
오픈 소스 3D 의료용 대형 모델 SAT는 497개의 오가노이드를 지원하며 72 nnU-Net을 초과하는 성능을 가지고 있습니다. 이는 Shanghai Jiao Tong University 팀에서 출시했습니다.

- 王林원래의
- 2024-07-12 10:52:01649검색

저자 | 상하이 교통대학교, 상하이 인공지능 연구소
편집자 | ScienceAI
최근 상하이 교통대학교와 상하이 인공지능 연구소의 공동팀은 대규모 3D 의료 영상 분할 모델 SAT(Segment Anything in)를 출시했습니다. 텍스트 프롬프트를 기반으로 한 3D 의료 이미지(CT, MR, PET)에 대한 방사선 스캔(텍스트 프롬프트 기반 방사선 스캔)을 통해 인체의 497개 유형의 장기/병변에 대한 보편적인 분할을 달성합니다. 모든 데이터, 코드 및 모델은 오픈 소스입니다.

문서 링크:https://arxiv.org/abs/2312.17183
코드 링크:https://github.com/zhaoziheng/SAT
데이터 링크:https://github .com/zhaoziheng/SAT-DS/
연구 배경
의료 영상 분할은 진단, 수술 계획, 질병 모니터링 등 일련의 임상 작업에서 중요한 역할을 합니다. 그러나 전통적인 연구에서는 각 특정 세분화 작업에 대해 "전용" 모델을 훈련하므로 각 "전용" 모델의 적용 범위가 상대적으로 제한되어 있으며 광범위한 의료 세분화 요구 사항을 효율적이고 편리하게 충족할 수 없습니다.
동시에 대형 언어 모델은 최근 의료 분야에서 큰 성공을 거두고 있으며, 일반 의료 인공 지능의 발전을 더욱 촉진하기 위해서는 언어와 위치 파악 기능을 연결할 수 있는 의료 세분화 도구를 구축하는 것이 필요해졌습니다.
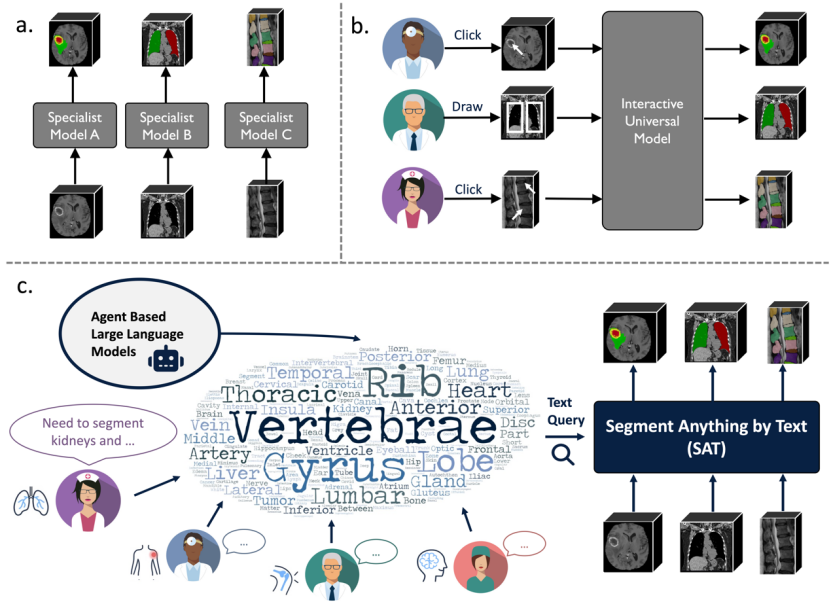
이러한 문제를 극복하기 위해 Shanghai Jiao Tong University 및 Shanghai Artificial Intelligence Laboratory의 연구원은 텍스트 기반 SAT(Segment Anything in Radiology Scans)라는 텍스트 프롬프트를 사용하고 지식 향상을 기반으로 하는 3D 의료 이미지에 대한 최초의 일반 분할 모델을 제안했습니다. 프롬프트), 다음과 같은 세 가지 주요 기여를 했습니다.
