大規模言語モデル (LLM) はさまざまな分野でますます使用されています。ただし、テキスト生成プロセスは高価で時間がかかります。この非効率性は、自己回帰デコードのアルゴリズムに起因します。各単語 (トークン) の生成には前方パスが必要であり、数十億から数千億のパラメータを持つ LLM へのアクセスが必要です。その結果、従来の自己回帰デコードが遅くなります。 最近、ウォータールー大学、カナダベクトル研究所、北京大学、その他の機関が共同で EAGLE をリリースしました。これは、モデル出力テキストの一貫した配布を確保しながら、大規模な言語モデルの推論速度を向上させることを目的としています。この方法は、LLM の 2 番目のトップレベルの特徴ベクトルを外挿し、生成効率を大幅に向上させることができます。 
- 技術レポート: https://sites.google.com/view/eagle-llm
- コード (商用 Apache 2.0 をサポート): https://github.com/SafeAILab/EAGLE
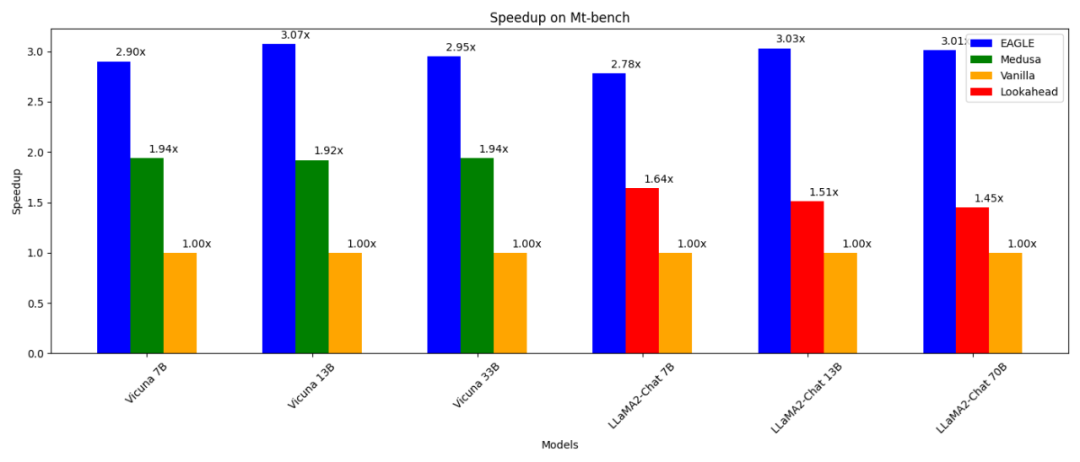
- 通常の自己回帰デコード (13B) よりも 3 倍高速です。
-
Lookahead デコード (13B) よりも 2 倍高速です。 メデューサデコードより(13B) 1.6 倍高速;
-
は、生成されたテキストの配布で通常のデコードと一致していることが証明でき、RTX 3090 でテストできます。
vLLM、DeepSpeed、Mamba、FlashAttendant、量子化、ハードウェア最適化などの他の並列テクノロジと組み合わせて使用できます。
自己回帰デコードを高速化する 1 つの方法は、投機的サンプリングです。この手法では、より小さなドラフト モデルを使用して、標準の自己回帰生成によって次の複数の単語を推測します。元の LLM は、これらの推測された単語を並行して検証します (検証に必要な前方パスは 1 つだけです)。ドラフト モデルが α ワードを正確に予測する場合、元の LLM の 1 回の順方向パスで α+1 ワードを生成できます。
この制限は EAGLE の開発にインスピレーションを与えました。 EAGLE は、元の LLM によって抽出されたコンテキスト特徴 (つまり、モデルの 2 番目の最上層によって出力された特徴ベクトル) を利用します。 EAGLE は次の第一原則に基づいて構築されています: 特徴ベクトル シーケンスは圧縮可能であるため、以前の特徴ベクトルに基づいて後続の特徴ベクトルを予測することが容易になります。 EAGLE は、自動回帰ヘッドと呼ばれる軽量プラグインをトレーニングします。このプラグインは、単語埋め込み層と連携して、現在の特徴シーケンスに基づいて、元のモデルの 2 番目の最上層から次の特徴を予測します。次に、元の LLM の凍結された分類頭部を使用して、次の単語が予測されます。特徴には単語シーケンスよりも多くの情報が含まれるため、特徴を回帰するタスクは単語を予測するタスクよりもはるかに簡単になります。要約すると、EAGLE は小さな自己回帰ヘッドを使用して特徴レベルで外挿し、次に凍結分類ヘッドを利用して予測単語シーケンスを生成します。 Speculative Sampling、Medusa、Lookahead などの同様の作業と同様に、EAGLE はシステム全体のスループットではなく、キューごとの推論のレイテンシーに焦点を当てています。 EAGLE - 大規模言語モデル生成の効率を高める方法
위 그림은 EAGLE과 표준 추측 샘플링, Medusa 및 Lookahead 간의 입력 및 출력 차이를 보여줍니다. 아래 그림은 EAGLE의 작업 흐름을 보여줍니다. 원래 LLM의 순방향 전달에서 EAGLE은 두 번째 최상위 계층에서 기능을 수집합니다. 자동회귀 헤드는 이러한 특징과 이전에 생성된 단어의 단어 임베딩을 입력으로 사용하고 다음 단어를 추측하기 시작합니다. 이어서, 고정 분류 헤드(LM Head)를 사용하여 다음 단어의 분포를 결정하고 EAGLE이 이 분포에서 샘플링할 수 있도록 합니다. EAGLE은 샘플링을 여러 번 반복함으로써 아래 그림의 오른쪽과 같이 트리형 생성 프로세스를 수행합니다. 이 예에서 EAGLE의 트리플 포워드 패스는 10개 단어로 구성된 트리를 "추측"했습니다. 
