
집 >데이터 베이스 >MySQL 튜토리얼 >인터뷰를 위한 SQL 전체 가이드
인터뷰를 위한 SQL 전체 가이드

- PHPz원래의
- 2024-08-22 14:49:321422검색
구조적 쿼리 언어(SQL)는 MySQL, Oracle, SQL Server, PostgreSQL 등과 같은 관계형 데이터베이스에서 데이터를 생성, 유지 관리, 삭제, 업데이트 및 검색하는 데 사용되는 표준 데이터베이스 언어입니다.
엔터티 관계 모델(ER)
데이터베이스 내의 데이터 구조를 설명하는 데 사용되는 개념적 프레임워크입니다. 이는 실제 개체와 개체 간의 관계를 보다 추상적인 방식으로 표현하도록 설계되었습니다. 프로그래밍 언어의 객체 지향 프로그래밍과 유사합니다.
엔터티: 고객, 제품, 주문 등 뚜렷한 존재감을 지닌 현실 세계의 객체 또는 '사물'입니다.
관계: 엔터티가 서로 관련되는 방식을 정의합니다. 예를 들어 "고객" 엔터티는 "주문" 엔터티와 관계가 있을 수 있습니다
명령:
데이터베이스 생성
create database <database_name>;
데이터베이스 나열
show databases;
데이터베이스 사용
use <database_name>
테이블의 표시 구조
DESCRIBE table_name;
SQL의 하위 언어
데이터 쿼리 언어(DQL):
데이터에 대한 쿼리를 수행하는 데 사용되는 언어입니다. 이 명령은 데이터베이스에서 데이터를 검색하는 데 사용됩니다.
명령:
1) 선택:
select * from table_name; select column1,column2 from table_name; select * from table_name where column1 = "value";
데이터 정의 언어(DDL):
데이터베이스 스키마를 정의하는 데 사용되는 언어입니다. 이 명령은 데이터베이스를 생성, 수정, 삭제하는 데 사용되지만 데이터에는 사용되지 않습니다.
명령
1) 만들기:
create table table_name( column_name data_type(size) constraint, column_name data_type(size) constraint column_name data_type(size) constraint );
2) 드롭:
이 명령은 테이블/데이터베이스를 완전히 제거합니다.
drop table table_name; drop database database_name;
3) 잘림:
이 명령은 데이터만 제거합니다.
truncate table table_name;
4) 변경:
이 명령은 테이블의 열을 추가, 삭제 또는 업데이트할 수 있습니다.
추가
alter table table_name add column_name datatype;
수정
alter table table_name modify column column_name datatype; --ALTER TABLE employees --MODIFY COLUMN salary DECIMAL(10,2);
드롭
alter table table_name drop column_name datatype;
데이터 조작 언어(DML):
데이터베이스에 있는 데이터를 조작하는 데 사용되는 언어
1) 삽입:
이 명령은 새로운 값만 삽입하는 데 사용됩니다.
insert into table_name values (val1,val2,val3,val4); //4 columns
2) 업데이트:
update table_name set col1=val1, col2=val2 where col3 = val3;
3) 삭제:
delete from table_name where col1=val1;
데이터 제어 언어(DCL):
GRANT: 지정된 사용자가 지정된 작업을 수행하도록 허용합니다.
REVOKE: 이전에 부여되거나 거부된 권한을 취소합니다.
트랜잭션 제어 언어(TCL):
데이터베이스에서 트랜잭션을 관리하는 데 사용됩니다. DML 명령으로 수행된 변경 사항을 관리합니다.
