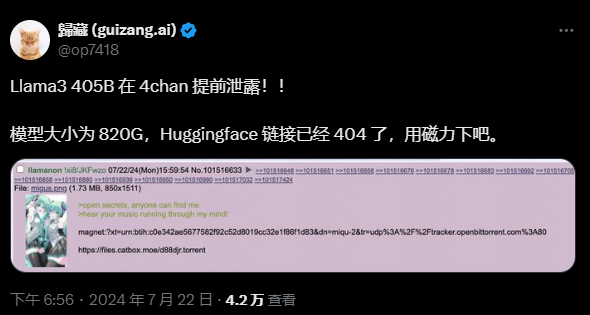
Llama 3.1이 드디어 등장했지만 출처는 Meta 공식이 아닙니다. 오늘 Reddit에는 신형 Llama 대형 모델 유출 소식이 입소문이 났습니다. 기본 모델 외에도 벤치마크 결과 8B, 70B, 최대 매개변수 405B도 포함되어 있습니다. 
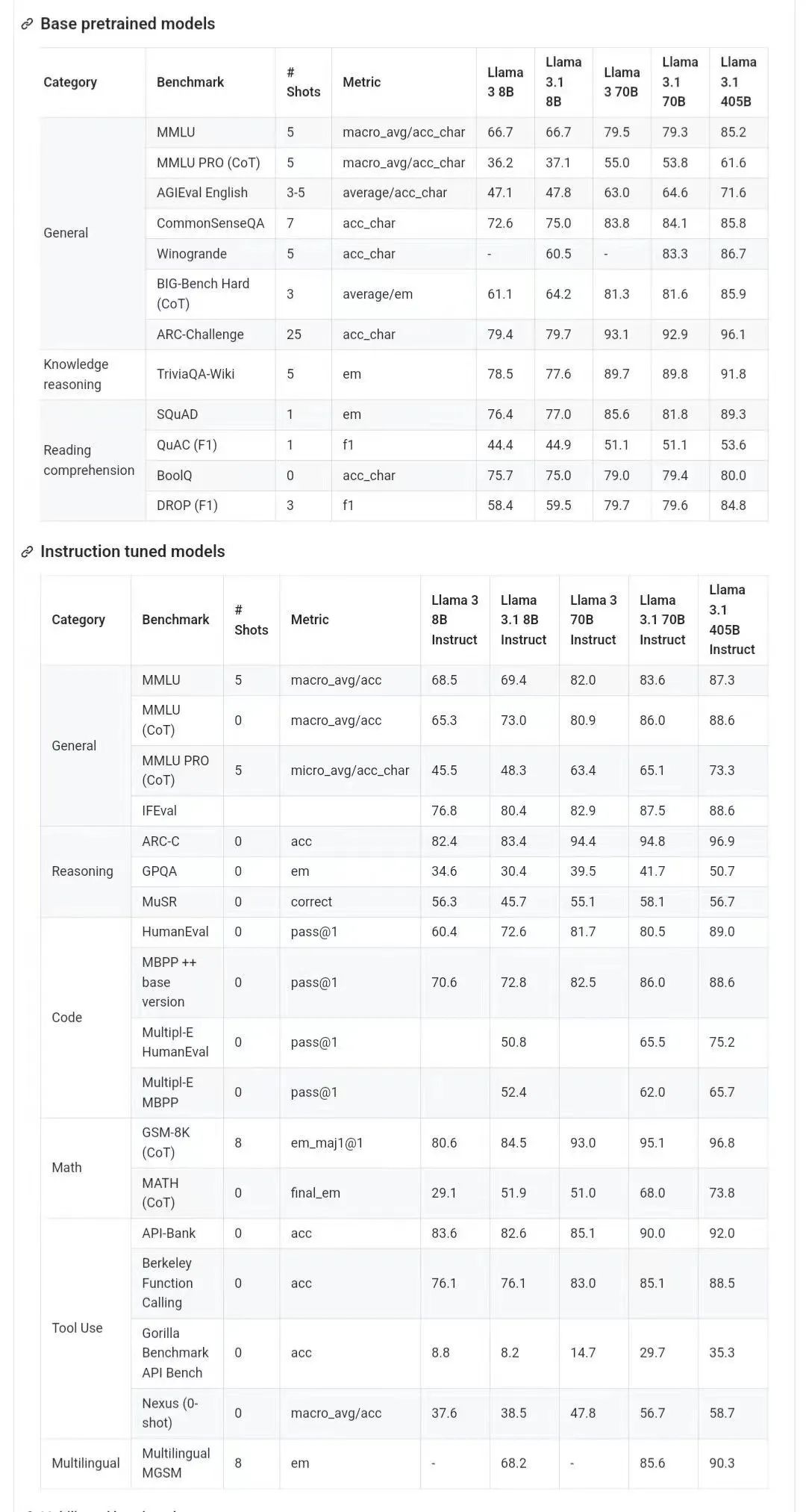
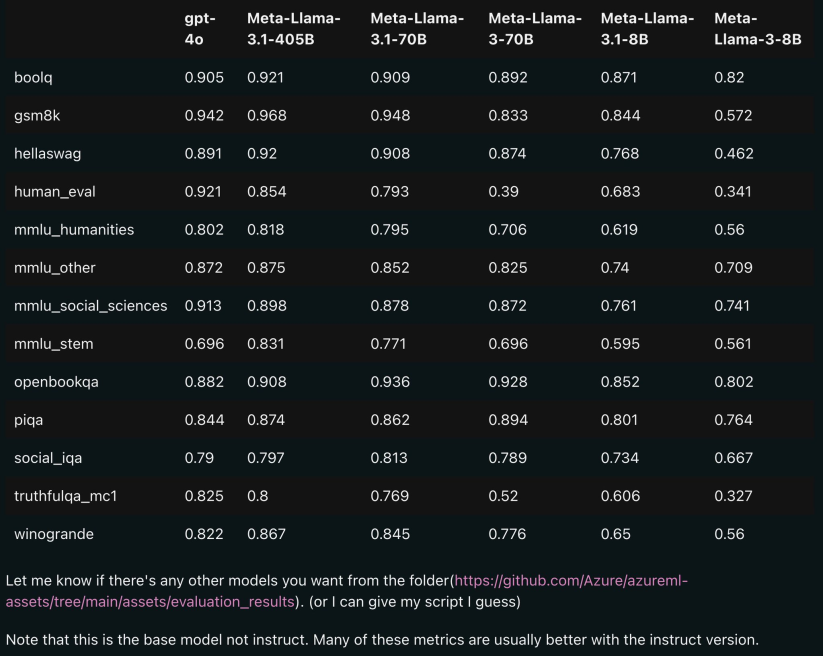
아래 그림은 Llama 3.1 각 버전과 OpenAI GPT-4o, Llama 3 8B/70B의 비교 결과를 보여줍니다. 보시다시피 70B 버전도 여러 벤치마크에서 GPT-4o를 능가합니다. ㅋㅋ 버전 3.1의 8B 및 70B 모델은 405B를 증류한 것이므로 이전 세대에 비해 성능이 크게 향상되었습니다.
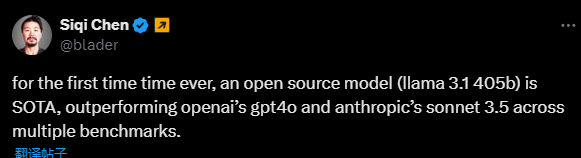
