지난해 12월, 새로운 아키텍처인 Mamba 가 AI 서클을 폭파하고 부동의 트랜스포머에 대한 도전을 시작했습니다. 오늘날 Google DeepMind “Hawk” 및 “Griffin”의 출시는 AI 서클에 새로운 옵션을 제공합니다.
이번에 구글 딥마인드는 기본 모델에서 새로운 행보를 보였습니다. 우리는 순환 신경망(RNN)이 딥 러닝 및 자연어 처리 연구 초기에 중심 역할을 했으며 Google 최초의 엔드투엔드 기계 번역 시스템을 비롯한 많은 애플리케이션에서 실질적인 결과를 달성했다는 것을 알고 있습니다. . 그러나 최근에는 MLP(Multi-Layer Perceptron)와 MHA(Multi-Head Attention)를 결합한 Transformer 아키텍처가 딥러닝과 NLP를 주도하고 있습니다. Transformer는 실제로 RNN보다 더 나은 성능을 달성했으며 최신 하드웨어를 활용하는 데에도 매우 효율적입니다. Transformer 기반 대규모 언어 모델은 웹에서 수집된 대규모 데이터 세트를 통해 놀라운 성공을 거두었습니다. 큰 성공을 거두었음에도 불구하고 Transformer 아키텍처에는 여전히 단점이 있습니다. 예를 들어, 전 세계적으로 주목받는 2차 복잡성으로 인해 Transformer는 긴 시퀀스로 효과적으로 확장하기가 어렵습니다. 또한 KV(키-값) 캐시는 시퀀스 길이에 따라 선형적으로 증가하므로 추론 중에 Transformer의 속도가 느려집니다. 이 시점에서 순환 언어 모델은 대안이 되며 전체 시퀀스를 고정된 크기의 숨겨진 상태로 압축하고 반복적으로 업데이트할 수 있습니다. 그러나 Transformer를 대체하려면 새로운 RNN 모델이 확장성 측면에서 비슷한 성능을 보여줄 뿐만 아니라 비슷한 하드웨어 효율성도 달성해야 합니다. Google DeepMind의 최근 논문에서 연구원들은 새로운 게이트 선형 루프 계층인 RG-LRU 계층을 제안하고 MQA(Multi-Query Attention)를 대체하기 위해 그 주위에 새로운 루프 블록을 설계했습니다. 이 루프 블록을 사용하여 두 가지 새로운 모델을 만들었습니다. 하나는 MLP와 루프 블록을 혼합한 모델 Hawk이고, 다른 하나는 MLP와 루프 블록 및 로컬 관심을 혼합한 모델 Griffin입니다. 
- 논문 제목: Griffin: Mixing Gated Linear Recurrences with Local Attention for Efficient Language Models
- 논문 링크: https://arxiv.org/pdf/2402.19427.pdf
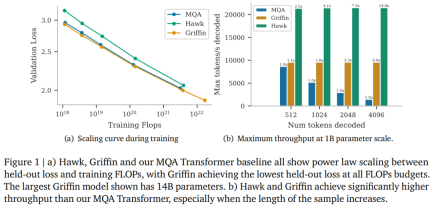
연구원들은 Hawk와 Griffin이 이전에 Transformers에서 관찰된 것처럼 유지 손실과 훈련 FLOP 사이의 최대 7B 매개변수 사이의 거듭제곱 법칙을 보여준다고 말합니다. 그중 Griffin은 모든 모델 크기에서 강력한 Transformer 기준선보다 약간 더 낮은 유지 손실을 달성합니다.
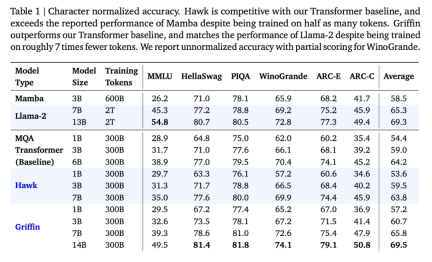
연구원들은 다양한 모델 크기에 대해 300B 토큰에 대해 Hawk와 Griffin을 과도하게 훈련시켰습니다. 결과는 훈련된 토큰의 수가 절반에 불과했지만 다운스트림 작업 성능에서 Hawk-3B가 Mamba-3B를 능가한 것으로 나타났습니다. 후자. Griffin-7B와 Griffin-14B는 토큰 수의 1/7만 사용하여 훈련했음에도 불구하고 Llama-2와 비슷한 성능을 발휘합니다.
