
시각적 인코더를 포기한 이 '네이티브 버전' 다중 모드 대형 모델은 주류 방법과도 비슷합니다.

- WBOY원래의
- 2024-07-18 19:21:11368검색

Lajur AIxiv ialah lajur di mana tapak ini menerbitkan kandungan akademik dan teknikal. Dalam beberapa tahun kebelakangan ini, lajur AIxiv laman web ini telah menerima lebih daripada 2,000 laporan, meliputi makmal terkemuka dari universiti dan syarikat utama di seluruh dunia, mempromosikan pertukaran dan penyebaran akademik secara berkesan. Jika anda mempunyai kerja yang sangat baik yang ingin anda kongsikan, sila berasa bebas untuk menyumbang atau hubungi kami untuk melaporkan. E-mel penyerahan: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
Yizuo Diao Haiwen ialah pelajar kedoktoran di Universiti Teknologi Dalian, dan penyelianya ialah Profesor Lu Huchuan. Sedang berkhidmat di Institut Penyelidikan Kepintaran Buatan Beijing Zhiyuan, pengajarnya ialah Dr. Wang Xinlong. Minat penyelidikannya ialah visi dan bahasa, pemindahan model besar yang cekap, model besar berbilang modal, dsb. Pengarang bersama pertama Cui Yufeng lulus dari Universiti Beihang dan merupakan penyelidik algoritma di Pusat Penglihatan Institut Penyelidikan Kepintaran Buatan Zhiyuan Beijing. Minat penyelidikannya ialah model multimodal, model generatif, dan visi komputer, dan kerja utamanya adalah dalam siri Emu.
Baru-baru ini, penyelidikan mengenai model besar berbilang modal sedang giat dijalankan, dan industri telah melabur lebih banyak lagi dalam hal ini. Model hangat telah dilancarkan di luar negara, seperti GPT-4o (OpenAI), Gemini (Google), Phi-3V (Microsoft), Claude-3V (Anthropic), dan Grok-1.5V (xAI). Pada masa yang sama, domestik GLM-4V (Wisdom Spectrum AI), Step-1.5V (Step Star), Emu2 (Beijing Zhiyuan), Intern-VL (Shanghai AI Laboratory), Qwen-VL (Alibaba), dll. Model berkembang .
Model bahasa visual (VLM) semasa biasanya bergantung pada pengekod visual (Vision Encoder, VE) untuk mengekstrak ciri visual, dan kemudian menggabungkan arahan pengguna dengan model bahasa besar (LLM) untuk memproses dan menjawab dalam pengekod visual dan pemisahan Latihan untuk model bahasa yang besar. Pemisahan ini menyebabkan pengekod visual memperkenalkan isu bias induksi visual apabila antara muka dengan model bahasa yang besar, seperti peleraian imej dan nisbah bidang yang terhad, serta semantik visual yang kuat. Memandangkan kapasiti pengekod visual terus berkembang, kecekapan penggunaan model besar berbilang mod dalam memproses isyarat visual juga amat terhad. Di samping itu, cara mencari konfigurasi kapasiti optimum pengekod visual dan model bahasa besar telah menjadi semakin kompleks dan mencabar.
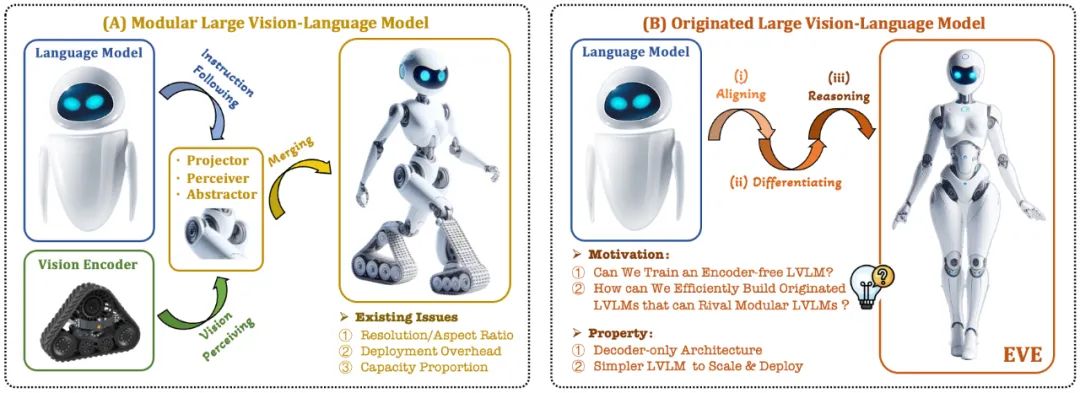
Dalam konteks ini, beberapa idea yang lebih canggih muncul dengan cepat:
Bolehkah kita mengalih keluar pengekod visual, iaitu membina secara langsung model besar berbilang mod asli tanpa pengekod visual?