일부 네티즌들은 오픈 소스 모델이 GPT4o, Claude Sonnet 3.5 등 폐쇄 소스 모델을 능가하고 여러 벤치마크에서 SOTA에 도달한 것은 이번이 처음이라고 말했습니다. 동시에 Llama 3.1의 모델 카드가 유출되며 세부 정보가 유출되었습니다(모델 카드에 표시된 날짜는 7월 23일 출시 기준임을 나타냅니다).
모델은 교육을 위해 공개 소스의 15T+ 토큰을 사용하며 사전 교육 데이터 마감일은 2023년 12월입니다.
미세 조정 데이터에는 공개가 포함됩니다. 사용 가능한 지침 미세 조정 데이터 세트(Llama 3과 다름) 및 1,500만 개의 합성 샘플
모델은 영어, 프랑스어, 독일어, 힌디어, 이탈리아어, 포르투갈어, 스페인어 및 태국어를 포함한 여러 언어를 지원합니다. ㅋㅋㅋ ~
현재 유출된 Github 링크는 404이지만 일부 네티즌들이 다운로드 링크를 제공하고 있습니다(단, 안전을 위해 오늘 밤 공식 채널 공지를 기다려 주시길 권장드립니다):
-
하지만 이것은 결국 1000억 레벨 모델이므로 다운로드하기 전에 충분한 하드 디스크 공간을 준비하십시오.
