대형 모델의 반복 속도가 점점 빨라짐에 따라 훈련 클러스터의 규모가 점점 커지고, 빈번한 소프트웨어 및 하드웨어 오류가 훈련 효율성의 추가 향상을 방해하는 문제점이 되었습니다. 훈련 과정 중 상태를 담당합니다. 저장 및 복구는 훈련 실패를 극복하고 훈련 진행을 보장하며 훈련 효율성을 향상시키는 열쇠가 되었습니다.
최근 ByteDance Beanbao 모델팀과 홍콩대학교가 공동으로 ByteCheckpoint를 제안했습니다. 이는 PyTorch에 기반을 둔 대규모 모델 체크포인트 시스템으로, 여러 훈련 프레임워크와 호환되며, 체크포인트의 효율적인 읽기 및 쓰기와 자동 재분할을 지원합니다. 기존 방법에 비해 성능이 크게 향상되고 사용이 간편하다는 장점이 있습니다. 이 기사에서는 대규모 모델 훈련 효율성을 향상시키기 위해 Checkpoint가 직면한 과제를 소개하고, ByteCheckpoint의 솔루션 아이디어, 시스템 설계, I/O 성능 최적화 기술, 스토리지 성능 및 읽기 성능 테스트의 실험 결과를 요약합니다.
Meta 관계자는 최근 16384 H100 80GB 훈련 클러스터에 대한 Llama3 405B 훈련의 실패율을 공개했습니다. 단 54일 만에 419번의 중단이 발생했으며 평균 3시간마다 충돌이 발생하여 많은 실무자의 관심을 끌었습니다.
업계에서 흔히 말하는 것처럼 대규모 교육 시스템의 유일한 확실성은 소프트웨어 및 하드웨어 오류입니다. 훈련 규모와 모델 크기가 증가함에 따라 소프트웨어 및 하드웨어 오류를 극복하고 훈련 효율성을 향상시키는 것이 대규모 모델 반복에 중요한 영향을 미치는 요소가 되었습니다.
체크포인트는 훈련 효율성을 높이는 열쇠가 되었습니다. Llama 훈련 보고서에서 기술팀은 높은 실패율에 대처하기 위해 훈련 과정에서 빈번한 체크포인트를 수행하여 훈련 중 모델, 옵티마이저 및 데이터 리더의 상태를 저장하여 손실을 줄여야 한다고 언급했습니다. 훈련 진행.
ByteDance Beanbao 대형 모델 팀과 홍콩 대학교는 최근 여러 훈련 프레임워크와 호환되는 PyTorch 네이티브인 ByteCheckpoint와 Checkpoint의 효율적인 읽기 및 쓰기와 자동 재실행을 지원하는 대형 모델 Checkpointing 시스템이라는 결과를 발표했습니다. 분할.
기본 방법과 비교하여 ByteCheckpoint는 체크포인트 저장 시 최대 529.22배, 로딩 시 최대 3.51배 성능을 향상시킵니다. 최소화된 사용자 인터페이스와 체크포인트 자동 재분할 기능은 사용자 획득 및 사용 비용을 크게 줄이고 시스템 사용 편의성을 향상시킵니다.

- ByteCheckpoint: LLM 개발을 위한 통합 체크포인트 시스템
- 문서 링크: https://team.doubao.com/zh/publication/bytecheckpoint-a-unified-checkpointing-system-for-llm-development?view_from =research
대형 모델 학습에서 Checkpoint 기술의 기술적 과제 현재 Checkpoint 관련 기술은 대규모 모델 학습 효율성을 지원하는 데 총 4가지 과제에 직면해 있습니다. - 기존 시스템 설계에는 결함이 있어 훈련의 추가 I/O 오버헤드가 크게 증가합니다
산업 수준의 대형 언어 모델(LLM)을 훈련하는 과정에서 훈련 상태가 체크포인트 기술을 통과해야 합니다( 저장 및 지속성을 위한 체크포인트). 일반적으로 체크포인트는 5개 부분(모델, 최적화 프로그램, 데이터 판독기, 난수 및 사용자 정의 구성)으로 구성됩니다. 이 프로세스는 종종 훈련을 몇 분 단위로 방해하여 훈련 효율성에 심각한 영향을 미칩니다. 원격 영구 스토리지 시스템을 사용하는 대규모 훈련 시나리오에서 기존 체크포인트 시스템은 체크포인트 저장 프로세스 중에 GPU에서 CPU 메모리 복사(D2H 복사), 직렬화, 로컬 저장 및 스토리지에 업로드를 완전히 활용하지 못합니다. .시스템 각 단계의 실행 독립성. 또한 체크포인트 액세스 작업을 공유하는 다양한 교육 프로세스의 병렬 처리 잠재력이 완전히 탐색되지 않았습니다. 이러한 시스템 설계 결함으로 인해 Checkpoint 교육으로 인한 추가 I/O 오버헤드가 증가합니다. - 체크포인트는 재분할이 어렵고, 수동 분할 스크립트의 개발 및 유지 관리 오버헤드가 너무 높습니다.