1) 커밋
현재 트랜잭션 중에 발생한 모든 변경 사항을 데이터베이스에 저장하는 데 사용됩니다
BEGIN TRANSACTION; UPDATE employees SET salary = salary * 1.1 WHERE department = 'Sales'; COMMIT;
2) 롤백
현재 거래 중에 이루어진 모든 변경 사항을 취소하는 데 사용됩니다
BEGIN TRANSACTION; UPDATE employees SET salary = salary * 1.1 WHERE department = 'Sales'; ROLLBACK;
3) 세이브포인트
begin transaction; update customers set first_name= 'one' WHERE customer_id=4; SAVEPOINT one; update customers set first_name= 'two' WHERE customer_id=4; ROLLBACK TO SAVEPOINT one; COMMIT;
가지고 있는 것:
이 명령은 집계 함수를 기준으로 결과를 필터링하는 데 사용됩니다." WHERE 문에서는 집계 함수를 사용할 수 없으므로 이 명령에서 사용할 수 있습니다."
참고: 구성된 열을 사용하여 비교해야 할 때 사용할 수 있지만 WHERE 명령은 기존 열을 사용하여 비교할 때 사용할 수 있습니다
select Department, sum(Salary) as Salary from employee group by department having sum(Salary) >= 50000;
~ 안에
이 명령은 두 개 이상의 특정 항목을 제외하도록 요청할 때 사용됩니다
select * from table_name
where colname not in ('Germany', 'France', 'UK');
별개의:
이 명령은 선택한 필드를 기반으로 고유한 데이터만 검색하는 데 사용됩니다.
Select distinct field from table;
SELECT COUNT(DISTINCT salesman_id) FROM orders;
상관 쿼리
외부 쿼리의 열을 참조하는 하위 쿼리(다른 쿼리 내에 중첩된 쿼리)입니다
SELECT EmployeeName, Salary
FROM Employees e1
WHERE Salary > (
SELECT AVG(Salary)
FROM Employees e2
WHERE e1.DepartmentID = e2.DepartmentID
);
표준화
정규화는 중복성을 줄이고 데이터 무결성을 향상시키는 방식으로 테이블을 구성하는 데 사용되는 데이터베이스 설계 기술입니다. 정규화의 주요 목표는 데이터 간의 관계를 유지하면서 큰 테이블을 더 작고 관리하기 쉬운 조각으로 나누는 것입니다
제1정규형(1NF)
열의 모든 값은 원자성(분할할 수 없음)입니다.
각 열에는 한 가지 유형의 데이터만 포함됩니다.
EmployeeID | EmployeeName | Department | PhoneNumbers ---------------------------------------------------- 1 | Alice | HR | 123456, 789012 2 | Bob | IT | 345678
1NF 이후:
EmployeeID | EmployeeName | Department | PhoneNumber ---------------------------------------------------- 1 | Alice | HR | 123456 1 | Alice | HR | 789012 2 | Bob | IT | 345678
제2정규형(2NF)
1NF에 있습니다.
키가 아닌 모든 속성은 기본 키에 완전히 기능적으로 종속됩니다(부분 종속성 없음).
EmployeeID | EmployeeName | DepartmentID | DepartmentName --------------------------------------------------------- 1 | Alice | 1 | HR 2 | Bob | 2 | IT
2NF 이후:
EmployeeID | EmployeeName | DepartmentID --------------------------------------- 1 | Alice | 1 2 | Bob | 2 DepartmentID | DepartmentName ------------------------------ 1 | HR 2 | IT
제3정규형(3NF)
2NF에 있습니다.
모든 속성은 기본 키에만 기능적으로 종속됩니다(전이적 종속성은 없음).
EmployeeID | EmployeeN | DepartmentID | Department | DepartmentLocation -------------------------------------------------------------------------- 1 | Alice | 1 | HR | New York 2 | Bob | 2 | IT | Los Angeles
3NF 이후:
EmployeeID | EmployeeN | DepartmentID ---------------------------------------- 1 | Alice | 1 2 | Bob | 2 DepartmentID | DepartmentName | DepartmentLocation ----------------------------------------------- 1 | HR | New York 2 | IT | Los Angeles
노동 조합:
이 명령은 둘 이상의 SELECT 문의 결과를 결합하는 데 사용됩니다
Select * from table_name WHERE (subject = 'Physics' AND year = 1970) UNION (SELECT * FROM nobel_win WHERE (subject = 'Economics' AND year = 1971));
한계:
이 명령은 쿼리에서 검색되는 데이터의 양을 제한하는 데 사용됩니다.
select Department, sum(Salary) as Salary from employee limit 2;
오프셋:
이 명령은 결과를 반환하기 전에 행 수를 건너뛰는 데 사용됩니다.
select Department, sum(Salary) as Salary from employee limit 2 offset 2;
Order By:
This command is used to sort the data based on the field in ascending or descending order.