또한 Hawk와 Griffin은 TPU-v3에서 Transformers와 비슷한 훈련 효율성을 달성했습니다. 대각선 RNN 레이어는 메모리가 제한되어 있으므로 연구원들은 이를 달성하기 위해 RG-LRU 레이어의 커널을 사용했습니다.
또한 추론 중에 Hawk와 Griffin은 모두 MQA Transformer보다 더 높은 처리량을 달성하고 긴 시퀀스를 샘플링할 때 더 낮은 대기 시간을 달성합니다. Griffin은 평가되는 시퀀스가 훈련에서 관찰된 것보다 길 때 Transformers보다 더 나은 성능을 발휘하며 훈련 데이터에서 복사 및 검색 작업을 효과적으로 학습할 수 있습니다. 그러나 사전 훈련된 모델을 미세 조정 없이 복사 및 정확한 검색 작업에서 평가했을 때 Hawk와 Griffin은 Transformers보다 성능이 나빴습니다.
공저자이자 DeepMind 연구 과학자인 Aleksandar Botev는 Gated Linear Loop와 Local Attention을 혼합한 모델인 Griffin이 RNN의 고효율 장점과 Transformer의 표현 능력을 모두 유지하며 확장이 가능하다고 말했습니다. 14B 매개변수 규모.
출처: https://twitter.com/botev_mg/status/1763489 634082795780Griffin Semua model mengandungi komponen berikut: (i) blok baki, (ii) blok MLP, (iii) blok campuran temporal. (i) dan (ii) adalah sama untuk semua model, tetapi terdapat tiga blok pencampuran temporal: perhatian berbilang pertanyaan global (MQA), tempatan (tetingkap gelongsor) MQA dan blok berulang yang dicadangkan dalam kertas ini. Sebagai sebahagian daripada blok berulang, penyelidik menggunakan Unit Berulang Linear Really Gated (RG-LRU), lapisan berulang baharu yang diilhamkan oleh unit berulang linear. Seperti yang ditunjukkan dalam Rajah 2(a), blok sisa mentakrifkan struktur global model Griffin, yang diilhamkan oleh pra-normTransformer. Selepas membenamkan jujukan input, kami meneruskannya melalui blok seperti ? (? mewakili kedalaman model) dan kemudian menggunakan RMSNorm untuk menjana pengaktifan akhir. Untuk mengira kebarangkalian token, lapisan linear akhir digunakan, diikuti dengan softmax. Berat lapisan ini dikongsi dengan lapisan pembenaman input.
