
이미지 분할 마스터하기: 디지털 시대에도 기존 기술이 여전히 빛나는 이유

- DDD원래의
- 2024-09-14 06:23:021119검색
소개
컴퓨터 비전의 가장 기본적인 절차 중 하나인 이미지 분할을 통해 시스템은 이미지 내의 다양한 영역을 분해하고 분석할 수 있습니다. 객체 인식, 의료 영상, 자율 주행 등 무엇을 다루든 분할은 이미지를 의미 있는 부분으로 나누는 것입니다.
이 작업에서 딥 러닝 모델의 인기가 계속 높아지고 있지만 디지털 이미지 처리의 기존 기술은 여전히 강력하고 실용적입니다. 이 게시물에서 검토되는 접근 방식에는 세포 이미지 분석을 위해 잘 알려진 데이터 세트인 MIVIA HEp-2 이미지 데이터 세트를 구현하여 임계값 지정, 가장자리 감지, 지역 기반 및 클러스터링이 포함됩니다.
MIVIA HEp-2 이미지 데이터세트
MIVIA HEp-2 이미지 데이터세트는 HEp-2 세포를 통해 항핵항체(ANA)의 패턴을 분석하는 데 사용되는 세포 사진 세트입니다. 형광현미경을 통해 촬영한 2D 사진으로 구성되어 있습니다. 이는 분할 작업, 특히 세포 영역 감지가 가장 중요한 의료 영상 분석과 관련된 작업에 매우 적합합니다.
이제 F1 점수를 기준으로 성능을 비교하면서 이러한 이미지를 처리하는 데 사용되는 분할 기술을 살펴보겠습니다.
1. 임계값 분할
임계값은 회색조 이미지를 픽셀 강도에 따라 이진 이미지로 변환하는 프로세스입니다. MIVIA HEp-2 데이터세트에서 이 프로세스는 백그라운드에서 세포를 추출하는 데 유용합니다. 특히 Otsu의 방법을 사용하면 최적의 임계값을 자체 계산하므로 상대적으로 큰 수준까지 간단하고 효과적입니다.
Otsu의 방법은 자동 임계값 지정 방법으로, 최소 임계값을 찾아 클래스 내 분산을 최소화하여 전경(셀)과 배경이라는 두 클래스를 분리합니다. 이 방법은 이미지 히스토그램을 검사하고 각 클래스의 픽셀 강도 차이의 합이 최소화되는 완벽한 임계값을 계산합니다.
# Thresholding Segmentation
def thresholding(img):
# Convert image to grayscale
gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
# Apply Otsu's thresholding
_, thresh = cv.threshold(gray, 0, 255, cv.THRESH_BINARY + cv.THRESH_OTSU)
return thresh
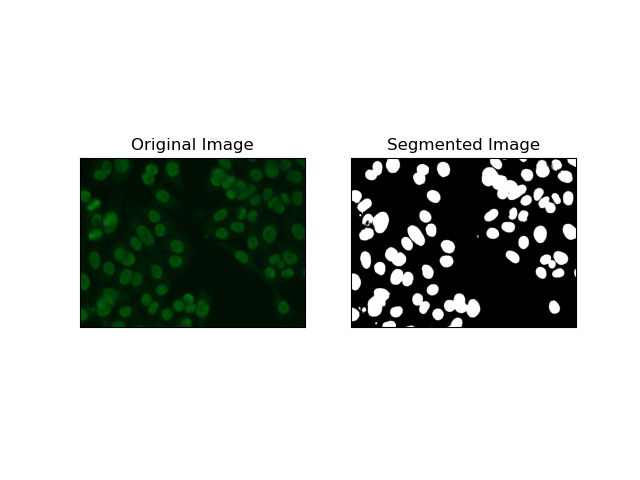
2. 가장자리 감지 분할
가장자리 감지는 MIVIA HEp-2 데이터 세트의 셀 가장자리와 같은 객체 또는 영역의 경계를 식별하는 것과 관련됩니다. 급격한 강도 변화를 감지하는 데 사용할 수 있는 다양한 방법 중에서 Canny Edge Detector가 세포 경계를 감지하는 데 가장 적합하고 가장 적합한 방법입니다.
Canny Edge Detector는 강도 기울기가 강한 영역을 감지하여 가장자리를 감지할 수 있는 다단계 알고리즘입니다. 이 프로세스는 가우스 필터를 사용한 평활화, 강도 기울기 계산, 허위 반응을 제거하기 위한 비최대 억제 적용, 두드러진 가장자리만 유지하기 위한 최종 이중 임계값 연산을 구현합니다.
