
Jia Jiaya 팀은 Cambridge Tsinghua University 등과 팀을 이루어 대형 모델에서 1초 만에 '높은 점수와 낮은 에너지'를 감지하는 새로운 평가 패러다임을 추진했습니다.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB원래의
- 2024-07-19 13:55:25576검색

MR-Ben은 GPT4-Turbo, Cluade3.5-Sonnet, Mistral-Large, Zhipu-GLM4, Moonshot-v1, Yi-Large, Qwen2 등 많은 국내외 1차 오픈소스 및 폐쇄소스 모델을 신중하게 평가했습니다. -70B , Deepseek-V2 등을 대상으로 정밀분석을 실시하였습니다.
겉보기에는 아름다워 보이는 대형 모델이 "제거"될 것이며, 표면이 가장 강한 모델은 무엇입니까? 현재 이 작품의 모든 코드와 데이터는 오픈소스로 공개되어 있으니 살펴보세요!
프로젝트 페이지: https://randolph-zeng.github.io/Mr-Ben.github.io/
Arxiv 페이지: https://arxiv.org/abs/2406.13975
Github 저장소: https://github.com /dvlab-research/Mr-Ben
MR-Ben은 대형 모델의 '고득점 저에너지'를 단 몇 초 만에 깨뜨립니다
인공지능 분야가 GPT에 돌입한 이후, 학계와 산업계가 협력하여 매년 새로운 모델이 출시되었습니다. 매달 또는 심지어 매주.
대형 모델은 끝없이 등장합니다. 대형 모델의 구체적인 능력을 측정하는 데는 어떤 기준이 사용되나요? 현재 주류 방향은 대규모 모델 평가를 수행하기 위해 객관식 질문과 빈칸 채우기 질문 등 인간 표준화 테스트를 사용하는 것입니다. 이 테스트 방법을 사용하면 다음과 같이 요약할 수 있는 많은 이점이 있습니다.
• 표준화된 테스트는 정량화 및 평가가 쉽고, 기준이 명확하며, 옳은 것은 옳고 그른 것은 그름입니다.
• 지표가 직관적이어서 국내 대학 입시나 미국 대학 입시 SAT에서 얻은 점수를 비교하고 이해하기 쉽습니다.
• 정량적 결과는 자연스럽게 화제가 됩니다(예를 들어, 미국 변호사 자격증 시험을 쉽게 통과하는 GPT4의 능력은 매우 눈길을 끕니다).
그러나 대형 모델의 훈련 방법을 자세히 살펴보면 최종 답을 생성하는 이 단계별 사고 연쇄 방법이 '신뢰할 수 없다'는 것을 알게 됩니다.
단계별 답변 과정에서 질문이 정확하게 등장합니다!
사전 학습 모델은 사전 학습 중에 이미 수조 개의 단어 요소를 확인했습니다. 평가 중인 모델이 이미 해당 데이터를 확인했으며 "질문을 암기"하여 질문에 올바르게 답할 수 있는지 말하기는 어렵습니다. 단계별 답변에서는 평가 방법이 주로 최종 답변 확인에 의존하기 때문에 모델이 올바른 이해와 추론을 바탕으로 올바른 옵션을 선택하는지 여부를 알 수 없습니다.
GSM8K에 MGSM 데이터 세트의 다국어 버전을 도입하고 MMLU를 기반으로 더 어려운 질문을 도입하는 등 학계에서는 GSM8K 및 MMLU와 같은 데이터 세트를 계속 업그레이드하고 변형하고 있지만 여전히 제거할 수 있는 방법은 없습니다. 빈칸을 선택하거나 채우는 문제.
게다가 이러한 데이터 세트는 모두 심각한 포화 문제에 직면해 있습니다. 이러한 지표에 대한 대규모 언어 모델의 값은 정점에 도달했으며 점차 구별력을 잃었습니다.
이를 위해 Jiajiaya 팀은 MIT, Tsinghua, Cambridge 등 여러 유명 대학과 협력하고 국내 헤드 주석 회사와 협력하여 복잡한 문제의 추론 과정을 위한 평가 데이터 세트 MR-Ben에 주석을 달았습니다.