Data:
create table employees (
id int primary key,
first_name varchar(50),
last_name varchar(50),
salary decimal(10, 2),
department varchar(50)
);
insert into employees (first_name, last_name, salary, department)
values
('John', 'Doe', 50000.00, 'Sales'),
('Jane', 'Smith', 60000.00, 'Marketing'),
('Jim', 'Brown', 60000.00, 'Sales'),
('Alice', 'Johnson', 70000.00, 'Marketing');
select * from employees order by department; select * from employees order by salary desc
Null
This command is used to test for empty values
select * from tablename where colname IS NULL;
Group By
This command is used to arrange similar data into groups using a function.
select department, avg(salary) AS avg_salary from employees group by department;
Like:
This command is used to search a particular pattern in a column.

SELECT * FROM employees WHERE first_name LIKE 'a%';
SELECT * FROM salesman WHERE name BETWEEN 'A' AND 'L';
Wildcard:
Characters used with the LIKE operator to perform pattern matching in string searches.
% - Percent
_ - Underscore
How to print Wildcard characters?
SELECT 'It\'s a beautiful day';
SELECT * FROM table_name WHERE column_name LIKE '%50!%%' ESCAPE '!';
Case
The CASE statement in SQL is used to add conditional logic to queries. It allows you to return different values based on different conditions.
SELECT first_name, last_name, salary,
CASE salary
WHEN 50000 THEN 'Low'
WHEN 60000 THEN 'Medium'
WHEN 70000 THEN 'High'
ELSE 'Unknown'
END AS salary_category
FROM employees;
Display Text
1) Print something
Select "message";
select ' For', ord_date, ',there are', COUNT(ord_no) group by colname;
2) Print numbers in each column
Select 1,2,3;
3) Print some calculation
Select 6x2-1;
4) Print wildcard characters
select colname1,'%',colname2 from tablename;
5) Connect two colnames
select first_name || ' ' || last_name AS colname from employees
6) Use the nth field
select * from orders group by colname order by 2 desc;
Constraints
1) Not Null:
This constraint is used to tell the field that it cannot have null value in a column.
create table employees(
id int(6) not null
);
2) Unique:
This constraint is used to tell the field that it cannot have duplicate value. It can accept NULL values and multiple unique constraints are allowed per table.
create table employees (
id int primary key,
first_name varchar(50) unique
);
3) Primary Key:
This constraint is used to tell the field that uniquely identifies in the table. It cannot accept NULL values and it can have only one primary key per table.
create table employees (
id int primary key
);
4) Foreign Key:
This constraint is used to refer the unique row of another table.
create table employees (
id int primary key
foreign key (id) references owner(id)
);
5) Check:
This constraint is used to check a particular condition for data to be stored.
create table employees (
id int primary key,
age int check (age >= 18)
);
6) Default:
This constraint is used to provide default value for a field.
create table employees (
id int primary key,
age int default 28
);
Aggregate functions
1)Count:
select count(*) as members from employees;
2)Sum:
select sum(salary) as total_amount FROM employees;
3)Average:
select avg(salary) as average_amount FROM employees;
4)Maximum:
select max(salary) as highest_amount FROM employees;
5)Minimum:
select min(salary) as lowest_amount FROM employees;
6)Round:
select round(123.4567, -2) as rounded_value;
Date Functions
1) datediff
select a.id from weather a join weather b on datediff(a.recordDate,b.recordDate)=1 where a.temperature > b.temperature;
2) date_add
select date_add("2017-06-15", interval 10 day);
SECOND
MINUTE
HOUR
DAY
WEEK
MONTH
QUARTER
YEAR
3) date_sub
SELECT DATE_SUB("2017-06-15", INTERVAL 10 DAY);
Joins
Inner Join
This is used to combine two tables based on one common column.