Model berulang, kecekapan penskalaan setanding dengan Transformer Penyelidikan penskalaan memberikan pandangan penting tentang cara melaraskan hiperparameter model dan kelakuannya semasa menskala. Para penyelidik mentakrifkan model yang dinilai dalam kajian ini, menyediakan lengkung penskalaan sehingga dan melebihi parameter 7B, dan menilai prestasi model pada tugas hiliran. Mereka menganggap 3 keluarga model: (1) Garis dasar MQA-Transformer; (2) Hawk: model RNN tulen; (3) Griffin: model hibrid yang mencampurkan blok berulang dengan perhatian tempatan. Hiperparameter model utama untuk model pelbagai saiz ditakrifkan dalam Lampiran C. Seni bina Hawk menggunakan corak sisa dan blok MLP yang sama seperti garis dasar Transformer, tetapi penyelidik menggunakan blok berulang dengan lapisan RG-LRU sebagai blok campuran temporal dan bukannya MQA. Mereka mengembangkan lebar blok gelung dengan faktor kira-kira 4/3 (iaitu, ?_??? ≈4?/3) untuk memadankan secara kasar bilangan parameter blok MHA apabila kedua-duanya menggunakan dimensi model yang sama ?. Griffin. Kelebihan utama blok berulang berbanding perhatian global ialah ia menggunakan saiz keadaan tetap untuk meringkaskan jujukan, manakala saiz cache KV MQA berkembang secara berkadar dengan panjang jujukan. Perhatian tempatan mempunyai sifat yang sama, dan mencampurkan blok berulang dengan perhatian tempatan mengekalkan kelebihan ini. Para penyelidik mendapati gabungan ini sangat cekap kerana perhatian tempatan boleh memodelkan masa lalu dengan tepat, manakala lapisan berulang boleh menyampaikan maklumat dalam urutan yang panjang. Griffin menggunakan corak sisa dan blok MLP yang sama seperti garis dasar Transformer. Tetapi tidak seperti garis dasar Transformer MQA dan model Hawk, Griffin menggunakan gabungan blok gelung dan blok MQA. Khususnya, kami menggunakan struktur hierarki yang menggantikan dua blok baki dengan blok berulang dan kemudian blok perhatian setempat (MQA). Melainkan dinyatakan sebaliknya, saiz tetingkap perhatian tempatan ditetapkan pada 1024 token. Hasil penskalaan utama ditunjukkan dalam Rajah 1(a). Ketiga-tiga keluarga model telah dilatih pada saiz model antara 100 juta hingga 7 bilion parameter, walaupun Griffin mempunyai versi 14 bilion parameter. Keputusan penilaian pada tugasan hiliran ditunjukkan dalam Jadual 1:
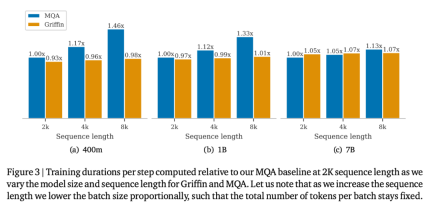
Hawk dan Griffin kedua-duanya bermain dengan sangat baik. Jadual di atas melaporkan ketepatan dinormalisasi ciri untuk MMLU, HellaSwag, PIQA, ARC-E dan ARC-C, sambil melaporkan ketepatan mutlak dan skor separa untuk WinoGrande. Apabila saiz model bertambah, prestasi Hawk juga meningkat dengan ketara, dan Hawk-3B berprestasi lebih baik daripada Mamba-3B dalam tugas hiliran, walaupun bilangan token yang dilatihnya hanya separuh daripada Mamba-3B. Prestasi Griffin-3B jauh lebih baik daripada Mamba-3B, dan Griffin-7B dan Griffin-14B berprestasi setanding dengan Llama-2, walaupun mereka dilatih menggunakan token hampir 7x lebih sedikit. Hawk adalah setanding dengan garis dasar Transformer MQA, manakala Griffin mengatasinya. Melatih model gelung pada sisi peranti dengan cekapApabila membangunkan dan memanjangkan model, penyelidik menghadapi dua cabaran kejuruteraan utama. Pertama, cara mengecilkan model pemprosesan serpihan merentas berbilang peranti. Kedua, bagaimana untuk melaksanakan gelung linear dengan berkesan untuk memaksimumkan kecekapan latihan TPU. Artikel ini membincangkan kedua-dua cabaran ini dan kemudian memberikan perbandingan empirikal kelajuan latihan garis dasar Griffin dan MQA. Para penyelidik membandingkan kelajuan latihan saiz model yang berbeza dan panjang jujukan untuk mengkaji kelebihan pengiraan model dalam artikel ini semasa proses latihan. Jumlah bilangan token setiap kelompok dikekalkan tetap untuk setiap saiz model, yang bermaksud bahawa apabila panjang jujukan bertambah, bilangan jujukan berkurangan secara berkadar. Rajah 3 memplot masa berjalan relatif model Griffin berbanding model garis dasar MQA pada panjang jujukan 2048.
