
대형 모델에 대한 새로운 과학적이고 복잡한 질문 답변 벤치마크 및 평가 시스템을 제공하기 위해 UNSW, Argonne, University of Chicago 및 기타 기관이 공동으로 SciQAG 프레임워크를 출시했습니다.

- 王林원래의
- 2024-07-25 06:42:231593검색

Editor | ScienceAI
QA(질문 및 답변) 데이터 세트는 자연어 처리(NLP) 연구를 촉진하는 데 중요한 역할을 합니다. 고품질 QA 데이터 세트는 모델을 미세 조정하는 데 사용될 수 있을 뿐만 아니라 LLM(대형 언어 모델)의 기능, 특히 과학적 지식을 이해하고 추론하는 능력을 효과적으로 평가하는 데에도 사용할 수 있습니다.
현재 의학, 화학, 생물학 및 기타 분야를 포괄하는 과학적인 QA 데이터 세트가 많지만 이러한 데이터 세트에는 여전히 몇 가지 단점이 있습니다.
첫째, 데이터 형식이 비교적 단순하고 대부분이 객관식 질문이므로 평가하기 쉽지만 모델의 답변 선택 범위가 제한되고 모델의 과학적 질문 답변 능력을 완전히 테스트할 수 없습니다. 이와 대조적으로 공개 질문 답변(openQA)은 모델의 기능을 보다 포괄적으로 평가할 수 있지만 적절한 평가 지표가 부족합니다.
둘째, 기존 데이터 세트의 내용 중 상당수가 대학 수준 이하의 교과서에서 나온 것이므로 실제 학술 연구나 생산 환경에서 LLM의 높은 수준의 지식 보유 능력을 평가하기 어렵습니다.
셋째, 이러한 벤치마크 데이터 세트의 생성은 인간 전문가의 주석에 의존합니다.
이러한 과제를 해결하는 것은 보다 포괄적인 QA 데이터 세트를 구축하는 데 중요하며 과학 LLM을 보다 정확하게 평가하는 데도 도움이 됩니다.
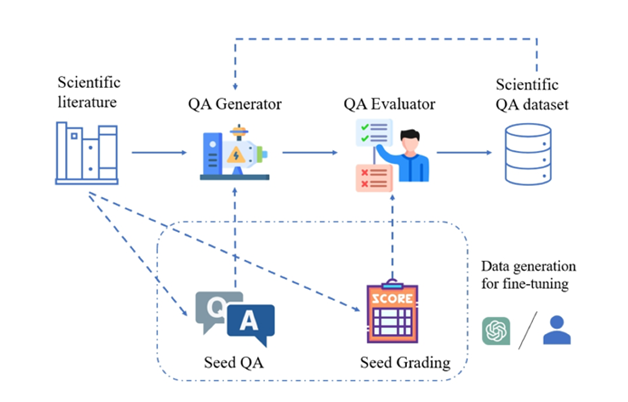
Illustration: 과학 문헌에서 고품질의 과학 질문 및 답변 쌍을 생성하기 위한 SciQAG 프레임워크.
이를 위해 미국 아르곤 국립연구소와 시카고대학교 Ian Foster 교수팀(2002년 고든 벨상 수상자), 뉴사우스웨일스대학교 Bram Hoex 교수의 UNSW AI4Science팀, 호주, AI4Science 회사 GreenDynamics 및 홍콩 시립대학교 Jie Chunyu 교수팀이 대규모 언어 모델을 기반으로 대규모 과학 문헌 자료에서 고품질 과학 공개 질문 및 답변 쌍을 자동으로 생성하는 최초의 새로운 프레임워크인 SciQAG를 공동으로 제안했습니다. (LLM).

논문 링크:https://arxiv.org/abs/2405.09939
github 링크:https://github.com/MasterAI-EAM/SciQAG
연구원들은 SciQAG를 기반으로 구축했습니다. 대규모의 고품질 개방형 과학 QA 데이터 세트인 SciQAG-24D에는 24개 과학 분야의 22,743개 과학 논문에서 추출된 188,042개의 QA 쌍이 포함되어 있으며 LLM의 미세 조정 및 과학적 문제 평가를 제공하도록 설계되었습니다. 해결능력.
실험을 통해 SciQAG-24D 데이터 세트에서 LLM을 미세 조정하면 개방형 질문 답변 및 과학 작업의 성능이 크게 향상될 수 있음이 입증되었습니다.
