
주어진 스택에서 중복을 제거하는 Java 프로그램

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB원래의
- 2024-08-28 12:01:04623검색
이 기사에서는 Java의 스택에서 중복 요소를 제거하는 두 가지 방법을 살펴보겠습니다. 중첩 루프를 사용한 간단한 접근 방식과 HashSet을 사용하는 보다 효율적인 방법을 비교해 보겠습니다. 목표는 중복 제거를 최적화하는 방법을 보여주고 각 접근 방식의 성능을 평가하는 것입니다.
문제 설명
스택에서 중복된 요소를 제거하는 Java 프로그램을 작성하세요.
입력
으아아아출력
으아아아주어진 스택에서 중복 항목을 제거하려면 2가지 접근 방식이 있습니다. −
- 순진한 접근 방식: 두 개의 중첩 루프를 만들어 어떤 요소가 이미 존재하는지 확인하고 해당 요소가 결과 스택 반환에 추가되지 않도록 합니다.
- HashSet 접근 방식: Set을 사용하여 고유한 요소를 저장하고 O(1) 복잡성을 활용하여 요소가 있는지 여부를 확인합니다.
임의 스택 생성 및 복제
아래는 Java 프로그램이 먼저 임의의 스택을 구축한 다음 추가 사용을 위해 복사본을 생성하는 것입니다 −
initData 지정된 크기와 1~100 범위의 임의 요소로 스택을 생성하는 데 도움이 됩니다.
manualCloneStack 다른 스택에서 데이터를 복사하여 데이터를 생성하고 이를 두 아이디어 간의 성능 비교에 사용하는 데 도움이 됩니다.
순진한 접근 방식을 사용하여 특정 스택에서 중복 제거
다음은 Naïve 접근 방식을 사용하여 주어진 스택에서 중복 항목을 제거하는 단계입니다 −
- 타이머를 시작하세요.
- 빈 스택을 만들어 고유한 요소를 저장하세요.
- while 루프를 사용하여 반복하고 원래 스택이 비어 있을 때까지 계속해서 최상위 요소를 팝합니다.
- resultStack.contains(element)를 사용하여 중복 항목을 확인하여 해당 요소가 이미 결과 스택에 있는지 확인하세요.
- 요소가 결과 스택에 없으면 resultStack에 추가하세요.
- 종료 시간을 기록하고 소요된 총 시간을 계산하세요.
- 결과 반환
예
아래는 Naïve 접근 방식을 사용하여 주어진 스택에서 중복 항목을 제거하는 Java 프로그램입니다 −
으아아아순진한 접근 방식을 위해 우리는
Stack<Integer> data = initData(10L);는 스택의 모든 요소를 통과하는 첫 번째 루프를 처리하고, 두 번째 루프는
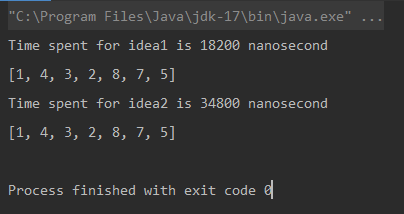
<pre class="brush:php;toolbar:false">Unique elements using Naive Approach: [1, 4, 3, 2, 8, 7, 5]
Time spent for Naive Approach: 18200 nanoseconds
Unique elements using Optimized Approach: [1, 4, 3, 2, 8, 7, 5]
Time spent for Optimized Approach: 34800 nanoseconds</pre>
요소가 이미 존재하는지 확인하는 것입니다.최적화된 접근 방식(HashSet)을 사용하여 주어진 스택에서 중복 항목을 제거합니다(HashSet)
다음은 최적화된 접근 방식을 사용하여 주어진 스택에서 중복 항목을 제거하는 단계입니다 −
- 타이머 시작
- 본 요소를 추적하기 위한 세트를 생성합니다(O(1) 복잡성 검사용).
- 임시 스택을 만들어 고유한 요소를 저장하세요.
- 스택이 빌 때까지 while 루프를 사용하여 반복합니다.
- 스택에서 최상위 요소를 제거합니다.
- 중복 항목을 확인하기 위해 seen.contains(element)를 사용하여 요소가 이미 세트에 있는지 확인합니다.
- 요소가 세트에 없으면 표시된 스택과 임시 스택에 모두 추가하세요.
- 종료 시간을 기록하고 소요된 총 시간을 계산하세요.
- 결과 반환
예
아래는 HashSet −
을 사용하여 주어진 스택에서 중복 항목을 제거하는 Java 프로그램입니다. 으아아아최적화된 접근 방식을 위해
를 사용합니다.private static Stack initData(Long size) {
Stack stack = new Stack < > ();
Random random = new Random();
int bound = (int) Math.ceil(size * 0.75);
for (int i = 0; i < size; ++i) {
stack.add(random.nextInt(bound) + 1);
}
return stack;
}
private static Stack < Integer > manualCloneStack(Stack < Integer > stack) {
Stack < Integer > newStack = new Stack < > ();
for (Integer item: stack) {
newStack.push(item);
}
return newStack;
}고유한 요소를 세트에 저장하려면 임의 요소에 액세스할 때 O(1) 복잡성을 활용하여 요소가 있는지 여부를 확인하는 계산 비용을 줄이세요.
두 가지 접근 방식을 함께 사용
다음은 위에서 언급한 두 가지 접근 방식을 사용하여 특정 스택에서 중복 항목을 제거하는 단계입니다.
- 임의의 정수로 채워진 스택을 생성하기 위해 initData(Long size) 메소드를 사용하여 데이터를 초기화합니다.
- cloneStack(Stack stack) 방법을 사용하여 원본 스택의 정확한 복사본을 생성하는 스택을 복제합니다.
- initData를 사용하여 초기 스택을 생성합니다.
- cloneStack을 사용하여 이 스택을 복제합니다.
- 순진한 접근 방식을 적용하여 원본 스택에서 중복 항목을 제거합니다.
- 복제된 스택에서 중복 항목을 제거하려면 최적화된 접근 방식을 적용하세요.
- 각 방법에 소요된 시간과 두 접근 방식에서 생성된 고유 요소를 표시합니다.
예시
아래는 위에서 언급한 두 가지 접근 방식을 모두 사용하여 스택에서 중복 요소를 제거하는 Java 프로그램입니다. −
으아아아출력
비교
* 측정 단위는 나노초입니다.
public static void main(String[] args) {
Stack<Integer> data1 = initData(<number of stack size want to test>);
Stack<Integer> data2 = manualCloneStack(data1);
idea1(data1);
idea2(data2);
}
| Method | 100 elements | 1000 elements |
10000 elements |
100000 elements |
1000000 elements |
| Idea 1 | 693100 |
4051600 |
19026900 |
114201800 |
1157256000 |
| Idea 2 | 135800 |
681400 |
2717800 |
11489400 |
36456100 |
As observed, the time running for Idea 2 is shorter than for Idea 1 because the complexity of Idea 1 is O(n²), while the complexity of Idea 2 is O(n). So, when the number of stacks increases, the time spent on calculations also increases based on it.
위 내용은 주어진 스택에서 중복을 제거하는 Java 프로그램의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!