 텍스트 생성, 번역, 감정 분석 및 기타 작업 처리 등 대부분의 요구 사항을 충족할 수 있으며 Transformers를 통해 쉽게 달성할 수 있습니다. .js 다음과 같이 모델을 검색하세요.
Transformers.js의 현재 주요 버전이 V3으로 업데이트되어 많은 훌륭한 기능과 세부 정보가 추가되었습니다. Transformers.js v3: WebGPU 지원, 새 모델 및 작업 등….
이 게시물에 추가한 두 기능은 모두 V3에서만 사용할 수 있는 WebGpu 지원을 사용하며 이제 밀리초 단위의 구문 분석 기능을 통해 처리 속도가 크게 향상되었습니다. 다만, WebGPU를 지원하는 브라우저가 많지 않다는 점 참고하시고 방문하시려면 최신 버전의 구글을 이용하시는 것을 권장드립니다.
기능 1: 배경 제거
배경을 제거하기 위해 저는 다음과 같은 Xenova/modnet 모델을 사용합니다
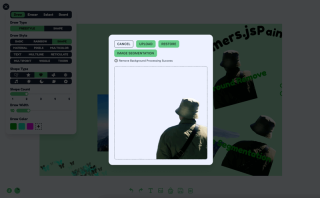
처리 로직은 세 단계로 나눌 수 있습니다
- 상태를 초기화하고 모델과 프로세서를 로드합니다.
- 인터페이스 디스플레이는 제가 디자인한 것이 아닌 여러분이 직접 디자인한 것입니다.
- 효과를 보여주세요. 이것은 내 디자인이 아닌 여러분 자신의 디자인을 기반으로 합니다. 요즘에는 배경을 제거하기 전과 후에 대비 효과를 동적으로 표시하기 위해 경계선을 사용하는 것이 더 인기가 있습니다.
코드 로직은 다음과 같습니다. React TS. 자세한 내용은 내 프로젝트의 소스 코드를 참조하세요. 소스 코드는 src/comComponents/boardOperation/uploadImage/index.tsx에 있습니다.
import { useState, FC, useRef, useEffect, useMemo } from 'react'
import {
env,
AutoModel,
AutoProcessor,
RawImage,
PreTrainedModel,
Processor
} from '@huggingface/transformers'
const REMOVE_BACKGROUND_STATUS = {
LOADING: 0,
NO_SUPPORT_WEBGPU: 1,
LOAD_ERROR: 2,
LOAD_SUCCESS: 3,
PROCESSING: 4,
PROCESSING_SUCCESS: 5
}
type RemoveBackgroundStatusType =
(typeof REMOVE_BACKGROUND_STATUS)[keyof typeof REMOVE_BACKGROUND_STATUS]
const UploadImage: FC = ({ url }) => {
const [removeBackgroundStatus, setRemoveBackgroundStatus] =
useState<removebackgroundstatustype>()
const [processedImage, setProcessedImage] = useState('')
const modelRef = useRef<pretrainedmodel>()
const processorRef = useRef<processor>()
const removeBackgroundBtnTip = useMemo(() => {
switch (removeBackgroundStatus) {
case REMOVE_BACKGROUND_STATUS.LOADING:
return 'Remove background function loading'
case REMOVE_BACKGROUND_STATUS.NO_SUPPORT_WEBGPU:
return 'WebGPU is not supported in this browser, to use the remove background function, please use the latest version of Google Chrome'
case REMOVE_BACKGROUND_STATUS.LOAD_ERROR:
return 'Remove background function failed to load'
case REMOVE_BACKGROUND_STATUS.LOAD_SUCCESS:
return 'Remove background function loaded successfully'
case REMOVE_BACKGROUND_STATUS.PROCESSING:
return 'Remove Background Processing'
case REMOVE_BACKGROUND_STATUS.PROCESSING_SUCCESS:
return 'Remove Background Processing Success'
default:
return ''
}
}, [removeBackgroundStatus])
useEffect(() => {
;(async () => {
try {
if (removeBackgroundStatus === REMOVE_BACKGROUND_STATUS.LOADING) {
return
}
setRemoveBackgroundStatus(REMOVE_BACKGROUND_STATUS.LOADING)
// Checking WebGPU Support
if (!navigator?.gpu) {
setRemoveBackgroundStatus(REMOVE_BACKGROUND_STATUS.NO_SUPPORT_WEBGPU)
return
}
const model_id = 'Xenova/modnet'
if (env.backends.onnx.wasm) {
env.backends.onnx.wasm.proxy = false