Inferens LLM terdiri daripada dua peringkat. Fasa "praisi" adalah untuk menerima dan memproses gesaan. Langkah ini sebenarnya melakukan hantaran ke hadapan pada model. Memandangkan gesaan boleh diproses secara selari sepanjang jujukan, kebanyakan operasi model pada peringkat ini terikat secara pengiraan Oleh itu, kami menjangkakan kelajuan relatif Transformer dan model gelung dalam peringkat pra-populasi adalah sama seperti yang dibincangkan sebelum ini semasa latihan adalah serupa. Selepas pra-populasi ialah peringkat penyahkodan, di mana penyelidik secara autoregresif mengekstrak token daripada model. Seperti yang ditunjukkan di bawah, terutamanya untuk panjang jujukan yang lebih panjang, di mana cache nilai kunci (KV) yang digunakan dalam perhatian menjadi besar, model berulang mempunyai kependaman yang lebih rendah dan daya pemprosesan yang lebih tinggi dalam peringkat penyahkodan. Terdapat dua metrik utama untuk dipertimbangkan semasa menilai kelajuan inferens. Yang pertama ialah kependaman, yang mengukur masa yang diperlukan untuk menjana bilangan token tertentu pada saiz kelompok tertentu. Yang kedua ialah throughput, yang mengukur bilangan maksimum token yang boleh dijana sesaat apabila mensampel bilangan token yang ditentukan pada satu peranti. Oleh kerana daya pemprosesan dikira sebagai bilangan token yang disampel didarab dengan saiz kelompok dibahagikan dengan kependaman, anda boleh meningkatkan daya pemprosesan dengan mengurangkan kependaman atau mengurangkan penggunaan memori untuk menggunakan saiz kelompok yang lebih besar pada peranti. Mengambil kira kependaman berguna untuk aplikasi masa nyata yang memerlukan masa tindak balas yang cepat. Throughput juga patut dipertimbangkan kerana ia memberitahu kami bilangan maksimum token yang boleh diambil sampel daripada model tertentu dalam masa tertentu. Sifat ini menarik apabila mempertimbangkan aplikasi bahasa lain, seperti pembelajaran pengukuhan berdasarkan maklum balas manusia (RLHF) atau output model bahasa pemarkahan (seperti yang dilakukan dalam AlphaCode), kerana dapat mengeluarkan sejumlah besar token dalam masa tertentu adalah Satu yang menarik. ciri. Di sini, penyelidik mengkaji keputusan inferens model dengan parameter 1B. Dari segi garis dasar, ia dibandingkan dengan Transformer MQA, yang jauh lebih pantas semasa inferens daripada Transformer MHA standard yang biasa digunakan dalam literatur. Model yang dibandingkan oleh penyelidik ialah: i) penukar MQA, ii) Hawk dan iii) Griffin. Untuk membandingkan model yang berbeza, kami melaporkan kependaman dan daya pemprosesan. Seperti yang ditunjukkan dalam Rajah 4, penyelidik membandingkan kependaman model dengan saiz kelompok 16, pra-isi kosong dan pra-isi 4096 token.
Rajah 1(b) membandingkan daya pemprosesan maksimum (token/saat) bagi model yang sama apabila masing-masing mengambil sampel 512, 1024, 2048 dan 4196 token selepas pembayang kosong. . Prestasi Griffin pada tugas yang memerlukan kebolehan menyalin dan mendapatkan semula juga diterokai, kedua-duanya dalam model yang dilatih untuk tugasan tersebut dan apabila kebolehan ini diuji menggunakan model bahasa yang telah dilatih. Daripada graf di sebelah kiri Rajah 5, boleh diperhatikan bahawa dalam julat panjang maksimum tertentu, kedua-dua Hawk dan Griffin boleh meningkatkan keupayaan ramalan token seterusnya dalam konteks yang lebih panjang, dan mereka secara keseluruhannya Mampu untuk membuat kesimpulan urutan yang lebih panjang (sekurang-kurangnya 4 kali) daripada semasa dilatih. Griffin, khususnya, menunjukkan prestasi yang sangat baik dalam penaakulan walaupun semasa menggunakan RoPE dalam lapisan perhatian setempat.
