
다중 모드 모델 평가 프레임워크 lmms-eval이 출시되었습니다! 포괄적인 적용 범위, 저렴한 비용, 무공해

- 王林원래의
- 2024-08-21 16:38:07554검색

AIxiv 칼럼은 본 사이트에 학술 및 기술 콘텐츠를 게재하기 위한 칼럼입니다. 지난 몇 년 동안 이 사이트의 AIxiv 칼럼에는 전 세계 주요 대학 및 기업의 최고 연구실을 대상으로 한 2,000개 이상의 보고서가 접수되어 학술 교류 및 보급을 효과적으로 촉진하고 있습니다. 공유하고 싶은 훌륭한 작품이 있다면 자유롭게 기여하거나 보고를 위해 연락주시기 바랍니다. 제출 이메일: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
대형 모델에 대한 연구가 심화됨에 따라 이를 더 많은 양식으로 홍보하는 방법이 생겼습니다. 학계와 업계에서 화제가 되고 있습니다. 최근 출시된 GPT-4o, Claude 3.5 등 대형 클로즈드 소스 모델은 이미 강력한 이미지 이해 능력을 갖추고 있으며, LLaVA-NeXT, MiniCPM, InternVL 등 오픈소스 필드 모델도 클로즈드 소스에 가까워지는 성능을 보여주고 있다. .
"무당 80,000kg", "10일에 하나의 SoTA" 시대에 사용하기 쉽고, 투명한 표준을 갖고, 재현 가능한 다중 모드 평가 프레임워크가 점점 더 중요해지고 있습니다. 그리고 이것은 쉽지 않습니다.
위 문제를 해결하기 위해 난양기술대학교 LMMs-Lab 연구진은 멀티모달 대규모 모델(LMM)을 위해 특별히 설계된 평가 프레임워크인 LMMs-Eval을 공동으로 오픈소스화했습니다. 평가는 원스톱, 효율적인 솔루션을 제공합니다.

-
코드 저장소: https://github.com/EvolvingLMMs-Lab/lmms-eval
공식 홈페이지: https://lmms-lab.github.io/
페이퍼 주소: https:// arxiv.org/abs/2407.12772
목록 주소: https://huggingface.co/spaces/lmms-lab/LiveBench
# 🎜🎜#

표준화된 평가 프레임워크
표준화된 평가 플랫폼을 제공하기 위해 LMM은- Eval 다음 기능이 포함되어 있습니다:- 통합 인터페이스: LMMs-Eval은 모델과 데이터 A를 정의하여 텍스트 평가 프레임워크 lm-evaluation-harness를 기반으로 개선 및 확장되었습니다. 컬렉션 및 평가 지표를 위한 통합 인터페이스를 통해 사용자는 새로운 다중 모드 모델 및 데이터 세트를 쉽게 추가할 수 있습니다.
- 원클릭 실행: LMMs-Eval은 HuggingFace에서 80개가 넘는(계속 증가하고 있는) 데이터 세트를 호스팅하며 모든 변형, 버전 및 분할을 포함하여 원본 소스에서 신중하게 변환됩니다. 사용자는 어떤 준비도 할 필요가 없습니다. 단 하나의 명령으로 여러 데이터 세트와 모델이 자동으로 다운로드되어 테스트되며 결과는 몇 분 안에 제공됩니다.
- 투명하고 재현 가능: LMMs-Eval에는 모델이 답변한 각 질문과 그것이 올바른지 여부가 기록되는 통합 로깅 도구가 내장되어 있습니다. 재현성과 투명성. 또한 다양한 모델의 장점과 단점을 쉽게 비교할 수 있습니다.
리뷰의 "불가능한 삼각형"
LMMs-Eval의 궁극적인 목표는 1. 넓은 커버리지 2. 저렴한 비용 3. LMM 평가에 대한 데이터 공개 제로 접근 방식. 그러나 LMMs-Eval을 사용하더라도 저자 팀은 세 가지를 동시에 수행하는 것이 어렵거나 심지어 불가능하다는 사실을 발견했습니다. 아래 그림과 같이 평가 데이터 세트를 50개 이상으로 확장했을 때 이러한 데이터 세트에 대한 종합적인 평가를 수행하는 데 매우 많은 시간이 소요되었습니다. 또한 이러한 벤치마크는 훈련 중에 오염되기 쉽습니다. 이를 위해 LMMs-Eval은 넓은 커버리지와 저렴한 비용을 고려하여 LMMs-Eval-Lite를 제안했습니다. 또한 LiveBench는 비용이 저렴하고 데이터 유출이 전혀 발생하지 않도록 설계되었습니다.
LMMs-Eval-Lite: 폭넓은 커버리지 경량 평가
Apabila menilai model besar, bilangan besar parameter dan tugasan ujian sering meningkatkan masa dan kos tugas penilaian secara mendadak Oleh itu, orang sering memilih untuk menggunakan set data yang lebih kecil atau menggunakan set data khusus untuk penilaian. Walau bagaimanapun, penilaian terhad selalunya membawa kepada kekurangan pemahaman tentang keupayaan model Untuk mengambil kira kedua-dua kepelbagaian penilaian dan kos penilaian, LMMs-Eval melancarkan LMMs-Eval-Lite