}
// Load model and processor
modelRef.current ??= await AutoModel.from_pretrained(model_id, {
device: 'webgpu'
})
processorRef.current ??= await AutoProcessor.from_pretrained(model_id)
setRemoveBackgroundStatus(REMOVE_BACKGROUND_STATUS.LOAD_SUCCESS)
} catch (err) {
console.log('err', err)
setRemoveBackgroundStatus(REMOVE_BACKGROUND_STATUS.LOAD_ERROR)
}
})()
}, [])
const processImages = async () => {
const model = modelRef.current
const processor = processorRef.current
if (!model || !processor) {
return
}
setRemoveBackgroundStatus(REMOVE_BACKGROUND_STATUS.PROCESSING)
// load image
const img = await RawImage.fromURL(url)
// Pre-processed image
const { pixel_values } = await processor(img)
// Generate image mask
const { output } = await model({ input: pixel_values })
const maskData = (
await RawImage.fromTensor(output[0].mul(255).to('uint8')).resize(
img.width,
img.height
)
).data
// Create a new canvas
const canvas = document.createElement('canvas')
canvas.width = img.width
canvas.height = img.height
const ctx = canvas.getContext('2d') as CanvasRenderingContext2D
// Draw the original image
ctx.drawImage(img.toCanvas(), 0, 0)
// Updating the mask area
const pixelData = ctx.getImageData(0, 0, img.width, img.height)
for (let i = 0; i
<button classname="{`btn" btn-primary btn-sm remove_background_status.load_success remove_background_status.processing_success undefined : onclick="{processImages}">
Remove background
</button>
<div classname="text-xs text-base-content mt-2 flex">
{removeBackgroundBtnTip}
</div>
<div classname="relative mt-4 border border-base-content border-dashed rounded-lg overflow-hidden">
<img src="/static/imghwm/default1.png" data-src="https://img.php.cn/upload/article/000/000/000/173262759935552.jpg?x-oss-process=image/resize,p_40" class="lazy" classname="{`w-[50vw]" max-w- h- max-h- object-contain alt="Canvas 시리즈 탐색: Transformers.js와 결합하여 지능형 이미지 처리 달성" >
{processedImage && (
<img src="/static/imghwm/default1.png" data-src="https://img.php.cn/upload/article/000/000/000/173262759935552.jpg?x-oss-process=image/resize,p_40" class="lazy" classname="{`w-full" h-full absolute top-0 left-0 z- object-contain alt="Canvas 시리즈 탐색: Transformers.js와 결합하여 지능형 이미지 처리 달성" >
)}
</div>
)
}
export default UploadImage
</processor></pretrainedmodel></removebackgroundstatustype>
기능 2: 이미지 마커 분할
이미지 마커 분할은 Xenova/slimsam-77-uniform 모델을 사용하여 구현됩니다. 효과는 다음과 같습니다. 이미지가 로드된 후 클릭하면 클릭한 좌표에 따라 분할이 생성됩니다.
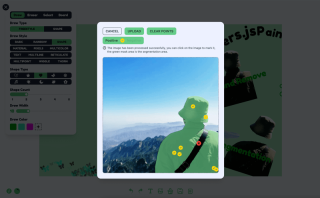
처리 로직은 5단계로 나눌 수 있습니다
- 상태를 초기화하고 모델과 프로세서를 로드합니다
- 이미지를 가져와 로드한 후 데이터 로딩 및 삽입 데이터를 이미지에 저장합니다.
- 이미지 클릭 이벤트를 듣고 클릭 데이터를 기록하고 양수 마커와 음수 마커로 구분한 후 각 클릭 후 디코딩된 클릭 데이터에 따라 마스크 데이터를 생성한 다음 마스크 데이터에 따라 분할 효과를 그립니다. .