1. 이 연구는 인체 해부학 지식을 텍스트 인코더에 주입하여 해부학적 용어를 정확하게 인코딩하고 방사선 이미지에 대한 일반적인 의료 분할 모델을 구현하는 방법을 최초로 탐구한 것입니다. .
2. 이 연구는 6K+ 인체 해부학 개념을 포함하는 최초의 다중 모드 의학 지식 그래프를 구축합니다. 동시에 SAT-DS라는 최대 규모의 3D 의료 영상 분할 데이터 세트가 구축되었습니다. 이 데이터 세트는 72개의 공개 데이터 세트, CT, MR 및 PET 양식의 22K+ 이미지, 인체를 포괄하는 302K+ 분할 주석을 통합합니다. 8개 주요 부분으로 구성된 497개의 분할 대상.
3 이 연구에서는 SAT-DS를 기반으로 SAT-Pro(447M 매개변수)와 SAT-Nano(110M 매개변수)라는 두 가지 크기의 모델을 훈련하고 SAT의 가치를 여러 각도에서 검증하기 위한 실험을 설계했습니다. 성능은 72개의 nnU-Nets 전문가 모델과 동일하며(매개변수는 각 데이터 세트에서 개별적으로 조정 및 최적화되며, 총 약 2.2B 매개변수) SAT를 사용할 수 있는 도메인 외부 데이터에 대해 더 강력한 일반화 능력을 보여줍니다. 대규모 데이터에 대해 사전 훈련된 기본 분할 모델은 다운스트림 미세 조정을 통해 특정 작업으로 전송될 때 nnU-Nets보다 더 나은 성능을 나타낼 수 있습니다. 또한 상자 프롬프트 기반 MedSAM과 비교하여 SAT는 더 정확하고 텍스트 프롬프트를 기반으로 하는 정확한 성능 마지막으로 도메인 외부의 임상 데이터에서 연구팀은 SAT가 대규모 언어 모델의 프록시 도구로 사용될 수 있음을 시연하여 후자에 작업을 현지화하고 분할할 수 있는 기능을 직접 제공합니다. 보고서 생성과 같은.
다음은 데이터, 모델, 실험 결과의 세 가지 측면에서 원문의 세부 사항을 소개합니다.
데이터 구성
다중 모드 지식 그래프: 해부학 용어의 정확한 인코딩을 달성하기 위해 연구팀은 먼저 6K+ 인체 해부학 개념이 포함된 다중 모드 지식 그래프를 수집했습니다. 출처 :
1. UMLS(Unified Medical Language System)는 미국 국립의학도서관에서 구축한 생물의학 사전입니다. 연구팀은 약 230,000개의 생물의학 개념과 정의는 물론 100만 개 이상의 상호 관계를 포괄하는 지식 그래프를 추출했습니다.
2. 인터넷의 권위 있는 해부학 지식. 연구팀은 검색 강화 대형 언어 모델의 도움으로 6,502개의 인체 해부학 개념을 선별하고 인터넷에서 관련 정보를 검색하여 6,000개 이상의 개념과 정의, 해부학적 구조 간의 38,000개 이상의 관계를 포괄하는 지식 맵을 얻었습니다.
3. 공개 세분화 데이터세트. 연구팀은 대규모 공개 3차원 의료영상 분할 데이터 세트를 수집하고, 해부학적 개념(카테고리 라벨)을 통해 분할된 영역을 위에서 언급한 텍스트 지식베이스의 지식과 연결해 시각적 지식 비교를 제공했다.
