
브라우저의 렌더링 이해: DOM은 어떻게 생성되나요?

- Linda Hamilton원래의
- 2024-11-11 20:14:03895검색
이전 기사에서 DOM과 CSSOM에 대해 배웠습니다. 이 두 단어에 대해 여전히 의문이 든다면 아래 두 게시물을 읽어 보시기 바랍니다.
- 브라우저에서의 렌더링 이해: DOM
- 브라우저에서의 렌더링 이해: CSSOM
요약하자면 DOM은 브라우저가 페이지를 렌더링하는 데 사용하는 구조입니다. 하지만 인터넷 데이터는 DOM 형태로 전송되지 않기 때문에 브라우저가 DOM을 사용할 수 있도록 준비되기 전에 프로세스가 필요합니다.
이 시점에서 인터넷에서 데이터가 어떻게 이동하는지 궁금하실 것입니다.
우리가 웹사이트에 접속할 때마다 클라이언트 x 서버라는 패턴으로 교환이 이루어집니다.
이 교환에서 클라이언트(귀하의 브라우저)는 서버에 웹사이트 www.cristiano.dev에 액세스하도록 요청합니다. 이 웹사이트는 요청된 웹사이트의 모든 콘텐츠로 응답하지만 이 콘텐츠는 바이트 형식으로 어떤 방식으로든 제공됩니다. 이는 우리가 알고 있는 html/css/js와는 거리가 멀습니다.
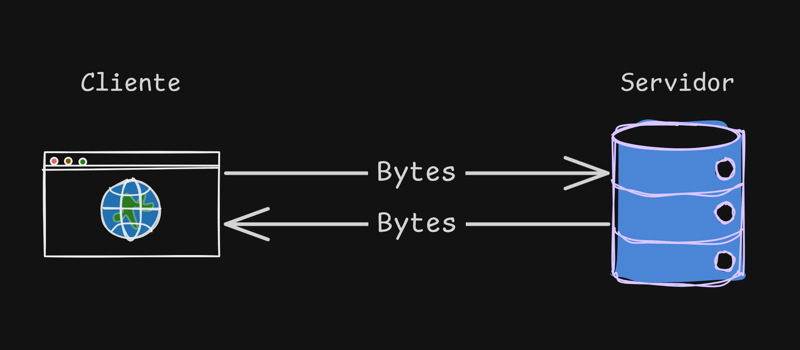
브라우저가 서버로부터 수신하는 것은 일련의 바이트입니다.
서버에서 제공하는 이 작은 HTML 조각의 경우:
<!doctype html>
<html>
<head>
<title>Um título</title>
</head>
<body>
<a href="#">Um link</a>
<h1>Um cabeçalho</h1>
</body>
</html>
브라우저는 다음과 같은 내용을 바이트 단위로 수신합니다.
3C21646F63747970652068746D6C3E0A3C68746D6C3E0A20203C686561643E0A202020203C7469746C653E556D2074C3AD74756C6F3C2F7469746C653E0A20203C2F686561643E0A20203C626F64793E0A202020203C6120687265663D2223223E556D206C696E6B3C2F613E0A202020203C68313E556D2063616265C3A7616C686F3C2F68313E0A20203C2F626F64793E0A3C2F68746D6C3E
그러나 브라우저는 이 정보만으로는 페이지를 렌더링할 수 없습니다. 레이아웃을 조합하기 위해 브라우저는 DOM을 갖기 전에 몇 가지 단계를 수행합니다.
이러한 단계는 다음과 같습니다.
- 전환
- 토큰화
- 렉싱
변환: 바이트를 문자로

이 단계에서 브라우저는 네트워크나 디스크에서 원시 데이터를 읽고 이를 파일에 지정된 인코딩(예: UTF-8)에 따라 문자로 변환합니다.
기본적으로 브라우저가 바이트를 우리가 일상생활에서 쓰는 형식의 코드로 변환하는 단계입니다.
토큰화: 토큰 문자