Bagaimana untuk mengembangkan model bahasa besar dengan cekap dan lancar menjadi model besar berbilang modal asli tanpa pengekod visual?
Bagaimana untuk merapatkan jurang prestasi antara rangka kerja berbilang modal asli tanpa pengekod dan paradigma berbilang modal berasaskan pengekod arus perdana?
Adept AI mengeluarkan model siri Fuyu pada penghujung tahun 2023 dan membuat beberapa percubaan berkaitan, tetapi tidak mendedahkan sebarang strategi latihan, sumber data dan maklumat peralatan. Pada masa yang sama, terdapat jurang prestasi yang ketara antara model Fuyu dan algoritma arus perdana dalam penunjuk penilaian teks visual awam. Dalam tempoh yang sama, beberapa percubaan rintis yang kami jalankan menunjukkan bahawa walaupun skala data pra-latihan ditingkatkan secara besar-besaran, model besar multi-modal asli tanpa pengekod masih menghadapi masalah yang sukar seperti kelajuan penumpuan yang perlahan dan prestasi yang lemah.
Sebagai tindak balas kepada cabaran ini, pasukan visi Institut Penyelidikan Zhiyuan, bersama-sama Universiti Teknologi Dalian, Universiti Peking dan universiti domestik lain, melancarkan generasi baharu model bahasa visual tanpa pengekod EVE. Melalui strategi latihan yang diperhalusi dan penyeliaan visual tambahan, EVE menyepadukan perwakilan visual-linguistik, penjajaran dan inferens ke dalam seni bina penyahkod tulen bersatu. Menggunakan data yang tersedia secara umum, EVE berprestasi baik pada berbilang penanda aras visual-linguistik, bersaing dengan kaedah multimodal berasaskan pengekod arus perdana dengan kapasiti yang sama dan dengan ketara mengatasi prestasi rakan Fuyu-8B. EVE dicadangkan untuk menyediakan laluan yang telus dan cekap untuk pembangunan seni bina berbilang modal asli untuk penyahkod tulen.


Alamat kertas: https://arxiv.org/abs/2406.11832
Kod projek: https://github.com/baaivision ://huggingface.co/BAAI/EVE-7B-HD-v1.0
- 1
기본 시각적 언어 모델: 주류 다중 모달 모델의 고정 패러다임을 깨고 시각적 인코더를 제거하며 모든 이미지 종횡비를 처리할 수 있습니다. 여러 시각적 언어 벤치마크에서 동일한 유형의 Fuyu-8B 모델보다 훨씬 뛰어난 성능을 발휘하며 주류 시각적 인코더 기반 시각적 언어 아키텍처에 가깝습니다.
낮은 데이터 및 교육 비용: EVE 모델의 사전 교육은 OpenImages, SAM 및 LAION의 공개 데이터만 선별했으며 665,000 LLaVA 지침 데이터와 추가 120만 개의 시각적 대화 데이터를 활용하여 각각 일반 및 고급 데이터를 구축했습니다. EVE-7B의 해상도 버전. 훈련은 2개의 8-A100(40G) 노드에서 완료하는 데 약 9일이 걸리거나 4개의 8-A100 노드에서 약 5일이 소요됩니다.
투명하고 효율적인 탐색: EVE는 차세대 순수 디코더 시각적 언어 모델 아키텍처 개발을 위한 새로운 아이디어와 귀중한 경험을 제공하여 기본 시각적 언어 모델에 대한 효율적이고 투명하며 실용적인 경로를 탐색하려고 합니다. 미래의 다중 모드 모델은 새로운 탐색 방향을 열어줍니다.