LMMs-Eval-. Lite. Kami sedang membina set penanda aras yang dipermudahkan untuk memberikan isyarat yang berguna dan pantas semasa pembangunan model, dengan itu mengelakkan masalah kembung ujian hari ini. Jika kita boleh menemui subset set ujian sedia ada yang mana skor mutlak dan kedudukan relatif antara model kekal serupa dengan set penuh, maka kita boleh menganggap ia selamat untuk memangkas set data ini.
Untuk mencari titik penting data dalam set data, LMMs-Eval terlebih dahulu menggunakan model CLIP dan BGE untuk menukar set data penilaian berbilang modal ke dalam bentuk pembenaman vektor dan menggunakan kaedah pengelompokan k-greedy untuk mencari titik penting data. Dalam ujian, set data yang lebih kecil ini masih menunjukkan keupayaan penilaian yang serupa dengan set penuh.

Seterusnya, LMMs-Eval menggunakan kaedah yang sama untuk menghasilkan versi Lite yang meliputi lebih banyak set data ini direka untuk membantu orang ramai menjimatkan kos penilaian semasa pembangunan untuk menilai prestasi model dengan pantas

: LiveBench. Ujian dinamik LMM
Tanda aras tradisional memberi tumpuan kepada penilaian statik menggunakan soalan dan jawapan tetap. Dengan kemajuan penyelidikan berbilang modal, model sumber terbuka selalunya lebih baik daripada model komersial, seperti GPT-4V, dalam perbandingan skor, tetapi mereka ketinggalan dalam pengalaman pengguna sebenar. Arena Chatbots dan WildVision yang dinamik, terarah pengguna menjadi semakin popular untuk penilaian model, tetapi mereka memerlukan pengumpulan beribu-ribu pilihan pengguna dan sangat mahal untuk dinilai.