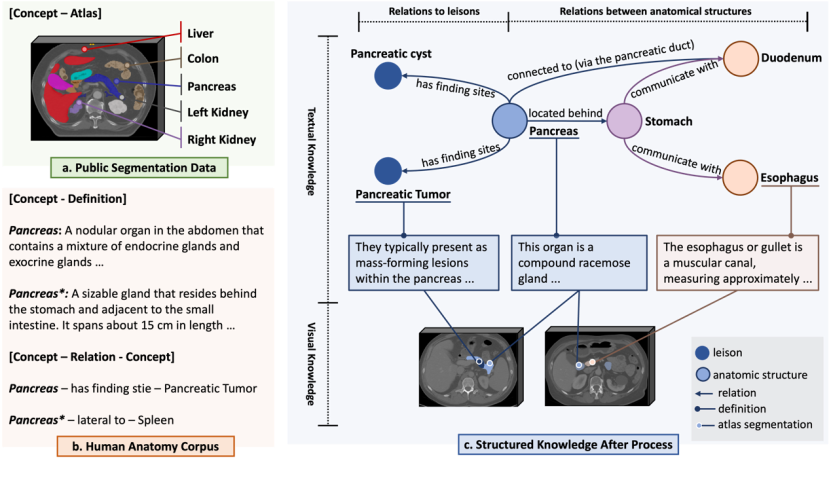
SAT-DS: 범용 분할 모델을 훈련하기 위해 연구팀은 해당 분야 최대 규모의 3D 의료 영상 분할 데이터 컬렉션인 SAT-DS를 구축했습니다. 특히, CT, MR, PET의 세 가지 양식에서 총 22,186개의 3D 이미지, 302,033개의 분할 주석, 인체의 8개 주요 영역을 포괄하는 497개의 분할을 포함하여 72개의 다양한 공개 분할 데이터 세트가 수집 및 구성되었습니다. 해부학적 구조 또는 병변).
이종 데이터 세트 간의 차이를 최소화하기 위해 연구팀은 서로 다른 데이터 세트 간의 방향, 복셀 간격, 회색 값 및 기타 이미지 속성을 표준화하고 통일된 해부학 용어 시스템 분할 범주를 사용하여 서로 다른 데이터 세트의 이름을 지정했습니다.

그림 3: SAT-DS는 인체의 8개 주요 영역에서 총 497개의 분할 범주를 포괄하는 대규모의 다양한 3D 의료 영상 분할 데이터 컬렉션입니다.
모델 아키텍처
지식 주입: 해부 용어를 정확하게 인코딩할 수 있는 프롬프트 인코더를 구축하기 위해 연구팀은 먼저 대조 학습을 사용하여 텍스트 인코더에 다중 모드 해부학 지식을 주입했습니다.
아래 그림 a와 같이 해부학적 개념을 사용하여 다중 모드 지식을 쌍으로 연결한 다음 시각적 인코더와 텍스트 인코더를 사용하여 각각 시각적 지식과 텍스트 지식을 인코딩하고 특징을 대비를 통해 시각적으로 정렬하여 학습합니다. 공간에 대한 텍스트 지식과 해부학적 구조 간의 관계 구성을 통해 해부학적 구조의 특징을 이해함으로써 해부학적 개념의 더 나은 인코딩을 배우고 시각적 분할 모델 훈련을 안내하는 단서 역할을 합니다.
텍스트 프롬프트 기반 범용 분할: 연구팀은 아래 그림 b와 같이 텍스트 인코더, 시각적 인코더, 시각적 디코더 및 프롬프트 디코더를 포함하여 텍스트 프롬프트 기반 범용 분할 모델 프레임워크를 추가로 설계했습니다.
그 중 동일한 해부학적 구조라도 이미지에 따라 차이가 있다는 점을 고려하여 큐 디코더(쿼리 디코더)는 시각적 인코더에서 출력되는 이미지 특징을 사용하여 해부학적 개념 특징, 즉 분할 큐를 강화합니다. 마지막으로, 분할 예측 결과를 얻기 위해 분할 힌트와 시각적 디코더에서 출력된 픽셀 수준 특징 사이의 내적을 계산합니다.