It returns only the rows where there is a match between both tables.
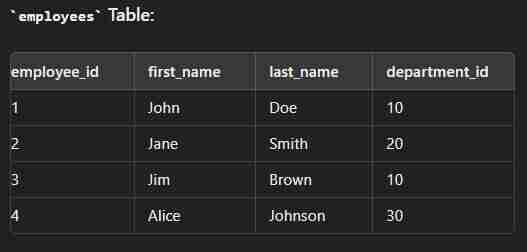
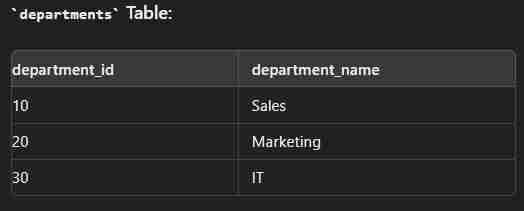
Data
create table employees( employee_id int(2) primary key, first_name varchar(30), last_name varchar(30), department_id int(2) ); create table department( department_id int(2) primary key, department_name varchar(30) ); insert into employees values (1,"John","Dow",10); insert into employees values (2,"Jane","Smith",20); insert into employees values (3,"Jim","Brown",10); insert into employees values (4,"Alice","Johnson",30); insert into department values (10,"Sales"); insert into department values (20,"Marketing"); insert into department values (30,"IT");
select e.employee_id,e.first_name,e.last_name,d.department_name from employees e inner join department d on e.department_id=d.department_id;
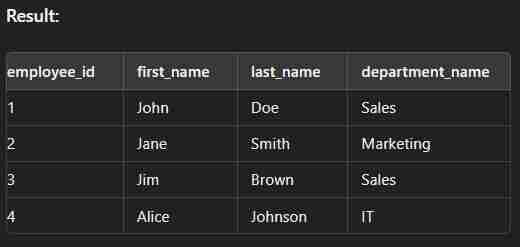
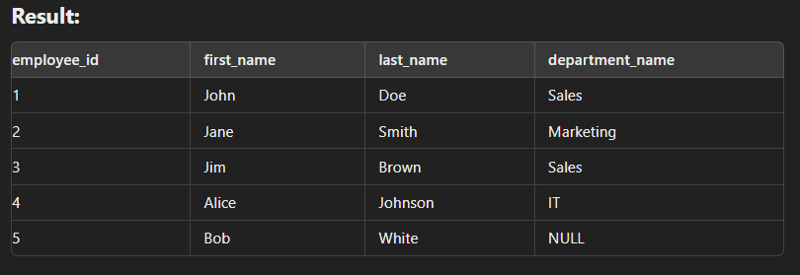
Left Join
This type of join returns all rows from the left table along with the matching rows from the right table. Note: If there are no matching rows in the right side, it return null.
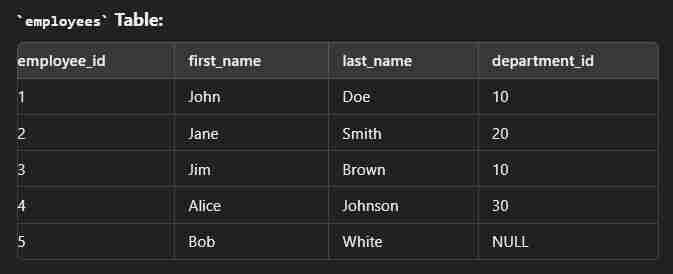
select e.employee_id, e.first_name, e.last_name, d.department_name from employees e left join departments d on e.department_id = d.department_id;
Right Join
This type of join returns all rows from the right table along with the matching rows from the left table. Note: If there are no matching rows in the left side, it returns null.