Idea teras LiveBench adalah untuk menilai prestasi model pada set data yang dikemas kini secara berterusan untuk mencapai sifar pencemaran dan mengekalkan kos yang rendah. Pasukan pengarang mengumpul data penilaian daripada web dan membina saluran paip untuk mengumpulkan maklumat global terkini secara automatik daripada tapak web seperti berita dan forum komuniti. Untuk memastikan ketepatan masa dan kesahihan maklumat, pasukan pengarang memilih sumber daripada lebih 60 saluran berita termasuk CNN, BBC, Asahi Shimbun Jepun dan Agensi Berita Xinhua China, serta forum seperti Reddit. Langkah-langkah khusus adalah seperti berikut:
Tangkap tangkapan skrin halaman utama dan alih keluar iklan dan elemen bukan berita.
Reka bentuk set soal jawab menggunakan model berbilang modal yang paling berkuasa pada masa ini, seperti GPT4-V, Claude-3-Opus dan Gemini-1.5-Pro.
Soalan disemak dan disemak oleh model lain untuk memastikan ketepatan dan kaitan.
Set soalan dan jawapan akhir disemak secara manual, kira-kira 500 soalan dikumpul setiap bulan, dan 100-300 dikekalkan sebagai set soalan livebench akhir.
Menggunakan kriteria pemarkahan LLaVA-Wilder dan Vibe-Eval -- skor model pemarkahan berdasarkan jawapan standard yang disediakan, dan julat skor ialah [1, 10]. Model pemarkahan lalai ialah GPT-4o, dengan Claude-3-Opus dan Gemini 1.5 Pro turut disertakan sebagai alternatif. Keputusan akhir yang dilaporkan akan berdasarkan skor yang ditukar kepada metrik ketepatan antara 0 hingga 100.
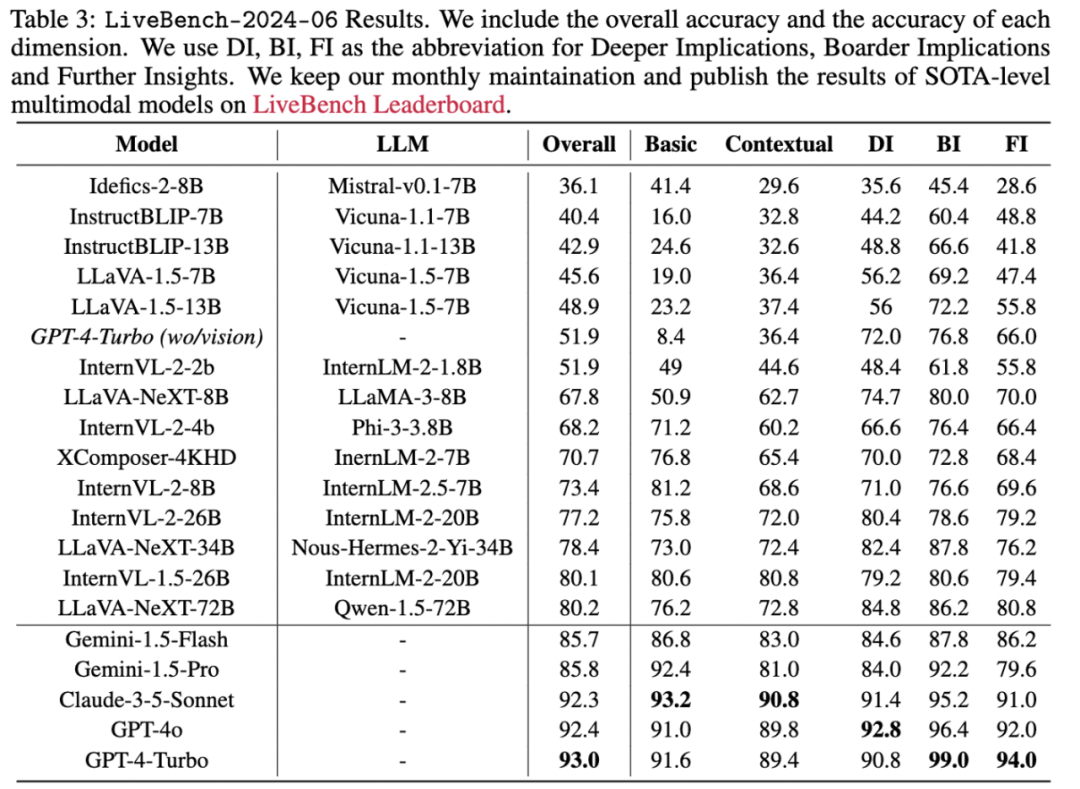
Pada masa hadapan, anda juga boleh melihat data penilaian terkini model berbilang modal yang dikemas kini secara dinamik setiap bulan dalam senarai kami yang dikemas kini secara dinamik, serta keputusan penilaian terkini dalam senarai.
위 내용은 다중 모드 모델 평가 프레임워크 lmms-eval이 출시되었습니다! 포괄적인 적용 범위, 저렴한 비용, 무공해의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!