AI for Science 커뮤니티의 공개 과학 Q&A 공동 개발을 촉진하기 위해 데이터 세트, 모델 및 평가 코드가 오픈 소스로 제공되었습니다(https://github.com/MasterAI-EAM/SciQAG).
SciQAG-24D 벤치마크 데이터세트가 포함된 SciQAG 프레임워크
SciQAG는 QA 생성기와 QA 평가자로 구성되어 있으며, 대규모 과학 문헌을 기반으로 다양한 공개 질문과 답변 쌍을 신속하게 생성하는 것을 목표로 합니다. 먼저 생성기는 과학 논문을 질문 및 답변 쌍으로 변환한 후 평가자는 품질 기준에 맞지 않는 질문 및 답변 쌍을 필터링하여 고품질의 과학 질문 및 답변 데이터 세트를 얻습니다.
QA Generator
연구원들은 비교 실험을 통해 2단계 프롬프트(프롬프트)를 설계하여 LLM이 먼저 키워드를 추출한 다음 키워드를 기반으로 질문과 답변 쌍을 생성할 수 있도록 했습니다.
생성된 질문과 답변 데이터 세트는 "비공개 도서" 모드를 채택하므로 원본 논문은 제공되지 않으며 추출된 과학 지식 자체에만 초점을 맞추고 있습니다. 프롬프트에서는 생성된 질문과 답변 쌍이 의존하지 않아야 합니다. 원본 논문의 고유 정보를 언급하거나 "이/이 논문", "이/이 연구" 등과 같은 현대 명명법은 허용되지 않습니다. 또는 원본 논문의 표/그림에 대해 질문합니다. 기사).
성능과 비용의 균형을 맞추기 위해 연구원들은 오픈 소스 LLM을 생성기로 미세 조정하기로 결정했습니다. SciQAG 사용자는 미세 조정이나 신속한 단어 엔지니어링을 사용하여 자신의 상황에 따라 오픈 소스 또는 폐쇄 소스 LLM을 생성기로 선택할 수 있습니다.
QA 평가자
평가자는 두 가지 목적을 달성하는 데 사용됩니다. (1) 생성된 질문 및 답변 쌍의 품질을 평가합니다. (2) 설정된 기준에 따라 품질이 낮은 질문 및 답변 쌍을 삭제합니다.
연구원들은 관련성, 불가지론, 완전성, 정확성, 합리성의 5가지 차원으로 구성된 종합 평가 지표 RACAR을 개발했습니다.
이 연구에서 연구원들은 GPT-4를 QA 평가자로 직접 사용하여 RACAR에 따라 생성된 QA 쌍을 평가했으며 평가 수준은 1~5입니다(1은 허용되지 않음, 5는 완전히 허용됨을 의미).
그림에 표시된 것처럼 GPT-4와 수동 평가 간의 일관성을 측정하기 위해 두 명의 도메인 전문가가 RACAR 측정항목을 사용하여 10개 기사(총 100개의 질문 및 답변 쌍)에 대해 수동 평가를 수행했습니다. 사용자는 필요에 따라 오픈 소스 또는 폐쇄 소스 LLM을 평가자로 선택할 수 있습니다.
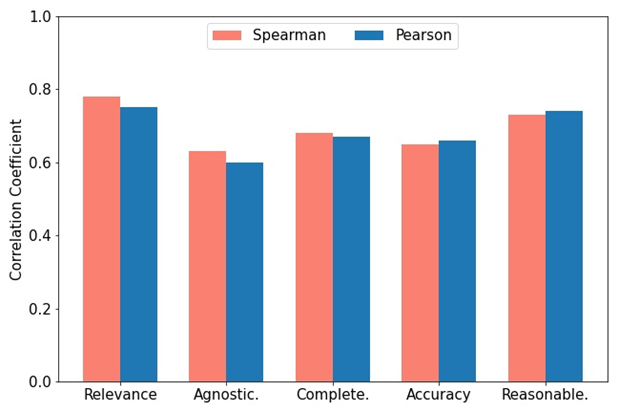
그림: GPT-4 할당 점수와 전문가 주석 점수 간의 Spearman 및 Pearson 상관관계.
SciQAG 프레임워크 적용
이 연구는 재료 과학, 화학, 물리학, 에너지 등 분야의 WoS(Web of Science) 핵심 컬렉션 데이터베이스에서 24개 범주에 걸쳐 총 22,743개의 높은 인용 논문을 확보했습니다. , 신뢰할 수 있고 풍부하며 균형 잡힌 대표적인 과학 지식 소스를 구축하는 것을 목표로 합니다.
