
Non-Transformer 아키텍처가 돋보입니다! 오픈소스 거대 기업 Llama 3.1을 능가하는 최초의 순수 주목없는 대형 모델

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB원래의
- 2024-08-13 16:37:46523검색
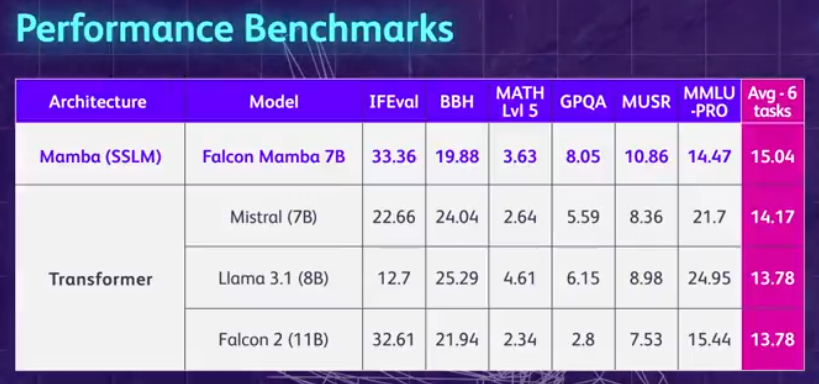
맘바 아키텍처의 대형 모델이 다시 한 번 트랜스포머에 도전했습니다.