이 단계에서 브라우저는 문자열을 토큰이라는 작은 단위로 변환합니다. 태그와 콘텐츠의 모든 시작, 끝이 계산되며, 각 토큰에는 특정 규칙 세트가 있습니다.
태그와 속성이 다릅니다.이 단계가 없으면 브라우저에 의미가 없는 텍스트 묶음만 남게 되며 이 프로세스가 끝나면 기본 HTML은 다음과 같이 토큰화됩니다.
- ➔ 토큰: DOCTYPE, 값: html
- ➔ 토큰: 시작태그, 이름: html
- <머리> ➔ 토큰: 시작태그, 이름: head
- ➔ 토큰: 시작태그, 이름: title
- 제목 예시 ➔ 토큰: 문자, 데이터: 제목 예시
- ➔ 토큰: EndTag, 이름: title
-
➔ 토큰: 시작태그, 이름: p
- 안녕하세요 월드! ➔ 토큰: 캐릭터, 데이터: Hello world!
- ➔ 토큰: EndTag, 이름: p

토큰은 텍스트의 개별 단어 또는 기호입니다. "토큰화"는 텍스트를 더 작은 단어, 문구 또는 기호로 나누는 프로세스입니다.
렉싱: 노드용 토큰

렉싱 단계(어휘 분석)는 토큰을 객체로 변환하는 역할을 담당하지만 아직 DOM은 아닙니다. 현재 브라우저는 DOM의 분리된 부분을 생성하고 있으며, 여기서 각 태그는 속성, 상위 태그, 하위 태그 등과 관련된 정보를 가져오는 속성이 있는 객체로 변환됩니다.
태그를 렉싱한 결과
다음과 같습니다.
<!doctype html>
<html>
<head>
<title>Um título</title>
</head>
<body>
<a href="#">Um link</a>
<h1>Um cabeçalho</h1>
</body>
</html>
DOM 구성: DOM용 노드

드디어 DOM 구축 단계에 이르렀습니다!
이 시점에서 브라우저는 html 태그 간의 관계를 고려하고 이러한 관계를 계층적 방식으로 나타내는 트리 데이터 구조에 노드를 결합합니다. 예를 들어 문서의 전체 표현이 생성될 때까지 html 개체는 본문 개체의 부모이고 본문은 단락 개체의 부모입니다.
구성이 끝나면 예제 html은 다음과 같은 개체 트리가 됩니다.
3C21646F63747970652068746D6C3E0A3C68746D6C3E0A20203C686561643E0A202020203C7469746C653E556D2074C3AD74756C6F3C2F7469746C653E0A20203C2F686561643E0A20203C626F64793E0A202020203C6120687265663D2223223E556D206C696E6B3C2F613E0A202020203C68313E556D2063616265C3A7616C686F3C2F68313E0A20203C2F626F64793E0A3C2F68746D6C3E
요약
DOM 구축 프로세스는 복잡하며 다음 단계로 진행됩니다.
- 변환: HTML은 브라우저에서 수신되어 바이트에서 문자로 변환됩니다.
- 토큰화: 문자는 HTML의 일부(태그, 속성, 텍스트)를 나타내는 토큰으로 변환됩니다.
- 렉싱: 토큰은 객체 노드로 구성됩니다
- DOM: 객체는 계층적 방식의 트리형 데이터 구조로 구성됩니다.
CSSOM에서도 변환, 토큰화, 어휘 분석으로 구성된 유사한 프로세스가 진행됩니다.
결론
이 지식을 일상적인 개발 전반에 걸쳐 어디에 적용할지 궁금하실 것입니다...
이러한 유형의 정보가 자주 요청되지는 않는 것이 사실이지만, 기본 프론트엔드 작업 도구인 브라우저가 본질적으로 어떻게 작동하는지 이해하는 것이 중요합니다.
이 지식은 여기서 다룰 다음 주제인 페인트, 다시 칠하기, 흐름 및 리플로우를 이해하는 데에도 매우 유용합니다.
매우 감사합니다!!
여기까지 와주셔서 감사합니다!
이 책을 읽으면서 새로운 것을 배우셨기를 바랍니다.
다음에 또 만나요!
참고자료
객체 모델 구성
웹 해체: 페이지 렌더링
위 내용은 브라우저의 렌더링 이해: DOM은 어떻게 생성되나요?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!