- 인터페이스 디스플레이, 이것은 내 취향이 아닌 자신만의 디자인으로 임의로 플레이할 수 있습니다
- 클릭하여 이미지를 저장하고 마스크 픽셀 데이터에 따라 원본 이미지 데이터와 일치시킨 다음 캔버스 드로잉을 통해 내보냅니다
코드 로직은 다음과 같습니다. React TS. 자세한 내용은 내 프로젝트의 소스 코드를 참조하세요. 소스 코드는 src/comComponents/boardOperation/uploadImage/imageSegmentation.tsx에 있습니다.
'react'에서 { useState, useRef, useEffect, useMemo, MouseEvent, FC } 가져오기
수입 {
샘모델,
자동프로세서,
원시 이미지,
사전 훈련된 모델,
프로세서,
텐서,
Sam이미지프로세서결과
} '@huggingface/transformers'에서
'@/comComponents/icons/loading.svg?react'에서 LoadingIcon 가져오기
'@/comComponents/icons/boardOperation/image-segmentation-긍정적인.svg?react'에서 PositiveIcon을 가져옵니다.
'@/comComponents/icons/boardOperation/image-segmentation-negative.svg?react'에서 NegativeIcon을 가져옵니다.
인터페이스 MarkPoint {
위치: 숫자[]
라벨: 번호
}
const SEGMENTATION_STATUS = {
로드 중: 0,
NO_SUPPORT_WEBGPU: 1,
LOAD_ERROR: 2,
로드_성공: 3,
처리 중: 4,
처리_성공: 5
}
유형 SegmentationStatusType =
(SEGMENTATION_STATUS 유형)[SEGMENTATION_STATUS 유형 키]
const 이미지 분할: FC = ({ URL }) => {
const [markPoints, setMarkPoints] = useState<markpoint>([])
const [segmentationStatus, setSegmentationStatus] =
useState<segmentationstatustype>()
const [pointStatus, setPointStatus] = useState(true)
const MaskCanvasRef = useRef<htmlcanvaselement>(null) // 분할 마스크
const modelRef = useRef<pretrainedmodel>() // 모델
const processorRef = useRef<processor>() // 프로세서
const imageInputRef = useRef<rawimage>() // 원본 이미지
const imageProcessed = useRef<samimageprocessorresult>() // 처리된 이미지
const imageEmbeddings = useRef<tensor>() // 데이터 삽입
const 분할Tip = useMemo(() => {
스위치(분할상태) {
케이스 SEGMENTATION_STATUS.LOADING:
'이미지 분할 기능 로딩 중'을 반환합니다.
사례 SEGMENTATION_STATUS.NO_SUPPORT_WEBGPU:
return '이 브라우저에서는 WebGPU가 지원되지 않습니다. 이미지 분할 기능을 사용하려면 최신 버전의 Google Chrome을 사용하세요.'
사례 SEGMENTATION_STATUS.LOAD_ERROR:
'이미지 분할 기능을 로드하지 못했습니다'를 반환합니다.
사례 SEGMENTATION_STATUS.LOAD_SUCCESS:
'이미지 분할 기능이 성공적으로 로드되었습니다'를 반환합니다.
사례 SEGMENTATION_STATUS.PROCESSING:
'이미지 처리...'를 반환합니다.
사례 SEGMENTATION_STATUS.PROCESSING_SUCCESS:
return '이미지가 성공적으로 처리되었습니다. 이미지를 클릭하여 표시할 수 있습니다. 녹색 마스크 영역은 분할 영역입니다.'
기본:
반품 ''
}
}, [분할상태])
// 1. 모델 및 프로세서 로드
useEffect(() => {
;(비동기 () => {
노력하다 {
if (segmentationStatus === SEGMENTATION_STATUS.LOADING) {
반품
}
setSegmentationStatus(SEGMENTATION_STATUS.LOADING)
if (!navigator?.gpu) {
setSegmentationStatus(SEGMENTATION_STATUS.NO_SUPPORT_WEBGPU)
반품
}const model_id = '제노바/slimsam-77-uniform'
modelRef.current ??= SamModel.from_pretrained(model_id, {
dtype: 'fp16', // 또는 "fp32"
장치: 'webgpu'
})
processorRef.current ??= AutoProcessor.from_pretrained(model_id)를 기다립니다.