SELECT e.employee_id, e.first_name, e.last_name, d.department_name FROM employees e RIGHT JOIN departments d ON e.department_id = d.department_id;
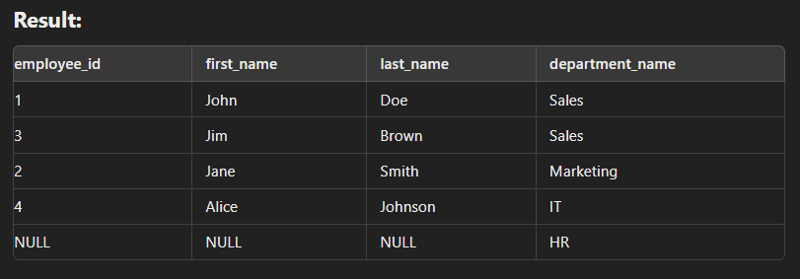
Self Join
This type of join is used to combine with itself especially for creation of new column of same data.
SELECT e.employee_id AS employee_id,
e.first_name AS employee_first_name,
e.last_name AS employee_last_name,
m.first_name AS manager_first_name,
m.last_name AS manager_last_name
FROM employees e
LEFT JOIN employees m ON e.manager_id = m.employee_id;
Full Join/ Full outer join
This type of join is used to combine the result of both left and right join.
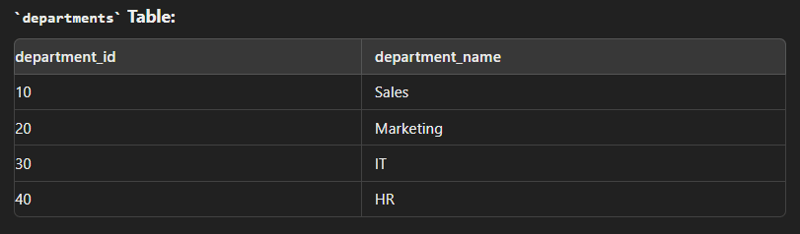
SELECT e.employee_id, e.first_name, e.last_name, d.department_name FROM employees e FULL JOIN departments d ON e.department_id = d.department_id;
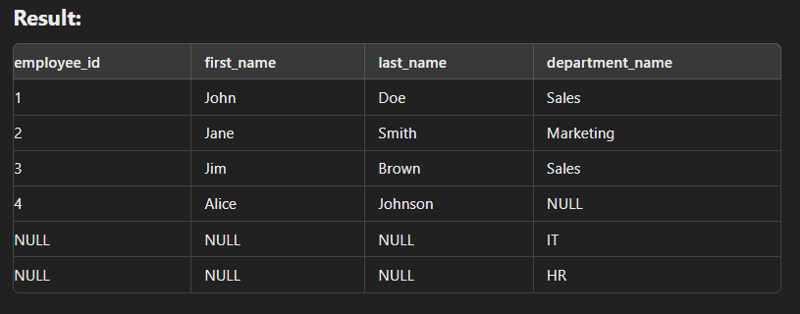
Cross Join
This type of join is used to generate a Cartesian product of two tables.
SELECT e.name, d.department_name FROM Employees e CROSS JOIN Departments d;
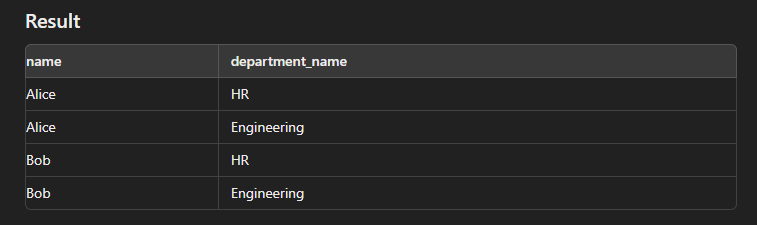
Nested Query
A nested query, also known as a subquery, is a query within another SQL query. The nested query is executed first, and its result is used by the outer query.
Subqueries can be used in various parts of a SQL statement, including the SELECT clause, FROM clause, WHERE clause, and HAVING clause.