모델 평가
이 연구에서는 SAT를 두 가지 대표적인 방법인 "전문" 모델 nnU-Nets와 대화형 일반 분할 모델 MedSAM과 비교합니다. 평가에는 도메인 내 데이터 세트 테스트(포괄적인 세분화 성능)와 제로샷 도메인 외부 데이터 세트 테스트(센터 간 데이터 마이그레이션 기능)의 두 가지 측면이 포함됩니다. 평가 결과는 데이터 세트, 카테고리 및 인체 영역:
-
카테고리: 서로 다른 데이터 세트 간의 동일한 카테고리의 분할 결과가 요약되고 평균화됩니다.
영역: 카테고리 결과를 기준으로 동일한 인체 해부학 영역 내의 카테고리 결과는 다음과 같습니다.
데이터 집합: 기존 분할 모델 평가 방법, 동일한 데이터 집합 내의 분할 결과를 평균화합니다.
전용 모델 nnU-Nets
을 사용한 비교 실험 nnU-Nets의 성능에 대해 연구에서는 nnU-Nets가 세트에 대해 훈련된 개별 데이터에 대해 별도의 데이터 분석을 수행했으며 구체적인 설정은 다음과 같습니다.
1. SAT-DS의 데이터 세트는 테스트 및 비교에 사용됩니다. SAT의 경우 72개의 훈련 세트의 합이 훈련에 사용되고 72개의 테스트 세트에서 테스트됩니다. nnU-Net의 경우 각 테스트 세트에 대한 72개의 nnU-Net의 결과가 전체적으로 요약됩니다.
2. Out-of-domain 테스트에서는 72개의 데이터 세트를 더 분할하고 49개의 데이터 세트(SAT-DS-Nano라고 함)로 구성된 트레이닝 세트를 사용하여 SAT-Nano 및 제로샷 테스트를 학습했습니다. nnU-Net의 경우 49개의 nnU-Net을 사용하여 10개의 도메인 외부 테스트 세트를 테스트하고 그 결과를 요약합니다.

In-domain 테스트 결과: 표 1에서 볼 수 있듯이 SAT-Pro는 In-domain 테스트에서 72 nnU-Nets에 매우 근접한 성능을 보였으며 여러 영역에서 nnU-Nets를 능가했습니다. SAT는 단 하나의 모델로 72개의 분할 작업을 완료할 수 있으며 모델 크기는 nnU-Net 세트보다 훨씬 작습니다(아래 그림 c 참조).
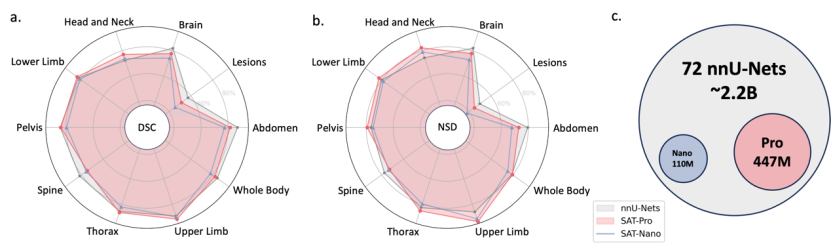
미세 조정 마이그레이션 테스트 결과: 이 연구에서는 SAT-Pro-Ft라는 이름으로 별도로 미세 조정한 후 각 데이터 세트에 대해 SAT-Pro를 추가로 테스트했습니다. 표 1에서 볼 수 있듯이 SAT-Pro-Ft는 SAT-Pro에 비해 모든 영역에서 상당한 성능 향상을 보이며 전체 성능에서 nnU-Nets를 능가합니다.
Out-of-domain 테스트 결과: 표 2에서 볼 수 있듯이 SAT-Nano는 10개 데이터 세트의 20개 지표 중 19개 지표에서 nnU-Nets를 능가하여 전반적으로 강력한 마이그레이션 능력을 보여주었습니다.
표 2: SAT-Nano, nnU-Nets 및 MedSAM 간의 도메인 외부 테스트 비교 결과는 데이터 세트 단위로 표시됩니다.