setSegmentationStatus(SEGMENTATION_STATUS.LOAD_SUCCESS)
} 잡기 (오류) {
console.log('err', 오류)
setSegmentationStatus(SEGMENTATION_STATUS.LOAD_ERROR)
}
})()
}, [])
// 2. 프로세스 이미지
useEffect(() => {
;(비동기 () => {
노력하다 {
만약에 (
!modelRef.current ||
!processorRef.current ||
!url ||
분할 상태 === SEGMENTATION_STATUS.PROCESSING
) {
반품
}
setSegmentationStatus(SEGMENTATION_STATUS.PROCESSING)
클리어포인트()
imageInputRef.current = RawImage.fromURL(url)을 기다립니다.
imageProcessed.current = processorRef.current(를 기다립니다.
imageInputRef.current
)
imageEmbeddings.current = 대기(
modelRef.current를 그대로 사용
).get_image_embeddings(imageProcessed.current)
setSegmentationStatus(SEGMENTATION_STATUS.PROCESSING_SUCCESS)
} 잡기 (오류) {
console.log('err', 오류)
}
})()
}, [url, modelRef.current, processorRef.current])
// 마스크 효과 업데이트
함수 updateMaskOverlay(마스크: RawImage, 점수: Float32Array) {
const 마스크캔버스 = 마스크캔버스Ref.current
if (!maskCanvas) {
반품
}
const MaskContext = MaskCanvas.getContext('2d') as CanvasRenderingContext2D
// 캔버스 크기 업데이트(다른 경우)
if (maskCanvas.width !== 마스크.폭 || 마스크캔버스.높이 !== 마스크.높이) {
마스크캔버스.폭 = 마스크.폭
마스크캔버스.높이 = 마스크.높이
}
// 픽셀 데이터에 대한 버퍼 할당
const imageData = MaskContext.createImageData(
마스크캔버스.폭,
마스크캔버스.높이
)
// 최적의 마스크 선택
const numMasks = Score.length // 3
bestIndex = 0으로 놔두세요
for (let i = 1; i 점수[bestIndex]) {
베스트인덱스 = 나
}
}
// 마스크를 색상으로 채우기
const pixelData = imageData.data
for (let i = 0; i {
만약에 (
!modelRef.current ||
!imageEmbeddings.current ||
!processorRef.current ||
!imageProcessed.current
) {
반품
}// 데이터를 클릭하지 않으면 분할 효과가 직접 지워집니다.
if (!markPoints.length && 마스크CanvasRef.current) {
const MaskContext = 마스크CanvasRef.current.getContext(
'2d'
) CanvasRenderingContext2D로
MaskContext.clearRect(
0,
0,
마스크CanvasRef.current.width,
마스크CanvasRef.current.height
)
반품
}
// 디코딩을 위한 입력 준비
const reshape = imageProcessed.current.reshape_input_sizes[0]
const 포인트 = markPoint
.map((x) => [x.position[0] * 모양 변경[1], x.position[1] * 모양 변경[0]])
.플랫(무한대)
const labels = markPoints.map((x) => BigInt(x.label)). flat(Infinity)
const num_points = markPoints.length
const input_points = new Tensor('float32', points, [1, 1, num_points, 2])
const input_labels = new Tensor('int64', labels, [1, 1, num_points])
// 마스크 생성
const { pred_masks, iou_scores } = modelRef.current({
...imageEmbeddings.current,
입력 포인트,
입력_라벨
})
// 마스크 후처리
const 마스크 = 대기(processorRef.current 그대로).post_process_masks(
pred_masks,
imageProcessed.current.original_sizes,
imageProcessed.current.reshape_input_sizes
)
updateMaskOverlay(RawImage.fromTensor(masks[0][0]), iou_scores.data)
}
const 클램프 = (x: 숫자, 최소 = 0, 최대 = 1) => {
Math.max(Math.min(x, max), min)를 반환합니다.