1) Nested Query in SELECT Clause:
SELECT e.first_name, e.last_name,
(SELECT d.department_name
FROM departments d
WHERE d.id = e.department_id) AS department_name
FROM employees e;
2) Nested Query in WHERE Clause:
SELECT first_name, last_name, salary FROM employees WHERE salary > (SELECT AVG(salary) FROM employees);
SELECT pro_name, pro_price FROM item_mast WHERE pro_price = (SELECT MIN(pro_price) FROM item_mast);
3) Nested Query in FROM Clause:
SELECT department_id, AVG(salary) AS avg_salary FROM employees GROUP BY department_id;
4) Nested Query with EXISTS:
SELECT customer_name
FROM customers c
WHERE EXISTS (
SELECT 1
FROM orders o
WHERE o.customer_id = c.customer_id
);
Exists
This command is used to test the existence of a particular record. Note: When using EXISTS query, actual data returned by subquery does not matter.
SELECT customer_name
FROM customers c
WHERE EXISTS (
SELECT 1
FROM orders o
WHERE o.customer_id = c.customer_id
);
SELECT customer_name
FROM customers c
WHERE NOT EXISTS (
SELECT 1
FROM orders o
WHERE o.customer_id = c.customer_id
);
COALESCE
The COALESCE function in SQL is used to return the first non-null expression among its arguments. It is particularly useful for handling NULL values and providing default values when dealing with potentially missing or undefined data.
CREATE TABLE employees (
first_name VARCHAR(50),
middle_name VARCHAR(50),
last_name VARCHAR(50)
);
INSERT INTO employees (first_name, middle_name, last_name) VALUES
('John', NULL, 'Doe'),
('Jane', 'Marie', 'Smith'),
('Emily', NULL, 'Johnson');
SELECT
first_name,
COALESCE(middle_name, 'No Middle Name') AS middle_name,
last_name
FROM
employees;
PL/SQL(Procedural Language/Structured Query Language)
It is Oracle's procedural extension to SQL. If multiple SELECT statements are issued, the network traffic increases significantly very fast. For example, four SELECT statements cause eight network trips. If these statements are part of the PL/SQL block, they are sent to the server as a single unit.
Blocks
They are the fundamental units of execution and organization.
1) Named block
Named blocks are used when creating subroutines. These subroutines are procedures, functions, and packages. The subroutines can be stored in the database and referenced by their names later on.
Ex.
CREATE OR REPLACE PROCEDURE procedure_name (param1 IN datatype, param2 OUT datatype) AS BEGIN -- Executable statements END procedure_name;
2) Anonymous
They are blocks do not have names. As a result, they cannot be stored in the database and referenced later.
DECLARE -- Declarations (optional) BEGIN -- Executable statements EXCEPTION -- Exception handling (optional) END;
Declaration
It contains identifiers such as variables, constants, cursors etc
Ex.
declare v_first_name varchar2(35) ; v_last_name varchar2(35) ; v_counter number := 0 ; v_lname students.lname%TYPE; // takes field datatype from column
Rowtype
DECLARE v_student students%rowtype; BEGIN select * into v_student from students where sid='123456'; DBMS_OUTPUT.PUT_LINE(v_student.lname); DBMS_OUTPUT.PUT_LINE(v_student.major); DBMS_OUTPUT.PUT_LINE(v_student.gpa); END;
Execution
It contains executable statements that allow you to manipulate the variables.