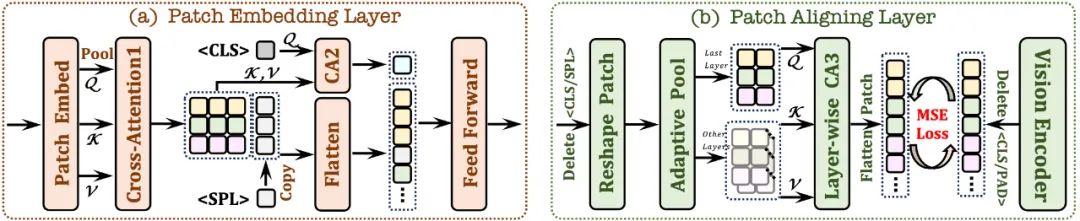
먼저 단일 컨볼루션 레이어를 사용하여 이미지의 2D 특징 맵을 얻은 다음 평균 풀링 레이어를 통해 다운샘플링합니다.
교차 주의 모듈(CA1)을 사용합니다. 제한된 수용 필드에서 상호 작용하여 각 패치의 로컬 기능을 향상합니다.
토큰을 사용하고 교차 주의 모듈(CA2)과 결합하여 각 패치 기능에서
- 네트워크가 이미지의 2차원 공간 구조를 이해하는 데 도움이 되도록 학습 가능한
토큰이 줄 끝에 삽입됩니다.
- 유효한 패치의 2D 모양을 기록하고
/ 토큰을 폐기하고 적응형 풀링 레이어를 사용하여 계층적 교차 주의를 통해 원래의 2D 모양으로 복원합니다. 모듈(CA3)은 다층 네트워크 시각적 기능을 통합하여 시각적 인코더 출력과 세밀한 정렬을 달성합니다.
3. 훈련 전략
- 생성적 사전 훈련 단계: 시각적 언어 콘텐츠를 이해하는 모델의 능력을 더욱 향상시키고 순수 언어 모델에서 다중 모드 모델로의 원활한 전환을 달성합니다.
- 감독된 미세 조정 단계: 추가 다양한 시각적 언어 벤치마크의 요구 사항을 충족하는 대화 패턴을 학습하는 능력과 언어 지침을 따르도록 모델을 표준화합니다.
- 지도 미세 조정 단계에서는 LLaVA-mix-665K 미세 조정 데이터 세트를 사용하여 EVE-7B 표준 버전을 교육하고 AI2D, Synthdog, DVQA, ChartQA, DocVQA, Vision-Flan 및 Bunny-695K EVE-7B의 고해상도 버전을 얻기 위해 훈련하도록 설정되었습니다.
4. 정량적 분석
추가 성능 개선: 실험 결과 시각적 언어 데이터만 사용한 사전 학습이 모델의 언어 능력을 크게 감소시키는 것으로 나타났습니다(SQA 점수가 65.3%에서 감소함). 63.0%)으로 나타났으나, 모델의 다중 모드 성능은 점차 개선되었다. 이는 대규모 언어 모델이 업데이트될 때 내부적으로 언어 지식에 대한 치명적인 망각이 있음을 나타냅니다. 시각적 양식과 언어 양식 간의 간섭을 줄이기 위해 순수 언어 사전 학습 데이터를 적절하게 통합하거나 전문가 혼합(MoE) 전략을 사용하는 것이 좋습니다.
인코더 없는 아키텍처의 상상: 고품질 데이터를 사용한 적절한 전략과 교육을 통해 인코더 없는 시각적 언어 모델은 인코더가 있는 모델과 경쟁할 수 있습니다. 그렇다면 동일한 모델 용량과 대규모 훈련 데이터에서 둘의 성능은 어떻습니까? 우리는 모델 용량과 훈련 데이터 양을 확장함으로써 인코더 없는 아키텍처가 인코더 기반 아키텍처에 도달하거나 심지어 능가할 수 있다고 추측합니다. 전자는 이미지를 거의 무손실로 입력하고 시각적 인코더의 선험적 편견을 피하기 때문입니다.
기본 다중 모드 모델 구축: EVE는 기본 다중 모드 모델을 효율적이고 안정적으로 구축하는 방법을 완벽하게 보여 주며, 이는 더 많은 양식(예: 오디오, 비디오, 열 화상, 깊이, 등) 및 실제 경로. 핵심 아이디어는 대규모 통합 교육을 도입하기 전에 동결된 대규모 언어 모델을 통해 이러한 양식을 사전 정렬하고 감독을 위해 해당 단일 모달 인코더 및 언어 개념 정렬을 활용하는 것입니다.