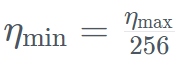 を超える指数計画を使用して最小値まで減衰させます。同時に、TII は加速フェーズで BatchScaling を使用して学習率 η を再調整し、アダム ノイズ温度
を超える指数計画を使用して最小値まで減衰させます。同時に、TII は加速フェーズで BatchScaling を使用して学習率 η を再調整し、アダム ノイズ温度 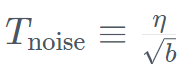 が一定に保たれるようにします。
が一定に保たれるようにします。 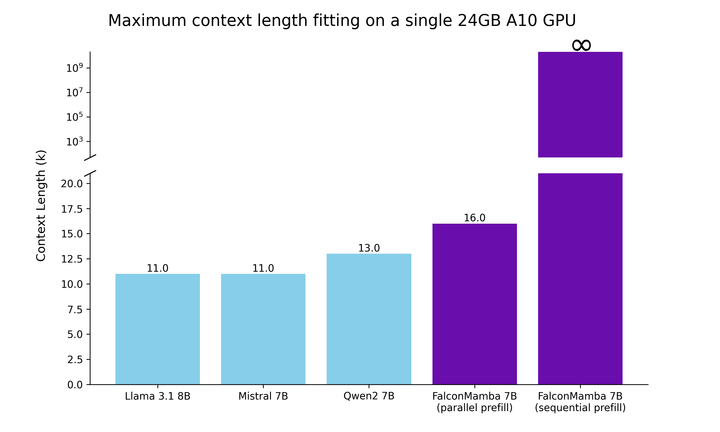
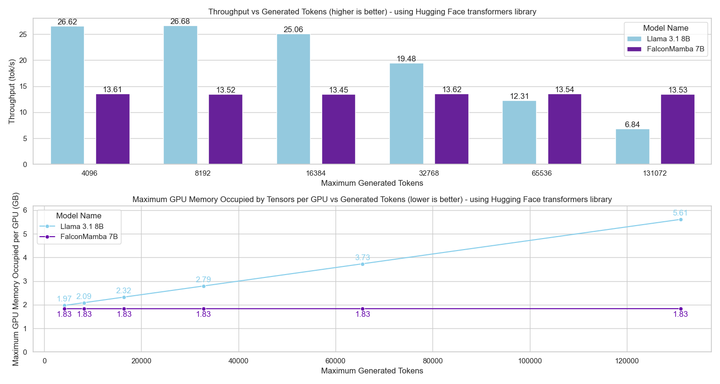
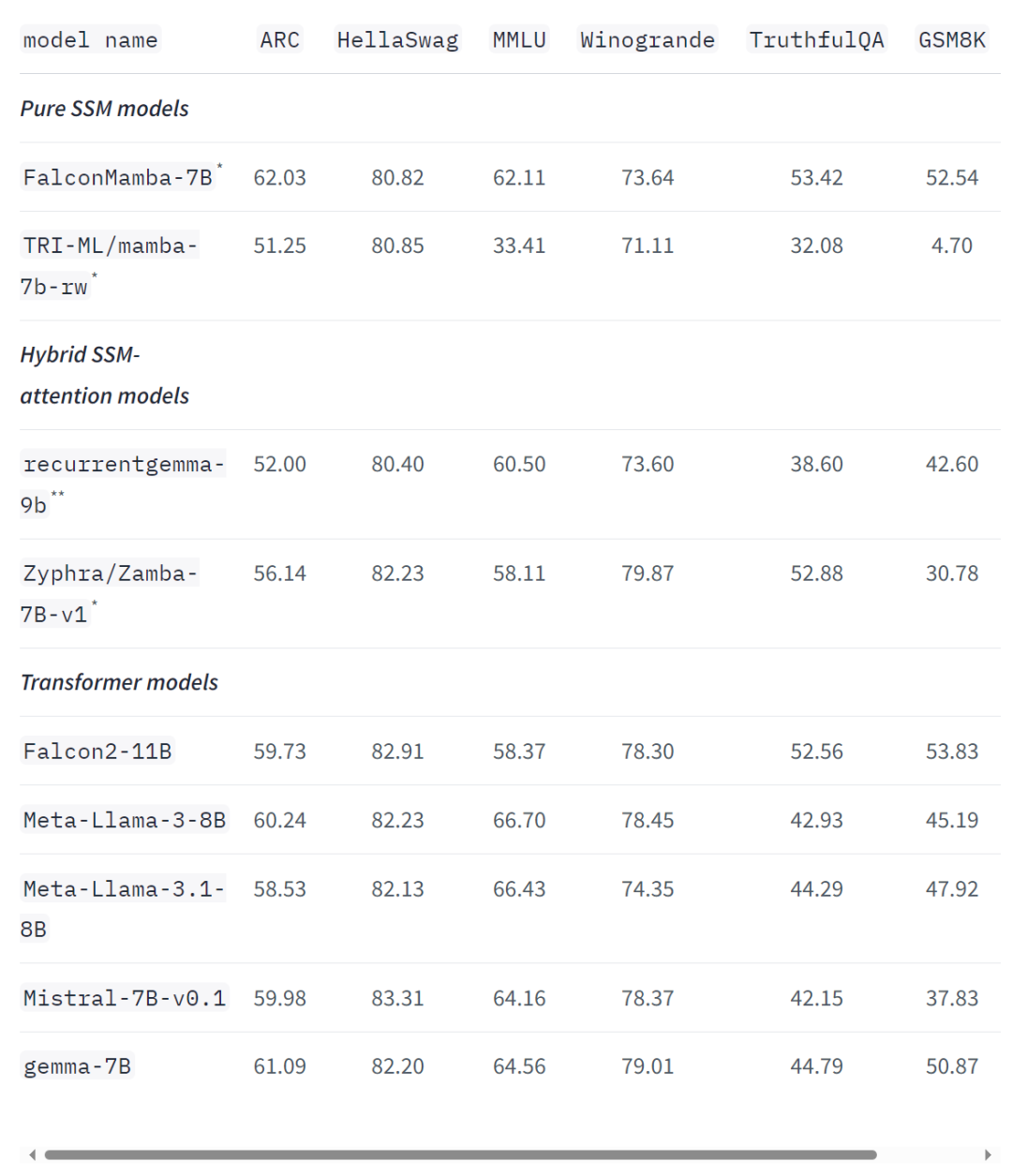

위 내용은 Non-Transformer 아키텍처가 돋보입니다! 오픈소스 거대 기업 Llama 3.1을 능가하는 최초의 순수 주목없는 대형 모델의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!
성명:
본 글의 내용은 네티즌들의 자발적인 기여로 작성되었으며, 저작권은 원저작자에게 있습니다. 본 사이트는 이에 상응하는 법적 책임을 지지 않습니다. 표절이나 침해가 의심되는 콘텐츠를 발견한 경우 admin@php.cn으로 문의하세요.