MR-Ben은 GSM8K, MMLU, LogiQA, MHPP 및 기타 대형 모델의 사전 학습 및 테스트 데이터 세트의 질문을 기반으로 "등급화" 패러다임 변환을 수행했습니다. 더 어렵고, 더 차별화되고, 더 현실적으로 모델의 추론 능력을 반영합니다!
Jiajiaya 팀의 이번 작업에서는 기존 평가 문제점을 해결하기 위해 목표한 개선도 이루어졌습니다.
데이터 유출로 인해 문제의 대규모 모델 암기가 발생하여 점수가 부풀려질까 봐 두렵지 않으신가요? 모델의 견고성을 테스트하기 위해 질문을 다시 찾거나 질문을 변형할 필요가 없습니다. MR-Ben은 답변자의 학생 ID에서 답변 프로세스의 "채점" 모드로 모델을 직접 변경합니다. 테스트할 교사가 될 모델 지식 포인트를 얼마나 잘 마스터합니까!
모델이 문제 해결 과정에 대한 인식이 부족하고, '환상'이나 오해가 있어서 답이 틀리게 나올 수도 있다는 걱정은 안 되시나요? MR-Ben은 높은 수준의 석박사 주석가 그룹을 직접 모집하여 수많은 질문에 대한 문제 해결 과정을 주의 깊게 주석을 달았습니다. 문제 해결 과정이 올바른지, 오류가 발생한 위치, 오류가 발생한 원인을 자세히 지적하고, 대형 모델의 등급 결과와 인간 전문가의 등급 결과를 비교하여 모델의 지식에 대한 지식을 테스트합니다. 포인트들.
구체적으로 Jiajiaya 팀은 GSM8K, MMLU, LogiQA, MHPP 및 기타 데이터 세트와 같은 시장의 주류 평가 데이터 세트를 구성하고 이를 수학, 물리학, 화학, 생물학, 코드, 논리, 의학과 같은 여러 범주로 나누었습니다. 등, 또한 구별되는 다양한 난이도 수준. 수집된 각 항목과 각 질문에 대해 팀은 해당 단계별 문제 해결 프로세스를 신중하게 수집했으며 전문 석박사 주석가의 교육과 주석을 받았습니다.
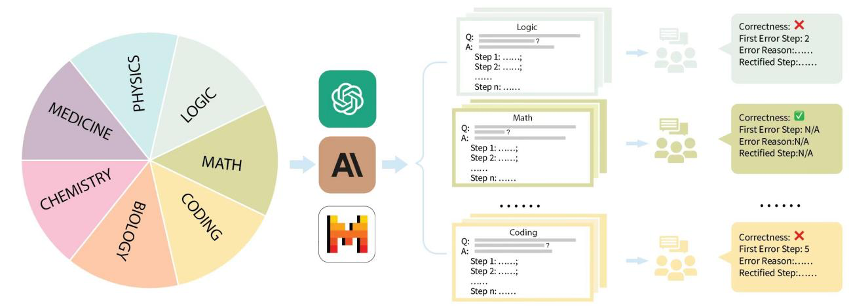
Ensuite, combinons les exemples spécifiques donnés dans le travail de MR-Ben pour voir pourquoi la méthode étape par étape de génération des réponses finales et des évaluations associées n'est pas fiable.
En tant que modèle de « notation » évalué, GPT4-Turbo n'a pas trouvé les erreurs de calcul cachées dans la deuxième étape :
E.1 Mathématiques
Matière : Mathématiques du lycée
Question : Quel plus petit entier est divisé par 4 comme reste 1, reste 2 lorsqu'il est divisé par 3, reste 2 lorsqu'il est divisé par 5 ?
Options : [A] 67 [B] 43 [C] 57 [D] 37
Réponse : D
Modèle d'échantillonnage : Claude2
Étapes de la solution du modèle :
- Étape 1 : Cochez l'option A (67) lorsque Lorsque 67 est divisé par 4, le reste est 3 et non 1. Donc 67 n’est pas la bonne réponse.
- Étape 2 : Cochez l'option B (43) Lorsque 43 est divisé par 4, le reste est 1. Lorsque 43 est divisé par 3, le reste est 3 et non 2. Donc 43 n’est pas la bonne réponse.