}
const clickImage = (e: MouseEvent) => {
if (segmentationStatus !== SEGMENTATION_STATUS.PROCESSING_SUCCESS) {
반품
}
const { clientX, clientY, currentTarget } = e
const { 왼쪽, 위쪽 } = currentTarget.getBoundingClientRect()
const x = 클램프(
(clientX - 왼쪽 currentTarget.scrollLeft) / currentTarget.scrollWidth
)
const y = 클램프(
(clientY - 상단 currentTarget.scrollTop) / currentTarget.scrollHeight
)
const 기존PointIndex = markPoints.findIndex(
(점) =>
Math.abs(point.position[0] - x) {
setMarkPoints([])
풀다([])
}
반품 (
<div classname="카드 섀도우-xl 오버플로-자동">
<div classname="flex items-center gap-x-3">
<button classname="btn btn-primary btn-sm" onclick="{clearPoints}">
클리어 포인트
버튼>
setPointStatus(true)}
>
{포인트상태 ? '긍정적' : '부정적'}
버튼>
</button>
</div>
<div classname="text-xs text-base-content mt-2">{segmentationTip}</div>
<div>
<h2>
결론
</h2>
<p>읽어주셔서 감사합니다. 이것이 이 글의 전체 내용입니다. 이 글이 여러분에게 도움이 되기를 바라며, 좋아요와 즐겨찾기는 환영합니다. 궁금하신 점은 댓글로 편하게 토론해주세요!</p>
</div>
</div></tensor></samimageprocessorresult></rawimage></processor></pretrainedmodel></htmlcanvaselement></segmentationstatustype></markpoint>위 내용은 Canvas 시리즈 탐색: Transformers.js와 결합하여 지능형 이미지 처리 달성의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

 자바 스크립트 행동 : 실제 예제 및 프로젝트Apr 19, 2025 am 12:13 AM
자바 스크립트 행동 : 실제 예제 및 프로젝트Apr 19, 2025 am 12:13 AM실제 세계에서 JavaScript의 응용 프로그램에는 프론트 엔드 및 백엔드 개발이 포함됩니다. 1) DOM 운영 및 이벤트 처리와 관련된 TODO 목록 응용 프로그램을 구축하여 프론트 엔드 애플리케이션을 표시합니다. 2) Node.js를 통해 RESTFULAPI를 구축하고 Express를 통해 백엔드 응용 프로그램을 시연하십시오.
 JavaScript 및 웹 : 핵심 기능 및 사용 사례Apr 18, 2025 am 12:19 AM
JavaScript 및 웹 : 핵심 기능 및 사용 사례Apr 18, 2025 am 12:19 AM웹 개발에서 JavaScript의 주요 용도에는 클라이언트 상호 작용, 양식 검증 및 비동기 통신이 포함됩니다. 1) DOM 운영을 통한 동적 컨텐츠 업데이트 및 사용자 상호 작용; 2) 사용자가 사용자 경험을 향상시키기 위해 데이터를 제출하기 전에 클라이언트 확인이 수행됩니다. 3) 서버와의 진실한 통신은 Ajax 기술을 통해 달성됩니다.
 JavaScript 엔진 이해 : 구현 세부 사항Apr 17, 2025 am 12:05 AM
JavaScript 엔진 이해 : 구현 세부 사항Apr 17, 2025 am 12:05 AM보다 효율적인 코드를 작성하고 성능 병목 현상 및 최적화 전략을 이해하는 데 도움이되기 때문에 JavaScript 엔진이 내부적으로 작동하는 방식을 이해하는 것은 개발자에게 중요합니다. 1) 엔진의 워크 플로에는 구문 분석, 컴파일 및 실행; 2) 실행 프로세스 중에 엔진은 인라인 캐시 및 숨겨진 클래스와 같은 동적 최적화를 수행합니다. 3) 모범 사례에는 글로벌 변수를 피하고 루프 최적화, Const 및 Lets 사용 및 과도한 폐쇄 사용을 피하는 것이 포함됩니다.
 Python vs. JavaScript : 학습 곡선 및 사용 편의성Apr 16, 2025 am 12:12 AM
Python vs. JavaScript : 학습 곡선 및 사용 편의성Apr 16, 2025 am 12:12 AMPython은 부드러운 학습 곡선과 간결한 구문으로 초보자에게 더 적합합니다. JavaScript는 가파른 학습 곡선과 유연한 구문으로 프론트 엔드 개발에 적합합니다. 1. Python Syntax는 직관적이며 데이터 과학 및 백엔드 개발에 적합합니다. 2. JavaScript는 유연하며 프론트 엔드 및 서버 측 프로그래밍에서 널리 사용됩니다.