오픈 소스 LLM을 미세 조정하여 QA 생성기를 형성하기 위해 연구원들은 논문 컬렉션에서 426개의 논문을 입력으로 무작위로 선택하고 GPT-4를 요청하여 4260개의 시드 QA 쌍을 생성했습니다.
훈련된 QA 생성기를 사용하여 나머지 논문에 대한 추론을 수행하여 총 227,430개의 QA 쌍(시드 QA 쌍 포함)이 생성되었습니다. 각 카테고리에서 50개의 논문(총 1,200개 논문)을 추출하고, 생성된 각 QA 쌍의 RACAR 점수를 계산하기 위해 GPT-4를 사용했으며, 차원 점수가 3보다 낮은 QA 쌍을 테스트 세트로 필터링했습니다.
나머지 QA 쌍에 대해서는 규칙 기반 방법을 사용하여 논문의 고유 정보가 포함된 모든 질문 및 답변 쌍을 필터링하여 훈련 세트를 구성합니다.
SciQAG-24D 벤치마크 데이터 세트
위를 기반으로 연구원들은 공개 과학 QA 벤치마크 데이터 세트 SciQAG-24D를 구축했습니다. 필터링된 훈련 세트에는 21,529개의 논문과 179,511개의 QA 쌍이 포함되어 있으며, 필터링된 테스트 세트에는 다음이 포함됩니다. 1,199편의 논문과 8,531개의 QA 쌍.
통계에 따르면 답변에 포함된 데이터의 99.15%가 원본 논문에서 나온 것이고, 질문의 87.29%가 0.3 미만의 유사성을 가지며, 답변이 원본 내용의 78.26%를 차지하는 것으로 나타났습니다.
이 데이터 세트는 널리 사용됩니다. 훈련 세트는 LLM을 미세 조정하고 여기에 과학적 지식을 주입하는 데 사용할 수 있습니다. 테스트 세트는 특정 또는 전체 과학 분야의 공개 QA 작업에 대한 LLM의 성능을 평가하는 데 사용할 수 있습니다. . 테스트 세트의 규모가 크기 때문에 미세 조정을 위한 고품질 데이터로도 사용할 수 있습니다.
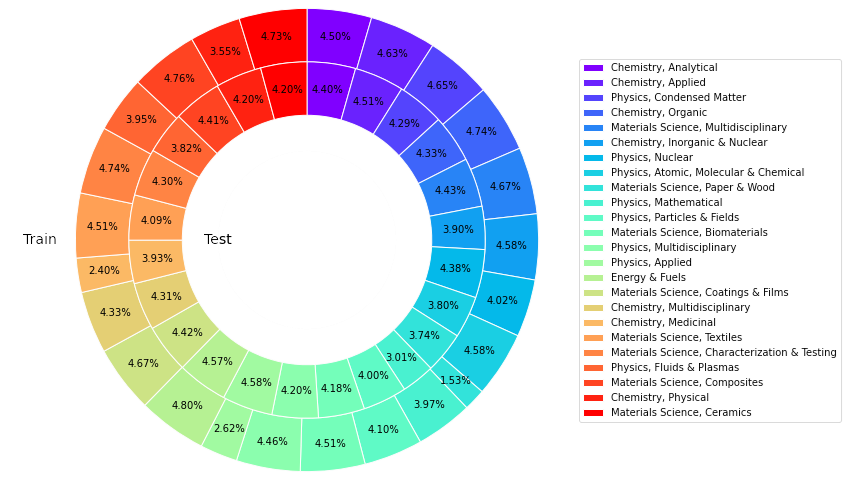
그림: SciQAG-24D 데이터세트의 훈련 및 테스트에서 다양한 카테고리의 기사 비율.
실험 결과
연구원들은 다양한 언어 모델 간 과학적 질문 답변의 성능 차이를 비교하고 미세 조정의 영향을 탐색하기 위해 포괄적인 실험을 수행했습니다.
제로샷 설정
연구원들은 SciQAG-24D의 테스트 세트 중 일부를 사용하여 5개 모델의 제로샷 성능을 비교했습니다. 그 중 두 개는 오픈 소스 LLM인 LLaMA1(7B) 및 LLaMA2-chat(7B)이고 나머지는 폐쇄 소스 LLM입니다.
