
ML의 라벨 인코딩

- 王林원래의
- 2024-08-23 06:01:081305검색
레이블 인코딩은 머신러닝에서 가장 많이 사용되는 기술 중 하나입니다. 범주형 데이터를 숫자 형식으로 변환하는 데 사용됩니다. 따라서 데이터를 모델에 맞출 수 있습니다.
라벨 인코딩을 사용하는 이유를 알아보겠습니다. 문자열 형식의 필수 열을 포함하는 데이터가 있다고 상상해 보세요. 하지만 모델링은 숫자 데이터에서만 작동하기 때문에 이 데이터를 모델에 맞출 수 없습니다. 어떻게 해야 할까요? 피팅할 데이터를 준비할 때 전처리 단계에서 평가되는 생명을 구하는 기술이 바로 라벨 인코딩입니다.
Label Encoder의 작동 방식을 이해하기 위해 Scikit-Learn 라이브러리의 iris 데이터 세트를 사용하겠습니다. 다음 라이브러리가 설치되어 있는지 확인하세요.
pandas scikit-learn
라이브러리로 설치하려면 다음 명령을 실행하세요.
$ python install -U pandas scikit-learn
이제 Google Colab Notebook을 열고 Label Encoder 코딩과 학습에 대해 알아보세요.
코딩하자
- 다음 라이브러리 가져오기부터 시작하세요.
import pandas as pd from sklearn import preprocessing
- iris 데이터 세트를 가져오고 사용을 위해 초기화합니다.
from sklearn.datasets import load_iris iris = load_iris()
- 이제 인코딩하려는 데이터를 선택해야 합니다. 붓꽃의 종 이름을 인코딩하겠습니다.
species = iris.target_names print(species)
출력:
array(['setosa', 'versicolor', 'virginica'], dtype='<U10')
- 전처리에서 LabelEncoder 클래스를 인스턴스화해 보겠습니다.
label_encoder = preprocessing.LabelEncoder()
- 이제 레이블 인코더를 사용하여 데이터를 맞출 준비가 되었습니다.
label_encoder.fit(species)
다음과 유사하게 출력됩니다.
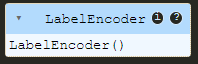
이 결과가 나오면 데이터를 성공적으로 맞춘 것입니다. 그런데 문제는 각 종에 어떤 값이 어떤 순서로 부여되어 있는지 어떻게 알 수 있느냐는 것입니다.
Label Encoder가 데이터에 맞는 순서는 classes_ 속성에 저장됩니다. 인코딩은 0부터 data_length-1까지 시작됩니다.
label_encoder.classes_
출력:
array(['setosa', 'versicolor', 'virginica'], dtype='<U10')
레이블 인코더는 자동으로 데이터를 정렬하고 왼쪽부터 인코딩을 시작합니다. 여기:
setosa -> 0 versicolor -> 1 virginica -> 2
- 이제 피팅된 데이터를 테스트해 보겠습니다. 붓꽃 종인 세토사(setosa)를 변형시켜 보겠습니다.
label_encoder.transform(['setosa'])
출력: 배열([0])
또, 버지니아종을 변형시키면요.
label_encoder.transform(['virginica'])
출력: 배열([2])
["setosa", "virginica"] 등의 종 목록을 입력할 수도 있습니다
레이블 인코더에 대한 Scikit Learn 문서 >>>
위 내용은 ML의 라벨 인코딩의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!