
OpenCV를 사용한 이미지 압축에 대한 전체 가이드

- PHPz원래의
- 2024-08-21 06:01:321153검색
이미지 압축은 시각적 품질을 유지하면서 이미지를 보다 효율적으로 저장하고 전송할 수 있게 해주는 컴퓨터 비전의 중요한 기술입니다. 이상적으로는 최고의 품질을 갖춘 작은 파일을 갖고 싶습니다. 그러나 우리는 균형을 이루고 어느 것이 더 중요한지 결정해야 합니다.
이 튜토리얼에서는 OpenCV를 사용한 이미지 압축에 대해 설명하고 이론과 실제 적용을 다룹니다. 마지막에는 컴퓨터 비전 프로젝트(또는 다른 프로젝트)를 위해 사진을 성공적으로 압축하는 방법을 이해하게 될 것입니다.
이미지 압축이란 무엇입니까?
이미지 압축은 허용 가능한 수준의 시각적 품질을 유지하면서 이미지의 파일 크기를 줄이는 것입니다. 압축에는 두 가지 주요 유형이 있습니다.
- 무손실 압축: 모든 원본 데이터를 보존하여 정확한 이미지 재구성이 가능합니다.
- 손실 압축: 파일 크기를 줄이기 위해 일부 데이터를 삭제하므로 이미지 품질이 저하될 수 있습니다.
이미지를 압축하는 이유는 무엇입니까?
자주 듣는 것처럼 "디스크 공간이 저렴하다"면 왜 이미지를 압축합니까? 소규모에서는 이미지 압축이 크게 중요하지 않지만 대규모에서는 매우 중요합니다.
예를 들어, 하드 드라이브에 이미지가 몇 개 있는 경우 해당 이미지를 압축하여 몇 메가바이트의 데이터를 저장할 수 있습니다. 하드 드라이브를 테라바이트 단위로 측정하는 경우 이는 큰 영향을 미치지 않습니다. 하지만 하드 드라이브에 100,000개의 이미지가 있다면 어떨까요? 일부 기본 압축은 실시간 시간과 비용을 절약해 줍니다. 성능 측면에서도 마찬가지다. 이미지가 많은 웹사이트가 있고 하루에 10,000명의 사람들이 웹사이트를 방문한다면 압축이 중요합니다.
우리가 그렇게 하는 이유는 다음과 같습니다.
- 저장 요구 사항 감소: 같은 공간에 더 많은 이미지 저장
- 더 빠른 전송: 웹 애플리케이션 및 대역폭이 제한된 시나리오에 이상적
- 처리 속도 향상: 작은 이미지를 로드하고 처리하는 속도가 더 빠릅니다
이미지 압축에 대한 이론
이미지 압축 기술은 두 가지 유형의 중복성을 활용합니다.
- 공간적 중복성: 인접 픽셀 간의 상관관계
- 색상 중복성: 인접 영역의 색상 값 유사성
공간 중복성은 대부분의 자연 이미지에서 인접 픽셀이 유사한 값을 갖는 경향이 있다는 사실을 활용합니다. 이렇게 하면 부드러운 전환이 생성됩니다. 한 영역에서 다른 영역으로 자연스러운 흐름이 있기 때문에 많은 사진이 "실제처럼 보입니다". 인접한 픽셀의 값이 크게 다른 경우 "노이즈가 있는" 이미지가 나타납니다. 픽셀을 단일 색상으로 그룹화하여 이미지를 더 작게 만들어 이러한 전환을 덜 "부드럽게" 만들기 위해 픽셀이 변경되었습니다.

색상 중복은 이미지의 인접한 영역이 유사한 색상을 공유하는 경우가 얼마나 많은지에 중점을 둡니다. 푸른 하늘이나 녹색 들판을 생각해 보세요. 이미지의 많은 부분이 매우 유사한 색상 값을 가질 수 있습니다. 공간을 절약하기 위해 함께 그룹화하여 단일 색상으로 만들 수도 있습니다.