EAGLE은 경량 자동 회귀 헤드를 사용하여 원래 LLM의 기능을 예측합니다. 생성된 텍스트 분포의 일관성을 보장하기 위해 EAGLE은 예측된 트리 구조를 검증합니다. 이 확인 프로세스는 정방향 전달을 사용하여 완료할 수 있습니다. 이러한 예측과 검증의 순환을 통해 EAGLE은 텍스트 단어를 빠르게 생성할 수 있습니다. 자기회귀 머리를 훈련하는 데 드는 비용은 매우 적습니다. EAGLE은 70,000회 미만의 대화 라운드가 포함된 ShareGPT 데이터 세트를 사용하여 교육되었습니다. 자동회귀 헤드의 훈련 가능한 매개변수 수도 매우 적습니다. 위 이미지에서 파란색으로 표시된 것처럼 대부분의 구성요소가 동결되어 있습니다. 필요한 유일한 추가 훈련은 0.24B-0.99B 매개변수를 가진 단일 레이어 Transformer 구조인 자동회귀 헤드입니다. GPU 리소스가 제한된 경우에도 자동회귀 헤드를 훈련할 수 있습니다. 예를 들어, Vicuna 33B의 자동 회귀 회귀는 8카드 RTX 3090 서버에서 24시간 내에 학습될 수 있습니다. 특징을 예측하기 위해 단어 임베딩을 사용하는 이유는 무엇인가요? Medusa는 다음 단어, 다음 단어를 예측하기 위해 두 번째 상위 레이어의 기능만 사용합니다. Medusa와 달리 EAGLE은 예측을 위한 자동 회귀 헤드 입력 부분으로 현재 샘플링된 단어 임베딩도 동적으로 사용합니다. 이 추가 정보는 EAGLE이 샘플링 프로세스에서 불가피한 무작위성을 처리하는 데 도움이 됩니다. 프롬프트 단어가 "I"라고 가정하고 아래 이미지의 예를 살펴보세요. LLM은 "I" 뒤에 "am" 또는 "always"가 올 확률을 제공합니다. Medusa는 "am" 또는 "always"가 샘플링되는지 여부를 고려하지 않고 "I" 아래의 다음 단어가 나올 확률을 직접 예측합니다. 따라서 메두사의 목표는 "나"만 주어서 "나는" 또는 "나는 항상"에 대한 다음 단어를 예측하는 것입니다. 샘플링 프로세스의 무작위 특성으로 인해 Medusa에 대한 동일한 입력 "I"는 다음 단어 출력 "준비" 또는 "시작"이 다를 수 있으므로 입력과 출력 간의 일관된 매핑이 부족할 수 있습니다. 이와 대조적으로 EAGLE에 대한 입력에는 샘플링된 결과의 단어 임베딩이 포함되어 입력과 출력 간의 일관된 매핑을 보장합니다. 이러한 구별을 통해 EAGLE은 샘플링 프로세스에서 설정된 컨텍스트를 고려하여 후속 단어를 보다 정확하게 예측할 수 있습니다. 