LLM의 다양한 교육 단계에서(SFT로 사전 교육 또는 RLHF) 및 다른 작업(훈련 작업 간에 체크포인트를 마이그레이션할 때(자동 평가를 위해 여러 단계에서 체크포인트를 가져오는 경우) 일반적으로 영구 스토리지 시스템에 저장된 체크포인트를 다시 분할(체크포인트 재샤딩)하여 새로운 병렬성에 적응해야 합니다. 사용 가능한 GPU 리소스에 대한 다운스트림 작업 및 할당량 구성. 기존 체크포인트 시스템[1, 2, 3, 4]은 모두 저장 및 로드 중에 병렬성 구성과 GPU 리소스가 변경되지 않고 유지되며 체크포인트 재분할의 필요성을 처리할 수 없다고 가정합니다. 현재 업계에서 널리 사용되는 솔루션은 다양한 모델에 대해 Checkpoint 병합 또는 재분할 스크립트를 사용자 정의하는 것입니다. 이 방법은 개발 및 유지 관리 오버헤드가 많이 발생하고 확장성이 좋지 않습니다. - 다양한 교육 프레임워크의 Checkpoint 모듈이 단편화되어 Checkpoint의 통합 관리 및 성능 최적화에 어려움을 겪습니다.
업계 교육 플랫폼에서는 엔지니어와 과학자가 자주 사용됩니다. 작업 특성에 따라 공동 작업하고, 훈련에 적합한 프레임워크(Megatron-LM [5], FSDP [6], DeepSpeed [7], veScale [8, 9])를 선택하고 체크포인트를 스토리지 시스템에 저장합니다. 그러나 이러한 다양한 교육 프레임워크에는 고유한 독립적인 체크포인트 형식과 읽기 및 쓰기 모듈이 있습니다. 다양한 훈련 프레임워크의 체크포인트 모듈 설계가 다르기 때문에 기본 시스템의 통합 체크포인트 관리 및 성능 최적화에 어려움을 겪습니다. - 분산 훈련 시스템 사용자는 여러 문제에 직면합니다
훈련 시스템 사용자(AI 연구 과학자 또는 엔지니어)의 관점에서 사용자가 분산 훈련 시스템을 사용할 때 체크포인트 방향은 는 종종 세 가지 문제로 고민합니다: 1) 체크포인트를 효율적으로 저장하는 방법과 훈련 효율성에 영향을 주지 않고 체크포인트를 저장하는 방법. 2) 한 병렬도에 저장된 체크포인트에 대한 새로운 병렬성에 따라 체크포인트를 다시 분할하고 올바르게 읽는 방법. 3) 학습된 제품을 클라우드 스토리지 시스템(HDFS, S3 등)에 업로드하고 여러 스토리지 시스템을 수동으로 관리하는 방법은 사용자가 배우고 사용하는 데 비용이 많이 듭니다. 위 문제에 대응하여 ByteDance Beanbao 모델 팀과 홍콩 대학교 Wu Chuan 교수 연구실이 공동으로 ByteCheckpoint를 출시했습니다. ByteCheckpoint는 여러 학습 프레임워크와 통합되고 여러 스토리지 백엔드를 지원하며 체크포인트를 자동으로 다시 분할하는 기능을 갖춘 고성능 분산 체크포인트 시스템입니다. ByteCheckpoint는 간단하고 사용하기 쉬운 사용자 인터페이스를 제공하고, 많은 I/O 성능 최적화 기술을 구현하여 저장 및 읽기 체크포인트 성능을 향상시키며, 다양한 병렬 구성을 사용하는 작업에서 체크포인트의 유연한 마이그레이션을 지원합니다. ByteCheckpoint는 메타데이터/텐서 데이터 분리 스토리지 아키텍처를 채택하여 체크포인트 관리 및 교육 프레임워크와 병렬 처리의 분리를 실현합니다.다양한 교육 프레임워크 및 최적화 프로그램에 있는 모델의 Tensor 슬라이스(Tensor Shard)는 저장소 파일에 저장되고, 메타 정보(TensorMeta, ShardMeta, ByteMeta)는 전역적으로 고유한 메타데이터 파일에 저장됩니다.