# Edge Detection Segmentation
def edge_detection(img):
# Convert image to grayscale
gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
# Apply Gaussian blur
gray = cv.GaussianBlur(gray, (3, 3), 0)
# Calculate lower and upper thresholds for Canny edge detection
sigma = 0.33
v = np.median(gray)
lower = int(max(0, (1.0 - sigma) * v))
upper = int(min(255, (1.0 + sigma) * v))
# Apply Canny edge detection
edges = cv.Canny(gray, lower, upper)
# Dilate the edges to fill gaps
kernel = np.ones((5, 5), np.uint8)
dilated_edges = cv.dilate(edges, kernel, iterations=2)
# Clean the edges using morphological opening
cleaned_edges = cv.morphologyEx(dilated_edges, cv.MORPH_OPEN, kernel, iterations=1)
# Find connected components and filter out small components
num_labels, labels, stats, _ = cv.connectedComponentsWithStats(
cleaned_edges, connectivity=8
)
min_size = 500
filtered_mask = np.zeros_like(cleaned_edges)
for i in range(1, num_labels):
if stats[i, cv.CC_STAT_AREA] >= min_size:
filtered_mask[labels == i] = 255
# Find contours of the filtered mask
contours, _ = cv.findContours(
filtered_mask, cv.RETR_EXTERNAL, cv.CHAIN_APPROX_SIMPLE
)
# Create a filled mask using the contours
filled_mask = np.zeros_like(gray)
cv.drawContours(filled_mask, contours, -1, (255), thickness=cv.FILLED)
# Perform morphological closing to fill holes
final_filled_image = cv.morphologyEx(
filled_mask, cv.MORPH_CLOSE, kernel, iterations=2
)
# Dilate the final filled image to smooth the edges
final_filled_image = cv.dilate(final_filled_image, kernel, iterations=1)
return final_filled_image
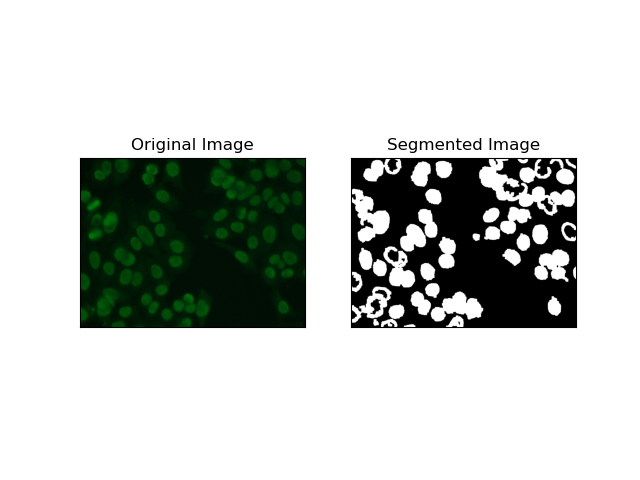
3. 지역 기반 세분화
지역 기반 세분화는 강도나 색상과 같은 특정 기준에 따라 유사한 픽셀을 지역으로 그룹화합니다. 유역 분할 기술을 사용하면 HEp-2 세포 이미지를 분할하여 세포를 나타내는 영역을 감지할 수 있습니다. 픽셀 강도를 지형적 표면으로 간주하고 구별되는 영역의 윤곽을 그립니다.
유역 분할은 픽셀의 강도를 지형 표면으로 처리합니다. 알고리즘은 지역적 최소값을 식별한 다음 점차적으로 이러한 유역을 범람시켜 별개의 지역을 확대하는 "유역"을 식별합니다. 이 기술은 현미경 이미지 내의 세포와 같이 접촉하는 물체를 분리하려고 할 때 매우 유용하지만 노이즈에 민감할 수 있습니다. 마커를 사용하여 프로세스를 안내할 수 있으며 과도한 세분화를 줄일 수 있는 경우가 많습니다.
# Region-Based Segmentation
def region_based(img):
# Convert image to grayscale
gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
# Apply Otsu's thresholding
_, thresh = cv.threshold(gray, 0, 255, cv.THRESH_BINARY_INV + cv.THRESH_OTSU)
# Apply morphological opening to remove noise
kernel = np.ones((3, 3), np.uint8)
opening = cv.morphologyEx(thresh, cv.MORPH_OPEN, kernel, iterations=2)
# Dilate the opening to get the background
sure_bg = cv.dilate(opening, kernel, iterations=3)
# Calculate the distance transform
dist_transform = cv.distanceTransform(opening, cv.DIST_L2, 5)
# Threshold the distance transform to get the foreground
_, sure_fg = cv.threshold(dist_transform, 0.2 * dist_transform.max(), 255, 0)
sure_fg = np.uint8(sure_fg)
# Find the unknown region
unknown = cv.subtract(sure_bg, sure_fg)
# Label the markers for watershed algorithm
_, markers = cv.connectedComponents(sure_fg)
markers = markers + 1
markers[unknown == 255] = 0
# Apply watershed algorithm
markers = cv.watershed(img, markers)
# Create a mask for the segmented region
mask = np.zeros_like(gray, dtype=np.uint8)
mask[markers == 1] = 255
return mask
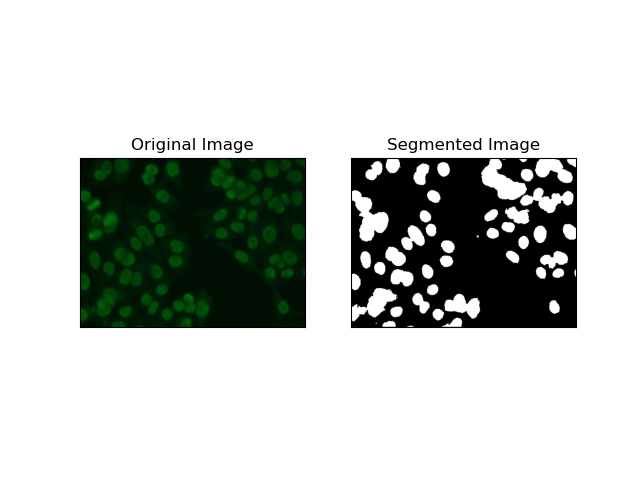
4. 클러스터링 기반 분할
K-평균과 같은 클러스터링 기술은 픽셀을 유사한 클러스터로 그룹화하는 경향이 있으며, 이는 HEp-2 세포 이미지에서 볼 수 있듯이 다색 또는 복잡한 환경에서 세포를 분할하려고 할 때 잘 작동합니다. 기본적으로 이는 셀룰러 영역 대 배경과 같은 다양한 클래스를 나타낼 수 있습니다.