Interactive Segmentation 모델 MedSAM을 이용한 비교 실험
본 연구에서는 테스트 및 SAT 비교를 위해 MedSAM의 공개 체크포인트를 직접 사용했습니다.
1. 데이터 비교를 위해 MedSAM 교육에 사용된 32개의 데이터 세트를 추가로 선별했습니다.
2. 도메인 외부 테스트에서는 MedSAM 교육에 사용되지 않은 5개의 데이터 세트가 비교를 위해 선별되었습니다.
MedSAM의 경우 MedSAM(Tight)으로 기록된 지상 진실 분할을 포함하는 가장 작은 직사각형(Oracle Box)을 사용하고 MedSAM(Loose)으로 기록된 Oracle Box를 기반으로 무작위 오프셋을 추가하는 두 가지 다른 Box 프롬프트를 고려하십시오. 동시에 Oracle Box의 효과를 예측으로 직접 테스트해 보세요. SAT의 경우 nnU-Nets 비교 실험의 모델은 재교육 없이 이러한 데이터 세트를 테스트하는 데 직접 사용됩니다.
도메인 내 테스트 결과:표 3에서 볼 수 있듯이 거의 모든 영역에서 SAT-Pro가 MedSAM보다 우수한 성능을 발휘하며, 전반적인 성능은 SAT-Pro 및 SAT-Nano가 MedSAM보다 우수합니다. SAT-Pro는 병변에 대해 MedSAM보다 성능이 떨어지지만 Oracle Box 자체는 DSC에서 MedSAM을 능가할 정도로 예측에 따라 병변에 대해 충분히 우수한 성능을 발휘합니다. 이는 병변 분할에서 MedSAM의 우수한 성능이 Box에서 촉발된 강력한 사전 정보에서 비롯될 가능성이 있음을 나타냅니다.
표 3: SAT-Pro, SAT-Nano 및 MedSAM의 도메인 내 테스트 비교, 결과는 영역 또는 병변 단위로 통합됩니다.

질적 비교: 그림 6은 SAT와 MedSAM을 추가로 비교하기 위해 시각적 디스플레이에 대한 도메인 내 테스트 결과에서 두 가지 일반적인 예를 선택합니다. 그림 6에서 볼 수 있듯이 심근 분할에서 Box 프롬프트는 심근과 심근에 싸인 심실을 구별하기 어렵기 때문에 MedSAM도 실수로 두 개를 함께 분할하여 Box 프롬프트가 유사한 상태임을 알 수 있습니다. 복잡한 공간 관계는 모호함을 가지기 쉽고 부정확한 분할로 이어집니다.
반면에 텍스트 프롬프트(해부구조의 이름을 직접 입력) 기반의 SAT는 심근과 심실을 정확하게 구분할 수 있습니다. 또한 그림 6의 장 종양 분할에서 볼 수 있듯이 Oracle Box는 이미 병변 대상에 대한 좋은 예측 결과인 반면, MedSAM의 분할 결과는 얻은 Box 프롬프트보다 좋지 않을 수 있습니다.
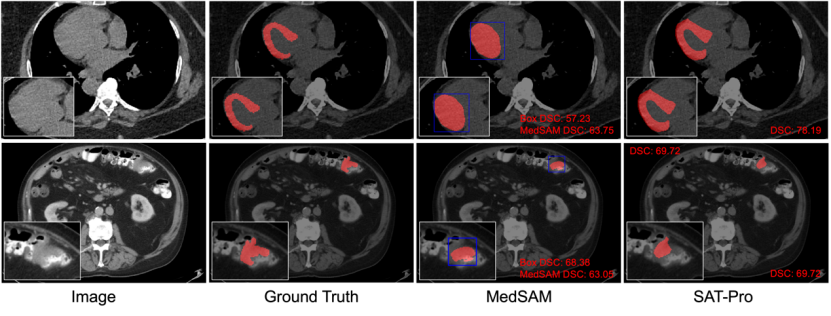
그림 6: SAT-Pro와 MedSAM(Tight)의 정성적 비교. 그 중 MedSAM은 Oracle Box를 프롬프트로 사용하고 있으며 Box는 파란색으로 표시되어 있습니다. 첫 번째 행은 심근 분할의 예를 보여주고, 두 번째 행은 장 종양 분할의 예를 보여줍니다.