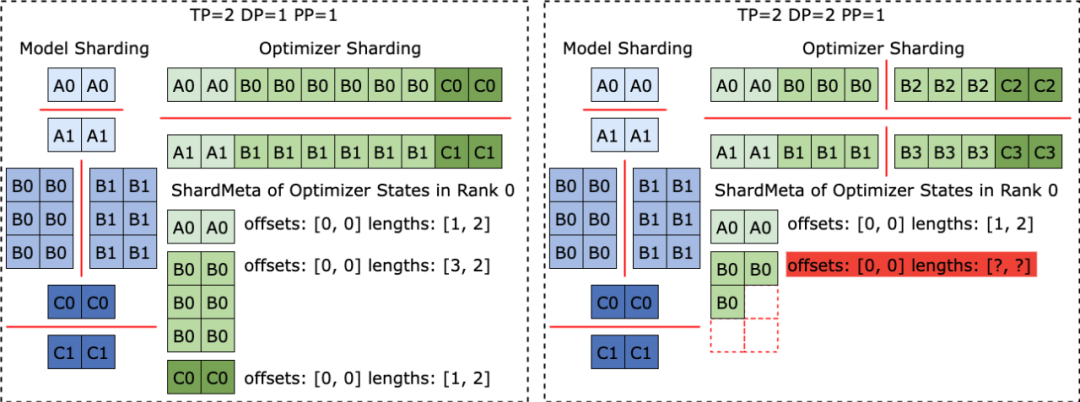
체크포인트를 읽기 위해 다양한 병렬성 구성을 사용하는 경우 아래 그림과 같이 각 교육 프로세스에서는 프로세스에 필요한 텐서의 저장 위치를 얻기 위해 현재 병렬성에 따라 쿼리 메타 정보만 설정하면 됩니다. 그런 다음 위치에 따라 직접 읽어 자동 체크포인트 재분할을 실현합니다.
다양한 훈련 프레임워크가 실행될 때 종종 모델이나 옵티마이저의 텐서 모양을 1차원으로 평면화하여 집합 통신 성능을 향상시킵니다. 이 평탄화 작업은 불규칙한 텐서 샤딩(불규칙한 텐서 샤딩) 문제를 체크포인트 스토리지에 가져옵니다. 아래 그림과 같이 Megatron-LM(NVIDIA에서 개발한 분산형 대형 모델 훈련 프레임워크)과 veScale(ByteDance에서 개발한 PyTorch 네이티브 분산형 대형 모델 훈련 프레임워크)에서 모델 매개변수는 옵티마이저 상태에 해당합니다. 하나의 차원으로 평면화하고 병합한 다음 데이터 병렬성에 따라 분할합니다. 이로 인해 텐서는 서로 다른 프로세스로 불규칙하게 분할되고, 텐서 슬라이스의 메타 정보는 오프셋 및 길이 튜플을 사용하여 표현할 수 없으므로 저장 및 읽기가 어려워집니다.