2. 모델 구조
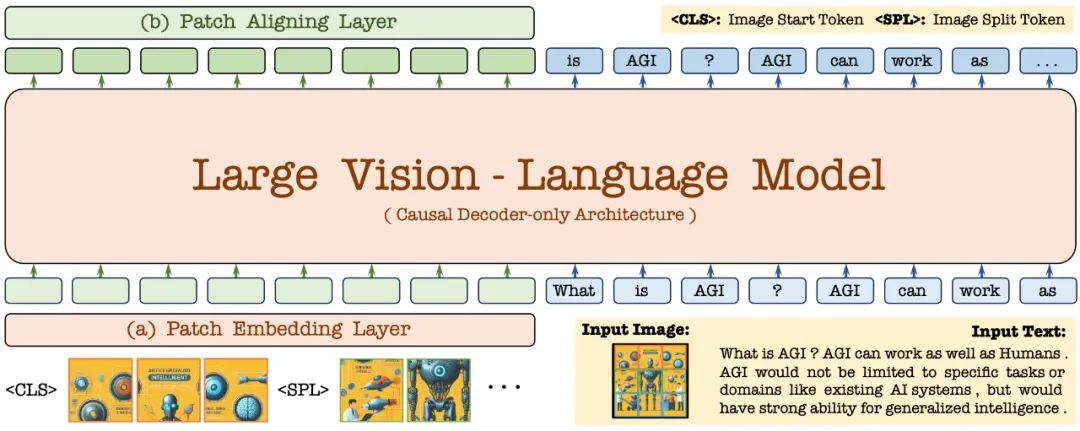
먼저 Vicuna-7B 언어 모델을 통해 초기화되므로 풍부한 언어 지식과 강력한 지시 따르기 기능을 갖췄습니다. 이를 기반으로 심층 비주얼 인코더가 제거되고 경량 비주얼 인코딩 레이어가 구성되며 이미지 입력이 효율적이고 무손실 인코딩되어 사용자 언어 명령과 함께 통합 디코더에 입력됩니다. 또한, 시각적 정렬 계층은 일반 시각적 인코더와의 특징 정렬을 수행하여 세밀한 시각적 정보 인코딩 및 표현을 향상시킵니다.
2.1 패치 임베딩 레이어
대규모 언어 모델에 따른 사전 훈련 단계: 비전과 언어 간의 초기 연결을 설정하여 후속 안정적이고 효율적인 대규모 사전 훈련을 위한 기반 마련 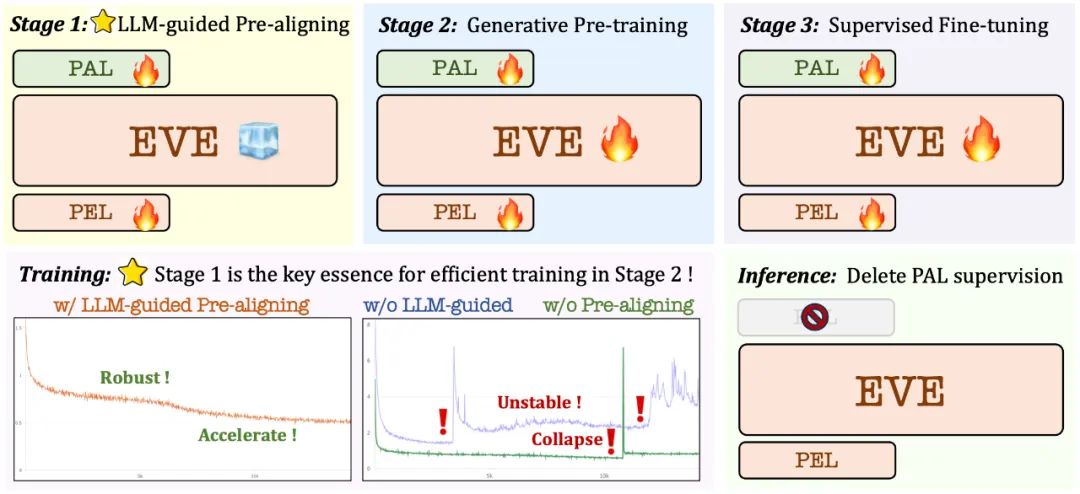
사전 학습 단계에서는 SA-1B, OpenImages 및 LAION의 공개 데이터 3,300만 개가 필터링되었으며 해상도가 448×448보다 높은 이미지 샘플만 유지되었습니다. 특히 LAION 이미지의 높은 중복성 문제를 해결하기 위해 EVA-CLIP으로 추출된 이미지 특징에 대해 K-means 클러스터링을 적용하여 50,000개의 클러스터를 생성하고 각 클러스터 이미지에 가장 가까운 300개의 이미지를 선택하여 최종적으로 선정하였다. 1,500만 개의 LAION 이미지 샘플을 선정했습니다. 이후 Emu2(17B) 및 LLaVA-1.5(13B)를 사용하여 고품질 이미지 설명이 재생성되었습니다. 