OpenCV는 이러한 아이디어를 작업할 수 있는 견고한 도구를 제공합니다. 예를 들어 OpenCV의 cv2.inpaint() 함수는 공간 중복성을 사용하여 근처 픽셀의 정보를 사용하여 그림의 누락되거나 손상된 영역을 채웁니다. OpenCV를 사용하면 개발자는 cv2.cvtColor()를 사용하여 색상 중복과 관련된 여러 색상 공간 간에 이미지를 변환할 수 있습니다. 특정 종류의 이미지를 인코딩할 때 일부 색상 공간이 다른 색상 공간보다 더 효과적이기 때문에 이는 다양한 압축 기술의 전처리 단계로 어느 정도 도움이 될 수 있습니다.
이제 이 이론 중 일부를 테스트해 보겠습니다. 그것을 가지고 놀자.
이미지 압축 실습
OpenCV의 Python 바인딩을 사용하여 이미지를 압축하는 방법을 살펴보겠습니다. 이 코드를 작성하거나 복사하세요.
여기에서 소스 코드를 얻을 수도 있습니다
import cv2
import numpy as np
def compress_image(image_path, quality=90):
# Read the image
img = cv2.imread(image_path)
# Encode the image with JPEG compression
encode_param = [int(cv2.IMWRITE_JPEG_QUALITY), quality]
_, encoded_img = cv2.imencode('.jpg', img, encode_param)
# Decode the compressed image
decoded_img = cv2.imdecode(encoded_img, cv2.IMREAD_COLOR)
return decoded_img
# Example usage
original_img = cv2.imread('original_image.jpg')
compressed_img = compress_image('original_image.jpg', quality=50)
# Display results
cv2.imshow('Original', original_img)
cv2.imshow('Compressed', compressed_img)
cv2.waitKey(0)
cv2.destroyAllWindows()
# Calculate compression ratio
original_size = original_img.nbytes
compressed_size = compressed_img.nbytes
compression_ratio = original_size / compressed_size
print(f"Compression ratio: {compression_ratio:.2f}")
이 예에는 두 개의 매개변수를 사용하는 압축_이미지 함수가 포함되어 있습니다.
- 이미지 경로(이미지가 위치한 곳)
- 품질(원하는 이미지의 품질)
그런 다음 원본 이미지를 original_img에 로드하겠습니다. 그런 다음 동일한 이미지를 50% 압축하여 새 인스턴스인 압축 이미지에 로드합니다.
그럼 원본과 압축 이미지를 나란히 보실 수 있도록 보여드리겠습니다.
그런 다음 압축률을 계산하여 표시합니다.
이 예제는 OpenCV에서 JPEG 압축을 사용하여 이미지를 압축하는 방법을 보여줍니다. 품질 매개변수는 파일 크기와 이미지 품질의 균형을 제어합니다.
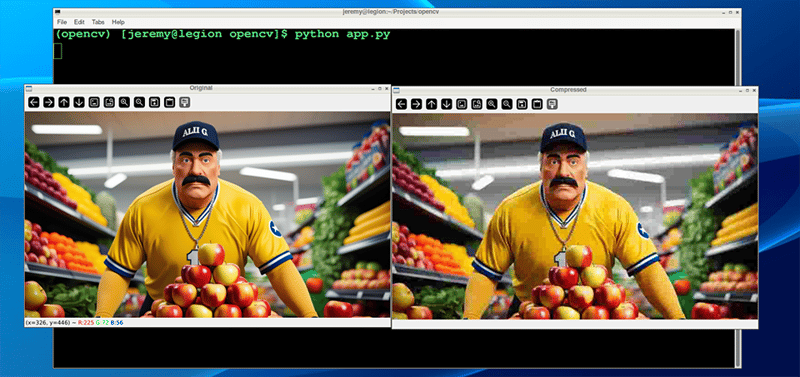
실행해 보겠습니다.

While intially looking at the images, you see little difference. However, zooming in shows you the difference in the quality:
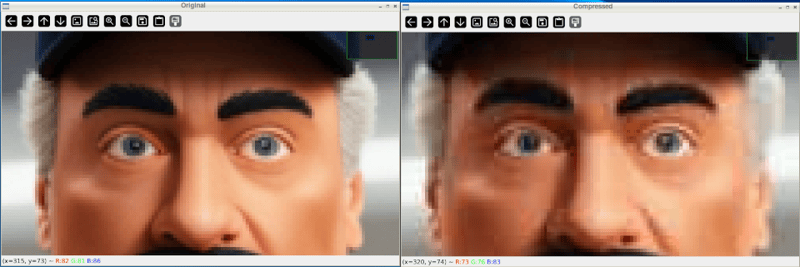
And after closing the windows and looking at the files, we can see the file was reduced in size dramatically:

Also, if we take it down further, we can change our quality to 10%
compressed_img = compress_image('sampleimage.jpg', quality=10)
And the results are much more drastic:
And the file size results are more drastic as well:

You can adjust these parameters quite easily and achieve the desired balance between quality and file size.
Evaluating Compression Quality
To assess the impact of compression, we can use metrics like:
- Mean Squared Error (MSE)
Mean Squared Error (MSE) measures how different two images are from each other. When you compress an image, MSE helps you determine how much the compressed image has changed compared to the original.
It does this by sampling the differences between the colors of corresponding pixels in the two images, squaring those differences, and averaging them. The result is a single number: a lower MSE means the compressed image is closer to the original. In comparison, a higher MSE means there's a more noticeable loss of quality.
Here's some Python code to measure that:
def calculate_mse(img1, img2):
return np.mean((img1 - img2) ** 2)
mse = calculate_mse(original_img, compressed_img)
print(f"Mean Squared Error: {mse:.2f}")
Here's what our demo image compression looks like:

- Peak Signal-to-Noise Ratio (PSNR)
Peak Signal-to-Noise Ratio (PSNR) is a measure that shows how much an image's quality has degraded after compression. This is often visible with your eyes, but it assigns a set value. It compares the original image to the compressed one and expresses the difference as a ratio.
A higher PSNR value means the compressed image is closer in quality to the original, indicating less loss of quality. A lower PSNR means more visible degradation. PSNR is often used alongside MSE, with PSNR providing an easier-to-interpret scale where higher is better.
Here is some Python code that measures that:
def calculate_psnr(img1, img2):
mse = calculate_mse(img1, img2)
if mse == 0:
return float('inf')
max_pixel = 255.0
return 20 * np.log10(max_pixel / np.sqrt(mse))
psnr = calculate_psnr(original_img, compressed_img)
print(f"PSNR: {psnr:.2f} dB")
Here's what our demo image compression looks like:
"Eyeballing" your images after compression to determine quality is fine; however, at a large scale, having scripts do this is a much easier way to set standards and ensure the images follow them.
Let's look at a couple other techniques:
Advanced Compression Techniques
For more advanced compression, OpenCV supports various algorithms:
- PNG Compression:
You can convert your images to PNG format, which has many advantages. Use the following line of code, and you can set your compression from 0 to 9, depending on your needs. 0 means no compression whatsoever, and 9 is maximum. Keep in mind that PNGs are a "lossless" format, so even at maximum compression, the image should remain intact. The big trade-off is file size and compression time.
Here is the code to use PNG compression with OpenCV:
cv2.imwrite('compressed.png', img, [cv2.IMWRITE_PNG_COMPRESSION, 9])
And here is our result:
Note: You may notice sometimes that PNG files are actually larger in size, as in this case. It depends on the content of the image.
- WebP Compression:
You can also convert your images to .webp format. This is a newer method of compression that's gaining in popularity. I have been using this compression on the images on my blog for years.
In the following code, we can write our image to a webp file and set the compression level from 0 to 100. It's the opposite of PNG's scale because 0, because we're setting quality instead of compression. This small distinction matters, because a setting of 0 is the lowest possible quality, with a small file size and significant loss. 100 is the highest quality, which means large files with the best image quality.
Here's the Python code to make that happen:
cv2.imwrite('compressed.webp', img, [cv2.IMWRITE_WEBP_QUALITY, 80])
And here is our result:

These two techniques are great for compressing large amounts of data. You can write scripts to compress thousands or hundreds of thousands of images automatically.
Conclusion
Image compression is fantastic. It's essential for computer vision tasks in many ways, especially when saving space or increasing processing speed. There are also many use cases outside of computer vision anytime you want to reduce hard drive space or save bandwidth. Image compression can help a lot.
By understanding the theory behind it and applying it, you can do some powerful things with your projects.
Remember, the key to effective compression is finding the sweet spot between file size reduction and maintaining acceptable visual quality for your application.
Thanks for reading, and feel free to reach out if you have any comments or questions!
위 내용은 OpenCV를 사용한 이미지 압축에 대한 전체 가이드의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!