불규칙한 텐서 분할 문제는 FSDP 프레임워크에도 존재합니다. 불규칙하게 절단된 텐서 슬라이스를 제거하기 위해 FSDP 프레임워크는 체크포인트를 저장하기 전에 모든 프로세스의 1차원 텐서 슬라이스에 대해 전체 수집 세트 통신 및 D2H 복사 작업을 수행하여 완전한 불규칙 분할 텐서를 얻습니다. 이 솔루션은 대규모 통신과 빈번한 GPU-CPU 동기화 오버헤드를 가져오며 이는 Checkpoint 스토리지 성능에 심각한 영향을 미칩니다. 이 문제를 해결하기 위해 ByteCheckpoint는 Asynchronous Tensor Merging 기술을 제안했습니다. ByteCheckpoint는 먼저 여러 프로세스에서 불규칙하게 분할된 텐서를 찾은 다음 비동기 P2P 통신을 사용하여 이러한 불규칙한 텐서를 여러 프로세스에 배포하여 병합합니다. 이러한 불규칙한 텐서에 대한 모든 P2P 통신 대기(Wait) 및 텐서 D2H 복사 작업은 직렬화 단계에 진입할 때까지 연기되므로 빈번한 동기화 오버헤드가 제거되고 다른 체크포인트 스토리지 프로세스와의 통신이 중복됩니다. 다음 그림은 ByteCheckpoint의 시스템 아키텍처를 보여줍니다. API 계층은 다양한 교육 프레임워크에 대해 간단하고 사용하기 쉬운 통합 읽기 및 쓰기를 제공합니다( 저장) 및 읽기(로드) 인터페이스입니다. Planner 계층은 액세스 개체를 기반으로 다양한 교육 프로세스에 대한 액세스 계획을 생성하고 이를 실행 계층에 넘겨 실제 I/O 작업을 수행합니다. 실행 계층은 고성능 체크포인트 액세스를 위해 다양한 I/O 최적화 기술을 사용하여 I/O 작업을 수행하고 스토리지 계층과 상호 작용합니다. 스토리지 계층은 다양한 스토리지 백엔드를 관리하고 I/O 작업 중에 다양한 스토리지 백엔드에 따라 해당 최적화를 수행합니다. 계층형 디자인은 시스템의 확장성을 향상시켜 향후 더 많은 교육 프레임워크와 스토리지 백엔드를 지원할 수 있습니다.
ByteCheckpoint의 API 사용 사례는 다음과 같습니다.
ByteCheckpoint 提供了極簡 API ,降低了使用者上手的成本。當使用者在儲存和讀取 Checkpoint 時,只需要呼叫儲存和載入函數,傳入需要儲存和讀取的內容,檔案系統路徑和各種效能最佳化選項。 Checkpoint 儲存最佳化設計了全非同步的儲存管線(Save Pipeline),將Checkpoint 儲存的不同階段(P2P 張量傳輸,D2H 複製,序列化,保存本地和上傳檔案系統)進行拆分,實現高效的管線執行。 在 D2H 複製過程,ByteCheckpoint 採用固定記憶體池( Pinned Memory Pool ),減少了記憶體反覆分配的時間開銷。
除此之外,為了降低高頻儲存場景中因為同步等待固定記憶體池回收而帶來的額外時間開銷,ByteCheckpoint 在固定記憶體池的基礎上加入了 Ping-Pong buffering 的機制。兩個獨立的記憶體池交替扮演著讀寫 buffer 的角色,與 GPU 和執行後續 I/O 操作的 I/O workers 進行交互,進一步提升儲存效率。 在資料並行( Data-Parallel or DP ) 訓練中,模型在不同的資料並行進程組( DP Group )之間是餘的, ByteCheckpoint 採用了負載把冗餘的模型張量均勻分配到不同進程組中進行存儲,有效地提高了Checkpoint 儲存效率。
Checkpoint 讀取最佳化
零冗餘加載
point時需要改變元的原始進程的張量切片中讀取其中的一部分。
ByteCheckpoint 採用隨選部分檔案讀取( Partial File Reading ) 技術,直接從遠端儲存讀取所需的檔案片段,避免下載和讀取不必要的資料。
在資料並行 (Data-Parallel or DP) 訓練中,模型在不同的資料並行進程組(DP Group)之間是冗餘的,不同進程組會重複讀取同一個張量切片。在大規模訓練的場景下,不同進程組同時發給遠端持久化儲存系統 (例如 HDFS )大量請求,會對儲存系統造成巨大壓力。
為了消除重複資料讀取,減少訓練進程發給HDFS 的請求,優化載入的效能,ByteCheckpoint 把相同的張量切片讀取任務均勻分配到不同進程上,並在對遠端檔案進行讀取取的同時,利用GPU 之間閒置的頻寬進行張量切片傳輸。
實驗結果
實驗配置
模型在結構中使用不同的實驗和不同規模的訓練任務中評估了ByteCheckpoint 的Checkpoint 存取正確性、儲存效能和讀取效能。更多實驗配置和正確性測試細節請移步完整論文。
在儲存效能測試中,團隊比較了不同模型規模和訓練框架,在訓練過程中每50 或100 步存一次Checkpoint , Bytecheckpoint 和基線( Baseline )方法訓練帶來的總的阻塞時間( Checkpoint stalls )。 得益於對寫入性能的深度優化,ByteCheckpoint 在各類實驗場景中均取得了很高的表現,在576 卡SparseGPT 110B - Megatron-LM 訓練任務中相比基線存儲方法取得了66.65~74.55 倍的效能提升,在256 卡DenseGPT 10B - FSDP 訓練任務中甚至能達到529.22 倍的效能提升。