declare v_regno number; v_variable number:=0; begin select regno into v_regno from student where regno=1; dbms_output.put_line(v_regno || ' '|| v_variable); end
Input of text
DECLARE v_inv_value number(8,2); v_price number(8,2); v_quantity number(8,0) := 400; BEGIN v_price := :p_price; v_inv_value := v_price * v_quantity; dbms_output.put_line(v_inv_value); END;
If-else loop
IF rating > 7 THEN
v_message := 'You are great';
ELSIF rating >= 5 THEN
v_message := 'Not bad';
ELSE
v_message := 'Pretty bad';
END IF;
Loops
Simple Loop
declare
begin
for i in 1..5 loop
dbms_output.put_line('Value of i: ' || i);
end loop;
end;
While Loop
declare
counter number := 1;
begin
while counter <= 5 LOOP
dbms_output.put_line('Value of counter: ' || counter);
counter := counter + 1;
end loop;
end;
Loop with Exit
declare
counter number := 1;
begin
loop
exit when counter > 5;
dbms_output.put_line('Value of counter: ' || counter);
counter := counter + 1;
end loop;
end;
Procedure
A series of statements accepting and/or returning
zero variables.
--creating a procedure create or replace procedure proc (var in number) as begin dbms_output.put_line(var); end --calling of procedure begin proc(3); end
Function
A series of statements accepting zero or more variables that returns one value.
create or replace function func(var in number) return number is res number; begin select regno into res from student where regno=var; return res; end --function calling declare var number; begin var :=func(1); dbms_output.put_line(var); end
All types of I/O
p_name IN VARCHAR2 p_lname OUT VARCHAR2 p_salary IN OUT NUMBER
Triggers
DML (Data Manipulation Language) triggers are fired in response to INSERT, UPDATE, or DELETE operations on a table or view.
BEFORE Triggers:
Execute before the DML operation is performed.
AFTER Triggers:
Execute after the DML operation is performed.
INSTEAD OF Triggers:
Execute in place of the DML operation, typically used for views.
Note: :new represents the cid of the new row in the orders table that was just inserted.
create or replace trigger t_name after update on student for each row begin dbms_output.put_line(:NEW.regno); end --after updation update student set name='name' where regno=1;
Window function
SELECT
id,name,gender,
ROW_NUMBER() OVER(
PARTITION BY name
order by gender
) AS row_number
FROM student;
SELECT
employee_id,
department_id,
salary,
RANK() OVER(
PARTITION BY department_id
ORDER BY salary DESC
) AS salary_rank
FROM employees;
ACID Properties:
Atomicity:
All operations within a transaction are treated as a single unit.
Ex. Consider a bank transfer where money is being transferred from one account to another. Atomicity ensures that if the debit from one account succeeds, the credit to the other account will also succeed. If either operation fails, the entire transaction is rolled back to maintain consistency.
일관성:
일관성은 트랜잭션 전후에 데이터베이스가 일관된 상태를 유지하도록 보장합니다.
예 이체 거래로 인해 한 계좌의 잔액이 줄어들면 받는 계좌의 잔액도 늘어나야 합니다. 이는 시스템의 전반적인 균형을 유지합니다.
격리:
격리를 통해 트랜잭션의 동시 실행으로 인해 트랜잭션이 순차적으로, 즉 차례로 실행되는 경우 얻을 수 있는 시스템 상태가 생성됩니다.
전. 두 개의 트랜잭션 T1과 T2를 고려하십시오. T1이 계좌 A에서 계좌 B로 자금을 이체하고 T2가 계좌 A의 잔액을 확인하는 경우 격리를 통해 T2는 이체 전(T1이 아직 커밋하지 않은 경우) 또는 이체 후(T1이 있는 경우) 계좌 A의 잔액을 볼 수 있습니다. 커밋됨), 중간 상태는 아닙니다.
내구성:
내구성은 일단 트랜잭션이 커밋되면 그 효과가 영구적이고 시스템 오류가 발생해도 유지되도록 보장합니다. 시스템이 충돌하거나 다시 시작하더라도 트랜잭션으로 인한 변경 사항은 손실되지 않습니다.
데이터 유형
1) 숫자 데이터 유형
정수
decimal(p,q) - p는 크기, q는 정밀도
2) 문자열 데이터 유형
문자(값) - 최대(8000) && 불변
varchar(값) - 최대(8000)
텍스트 - 최대 크기
3) 날짜 데이터 유형
날짜
시간
날짜시간
위 내용은 인터뷰를 위한 SQL 전체 가이드의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!