EVE 모델은 여러 시각적 언어 벤치마크에서 유사한 Fuyu-8B 모델보다 훨씬 뛰어난 성능을 발휘하며 다양한 주류 인코더 기반 시각적 언어 모델과 동등한 성능을 발휘합니다. 그러나 훈련을 위해 많은 양의 시각적 언어 데이터를 사용하기 때문에 특정 지시에 정확하게 응답하는 데 어려움이 있으며 일부 벤치마크 테스트에서 성능을 향상시킬 필요가 있습니다. 흥미로운 점은 효율적인 훈련 전략을 통해 인코더 없는 EVE가 인코더 기반 시각적 언어 모델에 필적하는 성능을 달성하여 주류 모델의 용량 일치 문제인 입력 크기 유연성, 배포 효율성 및 양식 문제를 근본적으로 해결할 수 있다는 것입니다. 언어 구조의 단순화, 풍부한 지식의 손실 등의 문제에 취약한 인코더가 있는 모델과 비교하여 EVE는 데이터 크기가 증가함에 따라 점진적이고 안정적인 성능 향상을 보여 점차 인코더의 성능에 접근합니다. 기반 모델 수준. 이는 통합 네트워크에서 시각적 및 언어 양식을 인코딩하고 정렬하는 것이 더 어렵기 때문에 인코더가 없는 모델은 인코더가 있는 모델에 비해 과적합이 덜 발생하기 때문일 수 있습니다. 5. 동료들은 어떻게 생각하나요? NVIDIA의 Ali Hatamizadeh 수석 연구원은 EVE가 참신하며 복잡한 평가 기준 구축 및 진보적인 시각적 언어 모델 개선과 다른 새로운 내러티브를 제안하려고 한다고 말했습니다. Google Deepmind의 수석 연구원인 Armand Joulin은 순수한 디코더 시각적 언어 모델을 구축하는 것이 흥미롭다고 말했습니다. Apple 기계 학습 엔지니어 Prince Canuma는 EVE 아키텍처가 매우 흥미롭고 MLX VLM 프로젝트 세트에 좋은 추가 요소라고 말했습니다. 6. 미래 전망 인코더가 없는 기본 시각적 언어 모델로서 EVE는 현재 고무적인 결과를 달성했습니다. 이 경로에는 앞으로 탐색할 가치가 있는 몇 가지 흥미로운 방향이 있습니다. 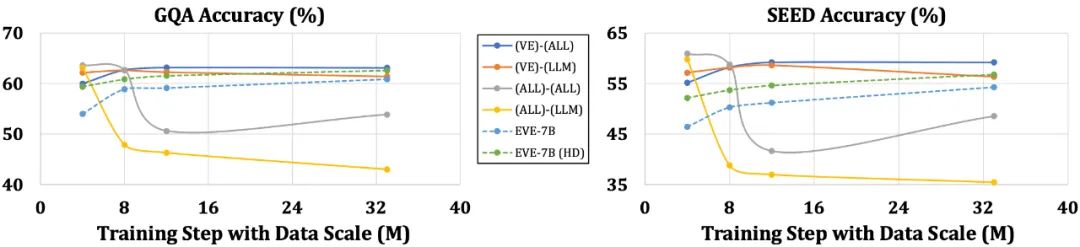



위 내용은 시각적 인코더를 포기한 이 '네이티브 버전' 다중 모드 대형 모델은 주류 방법과도 비슷합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!