在讀取效能測試中,團隊比較不同方法根據下游任務並行度讀取 Checkpoint 的載入時間。 ByteCheckpoint 相比基線方法取得了 1.55 ~ 3.37 倍的效能提升。 團隊觀察到 ByteCheckpoint 相對於 Megatron-LM 基線方法的效能提升更為顯著。這是因為 Megatron-LM 在讀取 Checkpoint 到新的平行度配置之前,需要執行離線的腳本對分散式 Checkpoint 進行重新分片。相較之下,ByteCheckpoint 能夠直接進行自動 Checkpoint 重新切分,無需執行離線腳本,高效完成讀取。
最後,關於 ByteCheckpoint 的未來規劃,團隊希望從兩個方面著手:其一,實現支援超大規模 GPU 叢集訓練任務高效 Checkpointing 的長遠目標。 其二,實現大模型訓練全生命週期的Checkpoint 管理,支援全場景的Checkpoint ,從預訓練(Pre-Training),到監督微調( SFT ),再到強化學習( RLHF )和評估(Evaluation) 等場景。 字節跳動豆包大模型團隊成立於2023 年,致力於開發業界最先進的AI 大模型技術,成為世界一流的社會研究團隊,為科技和社會發展作出貢獻。 目前,團隊正在持續吸引優秀人才加入,硬核、開放且充滿創新精神是團隊氛圍關鍵字,團隊致力於創造一個積極向上的工作環境,鼓勵團隊成員不斷學習和成長,不畏挑戰,追求卓越。 希望與具備創新精神、責任感的技術人才一起,推進大模型訓練提效工作取得更多進展和成果。 [1] Mohan, Jayashree, Amar Phanishayee, and Vijay Chidambapoint. "{CheckFreq}: Frequent; on File and Storage Technologies (FAST 21). 2021.[2] Eisenman, Assaf, et al. "{Check-N-Run}: A Checkpointing system for training deep learning remendmendmend 9 Symposium on Networked Systems Design and Implementation (NSDI 22). 2022.[3] Wang, Zhuang, et al. "Gemini: Fast failure recovery in 分散式training with inmemory Checkingss. 29th Symposium on Operating Systems Principles. 2023.[4] Gupta, Tanmaey, et al. "Just-In-Time Checkpointing: Low Cost Error Recovery from Deep Learning Training Failings. on Computer Systems. 2024.[5] Shoeybi, Mohammad, et al. "Megatron-lm: Training multi-billion parameter language models using model paring multi-billion parameter language models using model parallel/iv.FarX [6] Zhao, Yanli, et al. "Pytorch fsdp: experiences on scaling fully sharded data parallel." arXiv preprint arXiv:2304.11277, Ras et al. "Deepspeed: System optimizations enable training deep learning models with over 100 billion parameters." Proceedings of the 26th ACM SIGKDD International Conference on Knowihy & Data Mining. 2020.03,80. al. "{MegaScale}: Scaling large language model training to more than 10,000 {GPUs}." 21st USENIX Symposium on Networked Systems Design and Implementation (NSDI 24). 2024. Native LLM ): 1877-1901.위 내용은 Llama3 훈련이 3시간마다 충돌하나요? 빅빈백 모델과 HKU 팀이 바삭바삭한 완카 트레이닝을 향상시킵니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!