 Python vs. JavaScript : 커뮤니티, 라이브러리 및 리소스Apr 15, 2025 am 12:16 AM
Python vs. JavaScript : 커뮤니티, 라이브러리 및 리소스Apr 15, 2025 am 12:16 AMPython과 JavaScript는 커뮤니티, 라이브러리 및 리소스 측면에서 고유 한 장점과 단점이 있습니다. 1) Python 커뮤니티는 친절하고 초보자에게 적합하지만 프론트 엔드 개발 리소스는 JavaScript만큼 풍부하지 않습니다. 2) Python은 데이터 과학 및 기계 학습 라이브러리에서 강력하며 JavaScript는 프론트 엔드 개발 라이브러리 및 프레임 워크에서 더 좋습니다. 3) 둘 다 풍부한 학습 리소스를 가지고 있지만 Python은 공식 문서로 시작하는 데 적합하지만 JavaScript는 MDNWebDocs에서 더 좋습니다. 선택은 프로젝트 요구와 개인적인 이익을 기반으로해야합니다.
 C/C에서 JavaScript까지 : 모든 것이 어떻게 작동하는지Apr 14, 2025 am 12:05 AM
C/C에서 JavaScript까지 : 모든 것이 어떻게 작동하는지Apr 14, 2025 am 12:05 AMC/C에서 JavaScript로 전환하려면 동적 타이핑, 쓰레기 수집 및 비동기 프로그래밍으로 적응해야합니다. 1) C/C는 수동 메모리 관리가 필요한 정적으로 입력 한 언어이며 JavaScript는 동적으로 입력하고 쓰레기 수집이 자동으로 처리됩니다. 2) C/C를 기계 코드로 컴파일 해야하는 반면 JavaScript는 해석 된 언어입니다. 3) JavaScript는 폐쇄, 프로토 타입 체인 및 약속과 같은 개념을 소개하여 유연성과 비동기 프로그래밍 기능을 향상시킵니다.
 JavaScript 엔진 : 구현 비교Apr 13, 2025 am 12:05 AM
JavaScript 엔진 : 구현 비교Apr 13, 2025 am 12:05 AM각각의 엔진의 구현 원리 및 최적화 전략이 다르기 때문에 JavaScript 엔진은 JavaScript 코드를 구문 분석하고 실행할 때 다른 영향을 미칩니다. 1. 어휘 분석 : 소스 코드를 어휘 단위로 변환합니다. 2. 문법 분석 : 추상 구문 트리를 생성합니다. 3. 최적화 및 컴파일 : JIT 컴파일러를 통해 기계 코드를 생성합니다. 4. 실행 : 기계 코드를 실행하십시오. V8 엔진은 즉각적인 컴파일 및 숨겨진 클래스를 통해 최적화하여 Spidermonkey는 유형 추론 시스템을 사용하여 동일한 코드에서 성능이 다른 성능을 제공합니다.
 브라우저 너머 : 실제 세계의 JavaScriptApr 12, 2025 am 12:06 AM
브라우저 너머 : 실제 세계의 JavaScriptApr 12, 2025 am 12:06 AM실제 세계에서 JavaScript의 응용 프로그램에는 서버 측 프로그래밍, 모바일 애플리케이션 개발 및 사물 인터넷 제어가 포함됩니다. 1. 서버 측 프로그래밍은 Node.js를 통해 실현되며 동시 요청 처리에 적합합니다. 2. 모바일 애플리케이션 개발은 재교육을 통해 수행되며 크로스 플랫폼 배포를 지원합니다. 3. Johnny-Five 라이브러리를 통한 IoT 장치 제어에 사용되며 하드웨어 상호 작용에 적합합니다.


핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

맨티스BT
Mantis는 제품 결함 추적을 돕기 위해 설계된 배포하기 쉬운 웹 기반 결함 추적 도구입니다. PHP, MySQL 및 웹 서버가 필요합니다. 데모 및 호스팅 서비스를 확인해 보세요.

SublimeText3 Linux 새 버전
SublimeText3 Linux 최신 버전

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

Atom Editor Mac 버전 다운로드
가장 인기 있는 오픈 소스 편집기

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)