Seperti yang ditunjukkan dalam Rajah 6, dalam tugasan penyalinan terpilih, kesemua 3 model dapat menyelesaikan tugasan dengan sempurna. Apabila membandingkan kelajuan pembelajaran pada tugasan ini, Hawk adalah lebih perlahan daripada Transformer, yang serupa dengan pemerhatian Jelassi et al (2024) yang mendapati bahawa Mamba belajar dengan ketara lebih perlahan pada tugasan yang serupa. Menariknya, walaupun Griffin hanya menggunakan lapisan perhatian tempatan, kelajuan pembelajarannya hampir tidak diperlahankan dan setanding dengan kelajuan pembelajaran Transformer.
Untuk butiran lanjut, sila baca kertas asal. 위 내용은 RNN 효율성은 Transformer와 비슷합니다. Google의 새로운 아키텍처는 두 번 연속 출시되었습니다. 동일한 규모에서 Mamba보다 강력합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!




 출처: https://twitter.com/botev_mg/status/1763489 634082795780
출처: https://twitter.com/botev_mg/status/1763489 634082795780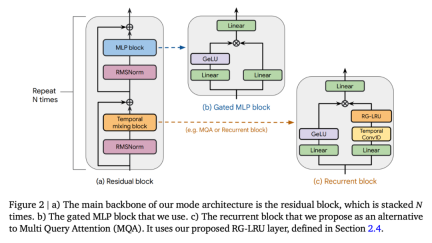


 Let 's Dance : 인간 신경 그물을 미세 조정하기위한 구조화 된 움직임Apr 27, 2025 am 11:09 AM
Let 's Dance : 인간 신경 그물을 미세 조정하기위한 구조화 된 움직임Apr 27, 2025 am 11:09 AM 새로운 Google 유출은 Gemini AI의 구독 변경을 보여줍니다Apr 27, 2025 am 11:08 AM
새로운 Google 유출은 Gemini AI의 구독 변경을 보여줍니다Apr 27, 2025 am 11:08 AM 데이터 분석 가속이 AI의 숨겨진 병목 현상을 해결하는 방법Apr 27, 2025 am 11:07 AM
데이터 분석 가속이 AI의 숨겨진 병목 현상을 해결하는 방법Apr 27, 2025 am 11:07 AM Markitdown MCP는 모든 문서를 Markdowns로 변환 할 수 있습니다!Apr 27, 2025 am 09:47 AM
Markitdown MCP는 모든 문서를 Markdowns로 변환 할 수 있습니다!Apr 27, 2025 am 09:47 AM 빌딩 에이전트에 Google ADK를 사용하는 방법은 무엇입니까? - 분석 VidhyaApr 27, 2025 am 09:42 AM
빌딩 에이전트에 Google ADK를 사용하는 방법은 무엇입니까? - 분석 VidhyaApr 27, 2025 am 09:42 AM 효과적인 문제 해결을 위해 LLM을 통해 SLM 사용 - 분석 VidhyaApr 27, 2025 am 09:27 AM
효과적인 문제 해결을 위해 LLM을 통해 SLM 사용 - 분석 VidhyaApr 27, 2025 am 09:27 AM 컴퓨터 비전 작업에 Google Gemini 모델을 사용하는 방법은 무엇입니까? - 분석 VidhyaApr 27, 2025 am 09:26 AM
컴퓨터 비전 작업에 Google Gemini 모델을 사용하는 방법은 무엇입니까? - 분석 VidhyaApr 27, 2025 am 09:26 AM Gemini 2.0 Flash vs O4-Mini : Google은 OpenAi보다 더 잘할 수 있습니까?Apr 27, 2025 am 09:20 AM
Gemini 2.0 Flash vs O4-Mini : Google은 OpenAi보다 더 잘할 수 있습니까?Apr 27, 2025 am 09:20 AM