Out-of-domain 테스트 결과: 표 2에서 볼 수 있듯이 MedSAM(Tight)과 비교하여 SAT-Nano는 5개 데이터 세트의 지표 10개 중 5개에서 MedSAM을 능가했습니다. MedSAM(느슨한)은 모든 지표에서 명백한 성능 저하를 보이며, 이는 MedSAM이 사용자가 입력한 상자 프롬프트의 오프셋에 더 민감하다는 것을 나타냅니다.
Ablation 실험
SAT를 설계할 때 시각적 백본 네트워크와 텍스트 인코더는 두 가지 핵심 부분입니다. 이 연구에서는 SAT 프레임워크에서 다양한 시각적 네트워크 구조나 텍스트 인코더를 사용하고 이들의 영향을 탐색하기 위한 일반적인 절제 실험을 시도합니다.
실험 비용을 절약하기 위해 절제 실험의 모든 SAT 모델 훈련 및 테스트는 13303개의 3D 이미지, 151461개의 분할 주석 및 429개의 분할 범주를 포함하는 49개의 데이터 세트가 포함된 SAT-DS-Nano에서 수행됩니다.
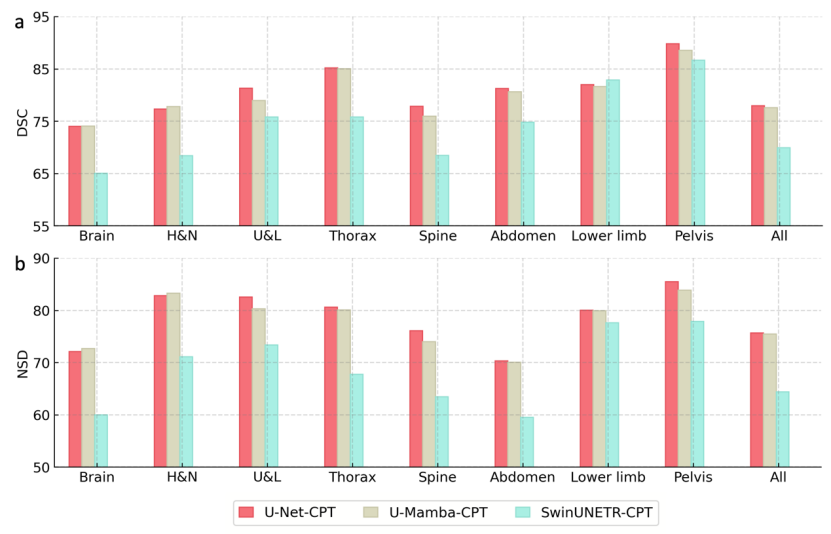
시각적 백본 네트워크: SAT-Nano 프레임워크에서 이 연구에서는 비교를 위해 세 가지 주류 분할 네트워크 구조, 즉 U-Net(110M 매개변수), SwinUNETR(107M 매개변수) 및 U-Mamba(114M 매개변수)를 선택했습니다. 공정한 비교를 위해 이 절제 실험에서 이를 제어하는 매개변수 양은 대략 유사합니다. 동시에 오버헤드를 계산하기 위해 지식 주입 단계를 생략하고 MedCPT를 직접 사용한다. 일련의 의료 언어 작업) 텍스트 인코더가 힌트를 생성합니다. 세 가지 변종은 각각 U-Net-CPT, SwinUNETR-CPT 및 U-Mamba-CPT로 표시됩니다.