다음은 Llama 3.1 모델입니다. 카드의 중요 내용:
기본 모델 정보
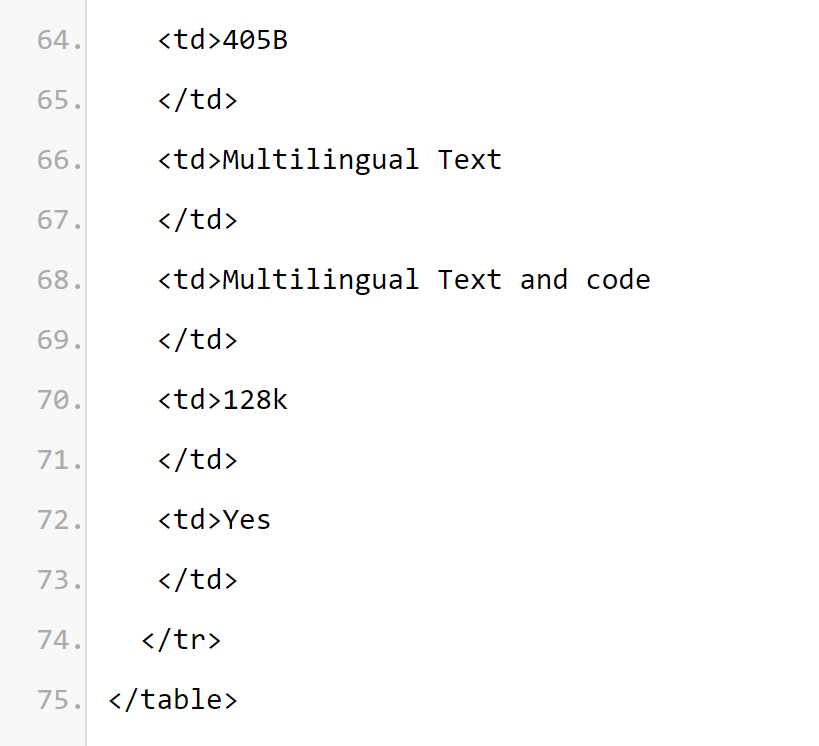
Meta Llama 3.1 다국어 대형 언어 모델(LLM) 컬렉션은 사전 훈련되고 명령이 미세 조정된 생성 모델 세트로, 각각 크기는 8B, 70B 및 405B(텍스트 입력/텍스트 출력)입니다. Llama 3.1 명령으로 미세 조정된 텍스트 전용 모델(8B, 70B, 405B)은 다국어 대화 사용 사례에 최적화되어 있으며 일반적인 업계 벤치마크에서 사용 가능한 많은 오픈 소스 및 비공개 소스 채팅 모델보다 성능이 뛰어납니다. 모델 아키텍처: Llama 3.1은 최적화된 Transformer 아키텍처 자동 회귀 언어 모델입니다. 미세 조정된 버전은 SFT 및 RLHF를 사용하여 유용성과 보안 기본 설정을 조정합니다.
지원되는 언어: 영어, 독일어, 프랑스어, 이탈리아어, 포르투갈어, 힌디어, 스페인어, 태국어.
모델 카드 정보를 통해
Llama 3.1 시리즈 모델의 컨텍스트 길이가 128k
임을 유추할 수 있습니다. 모든 모델 버전은 추론 확장성을 향상하기 위해 GQA(Grouped Query Attention)를 사용합니다.
사용 목적 사례. Llama 3.1은 다국어 비즈니스 애플리케이션 및 연구용으로 제작되었습니다. 명령 조정된 텍스트 전용 모델은 보조자와 같은 채팅에 적합한 반면, 사전 훈련된 모델은 다양한 자연어 생성 작업에 적용할 수 있습니다. Llama 3.1 모델 세트는 모델 출력을 활용하여 합성 데이터 생성 및 증류를 포함한 다른 모델을 개선하는 기능도 지원합니다. Llama 3.1 커뮤니티 라이센스는 이러한 사용 사례를 허용합니다. Llama 3.1은 지원되는 8개 언어보다 더 다양한 언어를 학습합니다. 개발자는 Llama 3.1 커뮤니티 라이센스 계약 및 허용 가능한 사용 정책을 준수하는 경우 지원되는 8개 언어 이외의 언어에 대해 Llama 3.1 모델을 미세 조정할 수 있으며, 그러한 경우 다른 언어가 사용되도록 보장할 책임이 있습니다. 안전하고 책임감 있는 태도 언어 라마 3.1. 첫 번째는 교육 요소입니다. Llama 3.1은 사전 교육을 위해 맞춤형 교육 라이브러리, 메타 맞춤형 GPU 클러스터 및 생산 인프라를 사용하며 생산 인프라, 주석 및 평가. 두 번째는 훈련 에너지 소비입니다. Llama 3.1 훈련은 H100-80GB(TDP는 700W) 유형 하드웨어에서 총 3930만 GPU 계산 시간을 사용합니다. 여기서 훈련 시간은 각 모델을 훈련하는 데 필요한 총 GPU 시간이고, 전력 소비는 전력 효율성을 위해 조정된 각 GPU 장치의 최대 전력 용량입니다. 온실가스 배출 교육. 지리적 벤치마크를 기반으로 한 총 온실가스 배출량은 Llama 3.1 훈련 기간 동안 11,390톤의 CO2e로 추산됩니다. 2020년부터 Meta는 전 세계 운영 전반에 걸쳐 순제로 온실가스 배출을 유지하고 전력 사용의 100%를 재생 가능 에너지와 일치시켜 교육 기간 동안 총 시장 기준 온실가스 배출량이 0톤 CO2e에 이르렀습니다. 훈련 에너지 사용 및 온실가스 배출을 결정하는 데 사용되는 방법은 다음 논문에서 확인할 수 있습니다. Meta는 이러한 모델을 공개적으로 공개하기 때문에 다른 사람들이 에너지 사용 및 온실가스 배출에 대한 교육 부담을 질 필요가 없습니다. 논문 주소: https://arxiv.org/pdf/2204.05149개요: Llama 3.1은 공개 소스에서 얻은 약 1.5조 개의 토큰 데이터를 사용하여 수행되었습니다. 훈련. 미세 조정 데이터에는 공개적으로 사용 가능한 명령 데이터 세트와 합성으로 생성된 2,500만 개가 넘는 예제가 포함됩니다. 데이터 최신성: 사전 학습 데이터의 마감일은 2023년 12월입니다. 이 섹션에서 Meta는 주석 벤치마크에서 Llama 3.1 모델의 점수 결과를 보고합니다. 모든 평가를 위해 Meta는 내부 평가 라이브러리를 사용합니다.
Security Risk ConsiderationsThe Llama research team is committed to providing the research community with valuable resources to study the robustness of security fine-tuning and providing developers with safe and robust off-the-shelf models for a variety of applications to Reduce the workload of developers deploying secure AI systems. The research team uses a multi-faceted data collection approach, combining human-generated data from vendors with synthetic data to mitigate potential security risks. The research team developed a number of large language model (LLM)-based classifiers to thoughtfully select high-quality prompts and responses, thereby enhancing data quality control. It is worth mentioning that Llama 3.1 attaches great importance to the model rejection of benign prompts and rejection tone. The research team introduced boundary prompts and adversarial prompts into the secure data policy and modified