- Étape 3 : Cochez l'option C (57) Lorsque 57 est divisé par 4, le reste est 1. Lorsque 57 est divisé par 3, le reste est 0 et non 2. Donc 57 n’est pas la bonne réponse.
- Étape 4 : Cochez l'option D (37) Lorsque 37 est divisé par 4, le reste est 1. Lorsque 37 est divisé par 3, le reste est 1. Lorsque 37 est divisé par 5, le reste est 2.
-
Étape 5 : L'option D (37) remplit toutes les conditions et constitue la bonne réponse.
Réponse : Option D
Annotation humaine
Exactement de la réponse du modèle : Incorrecte
Première mauvaise étape : Étape 2
Raison de l'erreur de réponse du modèle :
À l'étape 2, le modèle a calculé de manière incorrecte que le reste de 43 divisé par 4 est 1 à la place de 3. Le modèle suppose que lorsque 43 est divisé par 4, le reste est 1, mais le reste devrait être 3. Il y a ici une erreur de calcul.La première étape correcte après correction : Étape 2
Lorsque 43 est divisé par 4, le reste est 1. Lorsque 43 est divisé par 3, le reste est 1. Lorsque 43 est divisé par 5, le reste est 3 et non 2. Par conséquent, 43 n’est pas la bonne réponse.
Modèle d'évaluation : gpt-4-turbo
Réponse du modèle :
-Étape 1 : Étape vérifier le reste de 67 divisé par 4 et 3, et constater qu'il remplit la condition d'être divisé par 4 et restant 3, ce qui est une vérification correcte.
-Étape 2 : Vérifiez les restes de la division de 43 par 4, 3 et 5, et constatez que les restes de 1, 3 et 5 correspondent correctement aux attentes, sauf que le reste de 5 ne remplit pas les conditions.
-Étape 3 : Étape Calculez le reste de la division de 57 par 4 et 3, les restes sont respectivement 1 et 0. Lorsque 57 est divisé par 3, le reste ne répond pas aux critères.
-Étape 4 : Vérifiez et vérifiez les restes de la division de 37 par 4, 3 et 5. Il s'avère que tous les restes attendus sont exacts et que 37 remplit toutes les conditions de la question.Le processus de solution est-il correct ? Correct
La première étape d'erreur : Sans objet
La raison de la première étape d'erreur : Sans objet
On peut voir que lorsque la question est posée et que le processus de solution est déterminé , l'évaluation La méthode du modèle de langage est transformée en permettant au modèle de « marquer » le processus de réponse, de juger s'il est correct ou incorrect et d'indiquer l'emplacement et la cause de l'erreur. La précision du processus de résolution et les emplacements d'erreurs potentiels peuvent être calculés en comparant avec les résultats de l'annotation. L'évaluation des étapes et des raisons d'erreur du modèle peut être confiée à GPT4 pour déterminer si le modèle est correct en comparant l'explication des raisons d'erreur donnée par l'annotateur et l'explication des raisons d'erreur du modèle.
De la méthode d'évaluation, la méthode proposée par MR-Ben nécessite que le modèle effectue une analyse détaillée des prémisses, des hypothèses et de la logique de chaque étape du processus de résolution de problèmes, et prévisualise le processus de raisonnement pour déterminer si le l’étape actuelle peut conduire à la bonne direction. fenye1. Cette méthode d'évaluation de « notation » est bien plus difficile que la méthode d'évaluation consistant simplement à répondre aux questions, mais elle peut efficacement éviter le problème des scores faussement élevés causés par la mémorisation des questions par le modèle. Il est difficile pour un étudiant qui ne sait que mémoriser des questions de devenir un professeur de notation qualifié.
- Deuxièmement, MR-Ben a réalisé un grand nombre d'annotations de haute qualité en utilisant un contrôle manuel et précis du processus d'annotation, et la conception intelligente du processus permet de quantifier intuitivement la méthode d'évaluation.