그림 7에서 볼 수 있듯이 U-Net과 U-Mamba를 시각적 백본 네트워크로 사용하면 최종 분할 성능이 상대적으로 유사하며 U-Net은 U-Mamba보다 약간 더 나은 반면 SwinUNETR을 사용할 때는 분할 성능이 더 좋습니다. 쇠퇴가 훨씬 더 좋습니다. 마지막으로 연구팀은 SAT의 시각적 백본 네트워크로 U-Net을 선택했습니다.
텍스트 인코더: 본 연구에서는 SAT-Nano 프레임워크 하에서 비교를 위해 세 가지 대표적인 텍스트 인코더를 선택했습니다. 위에서 제안한 지식 주입 방법을 사용하여 훈련된 텍스트 인코더(우리의 것으로 표시), 의료용 텍스트 인코더 MedCPT를 사용하며, 의료 데이터에 대해 Fine-tuned되지 않은 텍스트 인코더 BERT-base를 사용합니다.
공정성을 위해 이번 절제 실험에서는 시각적 네트워크로 U-Net을 일률적으로 사용합니다. 세 가지 변형은 각각 U-Net-Ours, U-Net-CPT 및 U-Net-BB로 표시됩니다. 그림 8에서 볼 수 있듯이, 전체적으로 MedCPT를 사용하는 것이 BERT 기반을 사용하는 것에 비해 분할 성능이 약간 향상되었으며, 이는 도메인 지식이 좋은 분할 팁을 제공하는 데 도움이 됨을 나타내며, 본 연구에서 제안한 텍스트 인코더를 사용하면 가장 좋은 성능을 보였습니다. 이는 모든 범주에서 달성되었으며, 이는 다중 모드 인체 해부학 지식 기반 구축 및 지식 주입이 분할 모델에 크게 도움이 된다는 것을 나타냅니다.

롱테일 분포는 분할된 데이터 세트의 분명한 특징입니다. 연구팀은 도 9의 a, b와 같이 ablation 실험에 사용된 SAT-DS-Nano에서 429개 카테고리의 주석 수 분포를 조사하였다. Annotation 수가 가장 많은 10개 카테고리(상위 2.33%)를 Head 클래스로 정의하고, Annotation 수가 가장 적은 150개 카테고리(최후 34.97%)를 Tail 클래스로 정의하면, 테일 클래스에 대한 주석은 전체 주석 수의 3.25%만을 차지합니다.
이 연구에서는 텍스트 인코더가 롱테일 분포에서 다양한 범주의 분할 결과에 미치는 영향을 더 자세히 조사합니다. 그림 9c에서 볼 수 있듯이, 연구팀이 제안한 인코더는 머리, 꼬리, 중간 범주에서 최고의 성능을 달성했으며, 머리 범주보다 꼬리 범주의 개선이 더 뚜렷이 나타났습니다. 동시에 MedCPT는 헤드 클래스에서는 BERT 기반보다 약간 낮은 성능을 발휘하지만 테일 클래스에서는 더 나은 성능을 발휘합니다. 이러한 결과는 도메인 지식, 특히 다중 모드 인체 해부학 지식의 주입이 롱테일 카테고리 분할에 크게 도움이 된다는 것을 보여줍니다.

대규모 언어 모델과 결합
SAT는 텍스트 프롬프트를 기반으로 분할할 수 있으므로 대규모 언어 모델의 프록시 도구로 직접 사용하여 분할 기능을 제공할 수 있습니다. 적용 시나리오를 입증하기 위해 연구팀은 4개의 다양한 실제 임상 데이터를 선택하고 GPT4를 사용하여 보고서에서 분할 대상을 추출하고 제로 샷 분할을 위해 SAT를 호출했습니다. 결과는 그림 10에 나와 있습니다.
보시다시피 GPT-4는 보고서에서 중요한 해부학적 구조를 매우 잘 감지할 수 있으며 SAT를 호출하여 데이터를 미세 조정하지 않고도 실제 임상 이미지에서 이를 매우 잘 분할할 수 있습니다.