K-means is an unsupervised learning algorithm for clustering images based on the pixel similarity of color or intensity. The algorithm randomly selects K centroids, assigns each pixel to the nearest centroid, and updates the centroid iteratively until it converges. It is particularly effective in segmenting an image that has multiple regions of interest that are very different from one another.
# Clustering Segmentation
def clustering(img):
# Convert image to grayscale
gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
# Reshape the image
Z = gray.reshape((-1, 3))
Z = np.float32(Z)
# Define the criteria for k-means clustering
criteria = (cv.TERM_CRITERIA_EPS + cv.TERM_CRITERIA_MAX_ITER, 10, 1.0)
# Set the number of clusters
K = 2
# Perform k-means clustering
_, label, center = cv.kmeans(Z, K, None, criteria, 10, cv.KMEANS_RANDOM_CENTERS)
# Convert the center values to uint8
center = np.uint8(center)
# Reshape the result
res = center[label.flatten()]
res = res.reshape((gray.shape))
# Apply thresholding to the result
_, res = cv.threshold(res, 0, 255, cv.THRESH_BINARY + cv.THRESH_OTSU)
return res

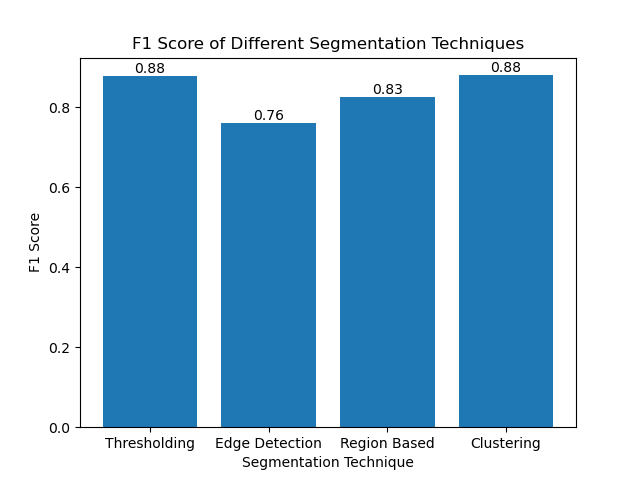
Evaluating the Techniques Using F1 Scores
The F1 score is a measure that combines precision and recall together to compare the predicted segmentation image with the ground truth image. It is the harmonic mean of precision and recall, which is useful in cases of high data imbalance, such as in medical imaging datasets.
We calculated the F1 score for each segmentation method by flattening both the ground truth and the segmented image and calculating the weighted F1 score.
def calculate_f1_score(ground_image, segmented_image):
ground_image = ground_image.flatten()
segmented_image = segmented_image.flatten()
return f1_score(ground_image, segmented_image, average="weighted")
We then visualized the F1 scores of different methods using a simple bar chart:
Conclusion
Although many recent approaches for image segmentation are emerging, traditional segmentation techniques such as thresholding, edge detection, region-based methods, and clustering can be very useful when applied to datasets such as the MIVIA HEp-2 image dataset.
Each method has its strength:
- Thresholding is good for simple binary segmentation.
- Edge Detection is an ideal technique for the detection of boundaries.
- Region-based segmentation is very useful in separating connected components from their neighbors.
- Clustering methods are well-suited for multi-region segmentation tasks.
By evaluating these methods using F1 scores, we understand the trade-offs each of these models has. These methods may not be as sophisticated as what is developed in the newest models of deep learning, but they are still fast, interpretable, and serviceable in a broad range of applications.
Thanks for reading! I hope this exploration of traditional image segmentation techniques inspires your next project. Feel free to share your thoughts and experiences in the comments below!
위 내용은 이미지 분할 마스터하기: 디지털 시대에도 기존 기술이 여전히 빛나는 이유의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!