- L'équipe Jiajiaya a également testé les dix modèles linguistiques les plus représentatifs et différentes versions. On peut voir que parmi les grands modèles de langage à source fermée, GPT4-Turbo a les meilleures performances (bien qu'aucune erreur de calcul n'ait été trouvée lors de la « notation »). Dans la plupart des matières, il y a des démos (k=1) et aucune démo. (k=0) sont en avance sur les autres modèles.
**Résultats de l'évaluation de certains grands modèles de langage open source sur l'ensemble de données MR-Ben
On peut constater que les effets de certains des grands modèles de langage open source les plus puissants ont rattrapé certains modèles commerciaux, et même les plus puissants modèles de langage fermés. les modèles sont dans MR-Ben. Les performances sur l'ensemble de données Ben ne sont toujours pas saturées et la différence entre les différents modèles est grande.
De plus, l'article original de MR-Ben contient des analyses et des découvertes plus intéressantes, telles que :

Les modèles open source publiés par Qwen et Deepseek ne sont pas inférieurs au modèle source fermé PK, même à l'échelon mondial.
Les stratégies de tarification et les performances réelles des différents modèles fermés sont intrigantes. Les amis préoccupés par la capacité de raisonnement dans les scénarios d’utilisation peuvent trouver leur modèle préféré à utiliser en fonction du prix et des capacités.
Dans les scénarios à faibles ressources, les petits modèles présentent également de nombreux points forts. Dans l'évaluation MR-Ben, le Phi-3-mini s'est démarqué parmi les petits modèles, encore plus haut ou identique que les grands modèles avec des dizaines de milliards de paramètres, montrant. la possibilité d’affiner l’importance des données.
Les scènes MR-Ben contiennent une analyse logique complexe et une inférence étape par étape. Un contexte trop long en mode Quelques plans confondra le modèle et entraînera une baisse des performances.
MR-Ben a évalué de nombreuses expériences d'ablation génération-réflexion-régénération pour vérifier les différences entre les différentes stratégies d'incitation et a constaté qu'elle n'a aucun effet sur les modèles de bas niveau, et que l'effet sur les modèles de haut niveau tels que GPT4-Turbo n'est pas évident. Au contraire, pour les modèles de niveau intermédiaire, l'effet est légèrement amélioré car les mauvais sont toujours corrigés et les bons sont toujours corrigés.
Après avoir divisé grossièrement les sujets évalués par MR-Ben en types basés sur la connaissance, logiques, informatiques et algorithmiques, différents modèles ont leurs propres avantages et inconvénients dans différents types de raisonnement.
L'équipe Jiajiaya a mis en ligne une méthode d'évaluation en un clic sur github. Tous les amis préoccupés par un raisonnement complexe sont invités à évaluer et à soumettre leurs propres modèles. L'équipe mettra à jour le classement correspondant en temps opportun.
À propos, l'évaluation en un clic à l'aide du script officiel ne coûte qu'environ 12 millions de jetons. Le processus est très fluide, alors essayez-le !
Référence
Formation des vérificateurs pour résoudre les problèmes de mots mathématiques (https://arxiv.org/abs/2110.14168)
Mesure de la compréhension massive du langage multitâche (https://arxiv.org/abs/2009.03300)
LogiQA : un défi Ensemble de données pour la compréhension en lecture automatique avec raisonnement logique(https://arxiv.org/abs/2007.08124)
MHPP : Explorer les capacités et les limites des modèles de langage au-delà de la génération de code de base(https://arxiv.org/abs/2405.11430)
Étincelles de l'intelligence générale artificielle : premières expériences avec GPT-4(https://arxiv.org/abs/2303.12712)
Rapport technique Qwen(https://arxiv.org/abs/2309.16609)
DeepSeek-V2 : un puissant, Modèle linguistique mixte d'experts économique et efficace(https://arxiv.org/abs/2405.04434)
Les manuels sont tout ce dont vous avez besoin(https://arxiv.org/abs/2306.11644)
Les grands modèles linguistiques ne peuvent pas s'auto- Raisonnement correct pour l'instant(https://arxiv.org/abs/2310.01798)
위 내용은 Jia Jiaya 팀은 Cambridge Tsinghua University 등과 팀을 이루어 대형 모델에서 1초 만에 '높은 점수와 낮은 에너지'를 감지하는 새로운 평가 패러다임을 추진했습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!