API를 통한 호출: GPT3.5(gpt-3.5-turbo), GPT-4(gpt-4-1106-preview) 및 Claude 3(claude-3-opus-20240229). 각 모델에는 테스트에서 1,000개의 질문이 제시되었으며, 그 출력은 CAR 측정항목(RACAR 측정항목에서 채택되었으며 응답 평가에만 초점을 맞췄음)으로 평가되어 과학적 연구 질문에 답하는 제로샷 능력을 측정했습니다.
그림에서 볼 수 있듯이 전체 모델 중 GPT-4가 완성도(4.90)와 타당성(4.99)에서 가장 높은 점수를 받은 반면, Claude 3는 정확도(4.95)에서 가장 높은 점수를 받았습니다. GPT-3.5는 또한 모든 지표에서 GPT-4와 Claude 3에 바짝 뒤처지는 등 매우 좋은 성능을 발휘합니다.
특히 LLaMA1은 세 가지 차원 모두에서 가장 낮은 점수를 받았습니다. 대조적으로 LLaMA2 채팅 모델은 GPT 모델만큼 높은 점수를 얻지는 못하지만 모든 지표에서 원래 LLaMA1에 비해 크게 향상되었습니다. 결과는 과학적 질문에 답하는 데 있어 상업용 LLM의 뛰어난 성능을 보여주며, 오픈 소스 모델(예: LLaMA2-chat)도 이와 관련하여 상당한 진전을 이루었습니다.
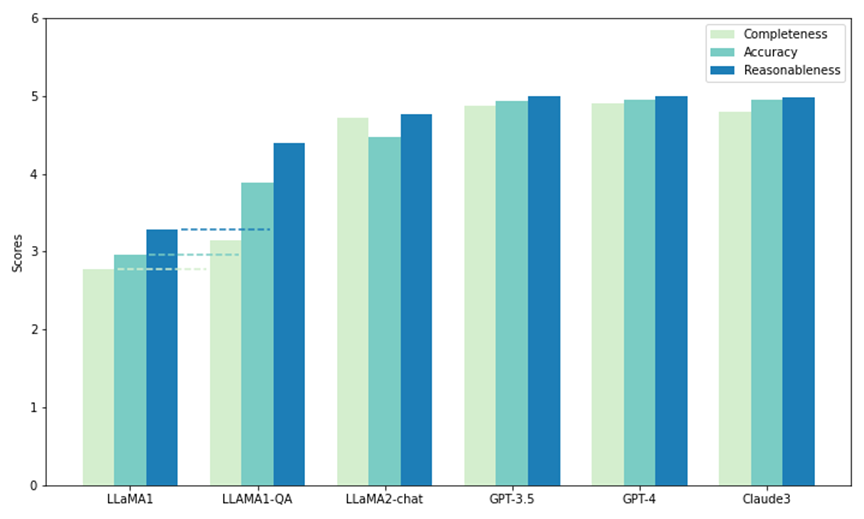
그림: SciQAG-24D의 제로 샘플 테스트 및 미세 조정 테스트(LLAMA1-QA)
미세 조정 설정(fine-tuning set)
연구원들은 최악의 제로- 샘플 성능 LLaMA1-QA를 얻기 위해 SciQAG-24D의 훈련 세트에 대해 미세 조정이 수행됩니다. 세 가지 실험을 통해 연구원들은 SciQAG-24D가 다운스트림 과학 작업의 성능을 향상시키기 위한 효과적인 미세 조정 데이터로 사용될 수 있음을 입증했습니다.
(a) 보이지 않는 SciQAG-24D 테스트 세트의 LLaMA-QA 대 원본 LLaMA1 성능 비교.
위 그림에서 볼 수 있듯이 LLaMA1-QA의 성능은 기존 LLaMA1에 비해 대폭 향상되었습니다(완성도 13% 증가, 정확도 및 타당성 30% 이상 증가). 이는 LLaMA1이 SciQAG-24D의 훈련 데이터로부터 과학적 질문에 답하는 논리를 학습했으며 일부 과학적 지식을 내면화했음을 보여줍니다.
(b) 과학적 MCQ 벤치마크인 SciQ의 미세 조정 성능 비교.
아래 표의 첫 번째 행은 LLaMA1-QA가 LLaMA1(+1%)보다 약간 더 우수함을 보여줍니다. 관찰에 따르면 미세 조정은 모델의 명령 추종 능력도 향상시켰습니다. 즉, 구문 분석할 수 없는 출력의 확률이 LLaMA1의 4.1%에서 LLaMA1-QA의 1.7%로 떨어졌습니다.
(c) 다양한 과학 작업에 대한 미세 조정 성능 비교.