추측 샘플링, Lookahead 및 Medusa와 같은 다른 추측 검증 프레임워크와 달리 EAGLE은 "추측 단어" 단계에서 트리형 생성 구조를 채택하므로 더 높은 디코딩 효율을 달성합니다. 그림에서 볼 수 있듯이 표준 추측 샘플링과 Lookahead의 생성 프로세스는 선형 또는 체인입니다. 추측 단계에서는 컨텍스트를 구성할 수 없기 때문에 Medusa의 방법은 데카르트 곱을 통해 트리를 생성하여 인접한 레이어 간에 완전히 연결된 그래프를 생성합니다. 이 접근 방식은 종종 "나는 시작합니다"와 같은 의미 없는 조합을 초래합니다. 이와 대조적으로 EAGLE은 더 희박한 트리 구조를 생성합니다. 이 희소 트리 구조는 의미 없는 시퀀스의 형성을 방지하고 보다 합리적인 단어 조합에 컴퓨팅 리소스를 집중시킵니다. 
표준 추측 샘플링 방법은 "단어 추측" 과정에서 분포의 일관성을 유지합니다. 트리형 단어 추측 시나리오에 적응하기 위해 EAGLE은 이 방법을 다중 라운드 재귀 형식으로 확장합니다. 여러 라운드의 추측 샘플링에 대한 의사 코드가 아래에 나와 있습니다. 트리 생성 과정에서 EAGLE은 샘플링된 각 단어에 해당하는 확률을 기록합니다. EAGLE은 여러 라운드의 추측 샘플링을 통해 각 단어의 최종 생성된 분포가 원래 LLM의 분포와 일치하는지 확인합니다. 
下图展示了 EAGLE 在 Vicuna 33B 上关于不同任务中的加速效果。涉及大量固定模板的 “编程”(coding)任务显示出最佳的加速性能。
欢迎大家体验 EAGLE,并通过 GitHub issue 反馈建议:https://github.com/SafeAILab/EAGLE/issues위 내용은 대형 모델의 추론 효율성이 손실 없이 3배 향상되었습니다. 워털루 대학교, 북경 대학교 및 기타 기관에서 EAGLE을 출시했습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!


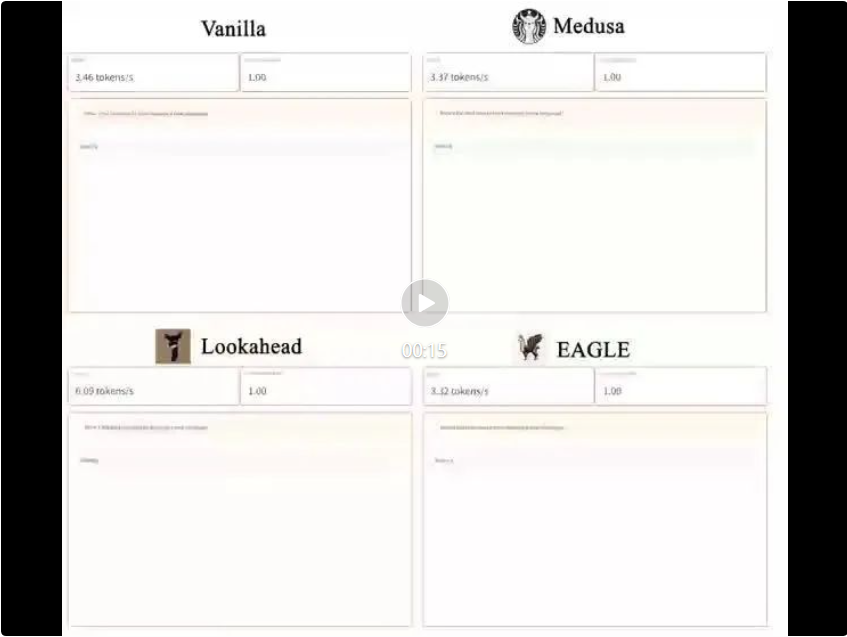 推測的サンプリングでは、ドラフト モデルのタスクは、現在の単語シーケンスに基づいて次の単語を予測することです。パラメーターの数が大幅に少ないモデルを使用してこのタスクを実行することは非常に困難であり、最適とはいえない結果が得られることがよくあります。さらに、標準的な投機的サンプリング アプローチのドラフト モデルは、元の LLM によって抽出された豊富な意味情報を利用せずに次の単語を独立して予測するため、潜在的に非効率になります。
推測的サンプリングでは、ドラフト モデルのタスクは、現在の単語シーケンスに基づいて次の単語を予測することです。パラメーターの数が大幅に少ないモデルを使用してこのタスクを実行することは非常に困難であり、最適とはいえない結果が得られることがよくあります。さらに、標準的な投機的サンプリング アプローチのドラフト モデルは、元の LLM によって抽出された豊富な意味情報を利用せずに次の単語を独立して予測するため、潜在的に非効率になります。