secure data responses to follow tone guidelines. The Llama 3.1 model is not designed to be deployed alone, but should be deployed as part of the overall artificial intelligence system, with additional "safety guardrails" provided as needed. Developers should deploy system security measures when building agent systems. Please note that this release introduces new features, including longer context windows, multilingual input and output, and possible developer integration with third-party tools. When building with these new features, in addition to considering the best practices that generally apply to all generative AI use cases, you also need to pay special attention to the following issues: Tool usage: As with standard software development, the developer is responsible Integrate LLM with the tools and services of their choice. They should develop clear policies for their use cases and evaluate the integrity of the third-party services they use to understand the safety and security limitations when using this functionality. Multi-language: Lama 3.1 supports 7 languages in addition to English: French, German, Hindi, Italian, Portuguese, Spanish and Thai. Llama may be able to output text in other languages, but this text may not meet security and helpability performance thresholds. Llama 3.1’s core values are openness, inclusiveness and helpfulness. It's designed to serve everyone and suitable for a variety of use cases. Therefore, Llama 3.1 is designed to be accessible to people of all backgrounds, experiences and perspectives. Llama 3.1 is centered around users and their needs, without inserting unnecessary judgments or norms, while also reflecting the recognition that even content that may seem problematic in some contexts can be useful in others. value purpose. Llama 3.1 respects the dignity and autonomy of all users and, in particular, respects the values of free thought and expression that fuel innovation and progress. But Llama 3.1 is a new technology, and like any new technology, there are risks in its use. Testing conducted to date has not and cannot cover all situations. Therefore, like all LLMs, the potential outputs of Llama 3.1 cannot be predicted in advance, and in some cases the model may react inaccurately, biasedly, or otherwise objectionably to user prompts. Therefore, before deploying any application of the Llama 3.1 model, developers should perform security testing and fine-tuning for the specific application of the model. Model card source: https://pastebin.com/9jGkYbXYReference information: https://x.com/op7418/status/1815340034717069728 https: //x.com/iScienceLuvr/status/1815519917715730702https://x.com/mattshumer_/status/1815444612414087294위 내용은 GPT4o 수준을 능가하는 최초의 오픈 소스 모델! Llama 3.1 유출: 4,050억 개의 매개변수, 다운로드 링크 및 모델 카드 사용 가능의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!




 모델 카드 정보를 통해
모델 카드 정보를 통해