연구 가치
텍스트 프롬프트 기반의 3D 의료 영상의 최초 대규모 일반 분할 모델로서 SAT의 가치는 여러 측면에서 반영됩니다.
SAT는 효율적이고 유연한 범용 분할을 구축합니다. SAT-Pro는 하나의 모델만 사용하여 광범위한 분할 작업에서 72 nnU-Net과 비슷한 성능을 보여주며 모델 매개변수의 양이 더 적습니다. 이는 일련의 특수 모델의 구성, 교육 및 배포가 필요한 전통적인 의료 세분화 방법과 비교할 때 일반 세분화 모델인 SAT-Pro가 더 유연하고 효율적인 솔루션임을 보여줍니다. 동시에 연구팀은 SAT-Pro가 지역 외부 데이터에 대해 더 나은 일반화 성능을 갖고 있으며 센터 간 마이그레이션과 같은 임상 요구를 더 잘 충족할 수 있음을 입증했습니다.
SAT는 대규모 분할 데이터 사전 학습을 기반으로 한 기본 모델입니다. SAT-Pro는 대규모 분할 데이터 세트에 대해 학습한 후 미세 분할을 통해 특정 데이터 세트로 전송하면 상당한 성능 향상을 보여줍니다. nnU-Nets보다 전반적으로 더 나은 성능을 발휘합니다. 이는 SAT가 미세 조정된 전송을 통해 특정 작업에서 더 나은 성능을 발휘할 수 있는 강력한 기본 분할 모델로 간주될 수 있음을 나타냅니다. 이를 통해 범용 분할과 전문 분할의 임상 요구 사항의 균형을 맞춥니다.
SAT는 텍스트 프롬프트를 기반으로 정확하고 강력한 분할을 달성합니다. 상자 프롬프트를 기반으로 한 대화형 분할 모델과 비교하여 텍스트 프롬프트 기반 SAT는 더 정확하고 프롬프트가 강력한 분할 결과를 얻을 수 있으며 사용자를 절약할 수 있습니다. 상자를 그리는 데 걸리는 시간을 단축하여 자동 및 배치 지원 범용 분할을 달성합니다.
SAT는 대규모 언어 모델을 위한 프록시 도구로 사용될 수 있습니다. 연구팀은 SAT가 대규모 언어 모델과 원활하게 연결될 수 있으며 텍스트를 브리지로 사용하여 모든 언어 모델에 대한 분할 및 위치 지정 기능을 직접 제공할 수 있음을 실제 임상 데이터에서 시연했습니다. 대규모 언어 모델. 이는 일반 의료 인공 지능의 개발을 더욱 촉진하는 데 큰 가치가 있습니다.
모델 크기가 세분화에 미치는 영향: SAT-Nano와 SAT-Pro라는 서로 다른 크기의 두 가지 모델을 훈련함으로써 이 연구에서는 SAT-Pro가 도메인 내 테스트에서 SAT-Nano에 비해 크게 개선되었음을 관찰했습니다. . 이는 대규모 데이터 세트에 대한 일반 분할 모델을 훈련할 때 확장 법칙이 여전히 적용된다는 것을 의미합니다.
분할에 대한 도메인 지식의 영향: 연구팀은 최초의 다중 모드 인체 해부학 지식 기반을 제안하고 지식 강화를 사용하여 일반 분할 모델, 특히 롱테일 카테고리의 분할 성능을 향상시키는 방법을 연구했습니다. 분할 주석, 특히 롱테일 카테고리에 대한 주석이 상대적으로 드물다는 점을 고려하면, 이 탐색은 일반적인 분할 모델을 구축하는 데 큰 의미가 있습니다.
위 내용은 오픈 소스 3D 의료용 대형 모델 SAT는 497개의 오가노이드를 지원하며 72 nnU-Net을 초과하는 성능을 가지고 있습니다. 이는 Shanghai Jiao Tong University 팀에서 출시했습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!