평가 지표의 경우 분류 작업에는 F1-score, 회귀 작업에는 MAE, 변환 작업에는 KL divergence가 사용됩니다. 아래 표에서 볼 수 있듯이 LLaMA1-QA는 과학 작업에서 LLaMA1 모델에 비해 크게 개선되었습니다.
가장 눈에 띄는 개선 사항은 회귀 작업에 반영되어 MAE가 463.96에서 185.32로 떨어졌습니다. 이러한 결과는 훈련 중에 QA 쌍을 통합하면 과학적 지식을 학습하고 적용하는 모델의 능력을 향상시켜 다운스트림 예측 작업의 성능을 향상시킬 수 있음을 시사합니다.
놀랍게도 LLM은 기능을 갖춘 특별히 설계된 기계 학습 모델과 비교할 때 일부 작업에서는 그에 필적하거나 심지어 능가하는 결과를 얻을 수 있습니다. 예를 들어 밴드 갭 작업에서는 LLaMA1-QA가 MODNet(0.3327)과 같은 모델만큼 성능이 좋지는 않지만 AMMExpress v2020(0.4161)을 능가했습니다.
다양성 작업에서 LLaMA1-QA는 딥 러닝 기준(0.3198)보다 성능이 뛰어납니다. 이러한 결과는 LLM이 특정 과학 작업에서 큰 잠재력을 가지고 있음을 나타냅니다.
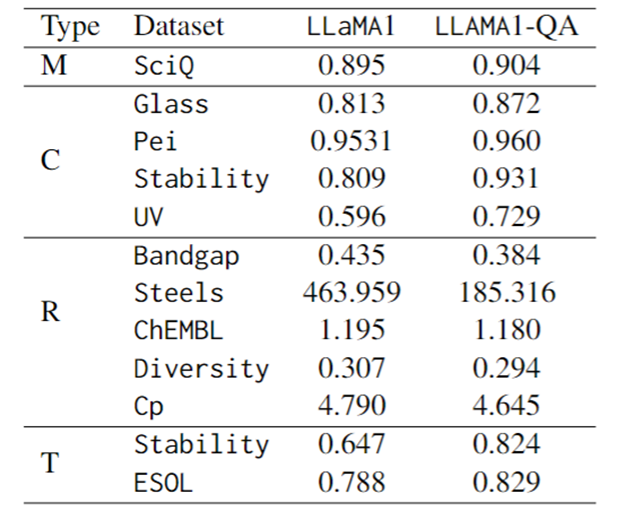
그림: SciQ 및 과학 작업에서 LLaMA1 및 LLaMA1-QA의 성능 미세 조정(M은 객관식, C는 분류, R은 회귀, T는 변환을 나타냄)
요약 및 전망
( 1) SciQAG는 QA 쌍을 평가하고 선별하기 위한 RACAR 측정항목과 결합하여 과학 문헌에서 QA 쌍을 생성하기 위한 프레임워크로, 자원이 부족한 과학 분야에 대한 대량의 지식 기반 QA 데이터를 효율적으로 생성할 수 있습니다.
(2) 팀은 SciQAG-24D라고 하는 188,042개의 QA 쌍을 포함하는 포괄적인 오픈 소스 과학 QA 데이터 세트를 생성했습니다. 훈련 세트는 LLM을 미세 조정하는 데 사용되며, 테스트 세트는 개방형 비공개 책 과학 QA 작업에서 LLM의 성능을 평가합니다.
SciQAG-24D 테스트 세트에서 여러 LLM의 제로 샘플 성능을 비교하고 SciQAG-24D 훈련 세트에서 LLaMA1을 미세 조정하여 LLaMA1-QA를 얻었습니다. 이러한 미세 조정을 통해 여러 과학 작업의 성능이 크게 향상됩니다.
(3) 연구에 따르면 LLM은 과학 작업에 잠재력이 있으며 LLaMA1-QA의 결과는 기계 학습 기준을 훨씬 초과하는 수준에 도달할 수 있습니다. 이는 SciQAG-24D의 다각적인 유용성을 보여주고 과학적 QA 데이터를 교육 프로세스에 통합하면 LLM의 과학적 지식 학습 및 적용 능력을 향상시킬 수 있음을 보여줍니다.
위 내용은 대형 모델에 대한 새로운 과학적이고 복잡한 질문 답변 벤치마크 및 평가 시스템을 제공하기 위해 UNSW, Argonne, University of Chicago 및 기타 기관이 공동으로 SciQAG 프레임워크를 출시했습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!