
효율성과 경제성에 중점을 둔 Google의 '성실한 작업', Gemma2의 오픈소스 9B 및 27B 버전!

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB원래의
- 2024-06-29 00:59:211150검색
성능이 두 배인 Gemma 2, 같은 레벨로 Llama 3를 플레이하는 방법은 무엇입니까?


뛰어난 성능: Gemma 2 27B 모델은 크기가 2배 이상인 모델과 경쟁하더라도 해당 볼륨 범주에서 최고의 성능을 제공합니다. 9B Gemma 2 모델도 해당 크기 범주에서 좋은 성능을 발휘했으며 Llama 3 8B 및 기타 유사한 개방형 모델보다 성능이 뛰어났습니다. 고효율, 저비용: 27B Gemma 2 모델은 고성능을 유지하면서 단일 Google Cloud TPU 호스트, NVIDIA A100 80GB Tensor Core GPU 또는 NVIDIA H100 Tensor Core GPU에서 최대 정밀도로 효율적으로 추론을 실행하도록 설계되었습니다. 비용을 획기적으로 절감합니다. 이를 통해 AI 배포가 더욱 편리하고 저렴해졌습니다. 초고속 추론: Gemma 2는 강력한 게임용 노트북, 고급 데스크톱, 클라우드 기반 설정 등 다양한 하드웨어에서 놀라운 속도로 실행되도록 최적화되었습니다. 사용자는 Google AI Studio에서 최대 정밀도로 Gemma 2를 실행하거나, CPU에서 Gemma.cpp의 양자화된 버전을 사용하여 로컬 성능을 잠금 해제하거나, Hugging Face Transformers를 통해 NVIDIA RTX 또는 GeForce RTX를 사용하는 가정용 컴퓨터에서 사용해 볼 수 있습니다.

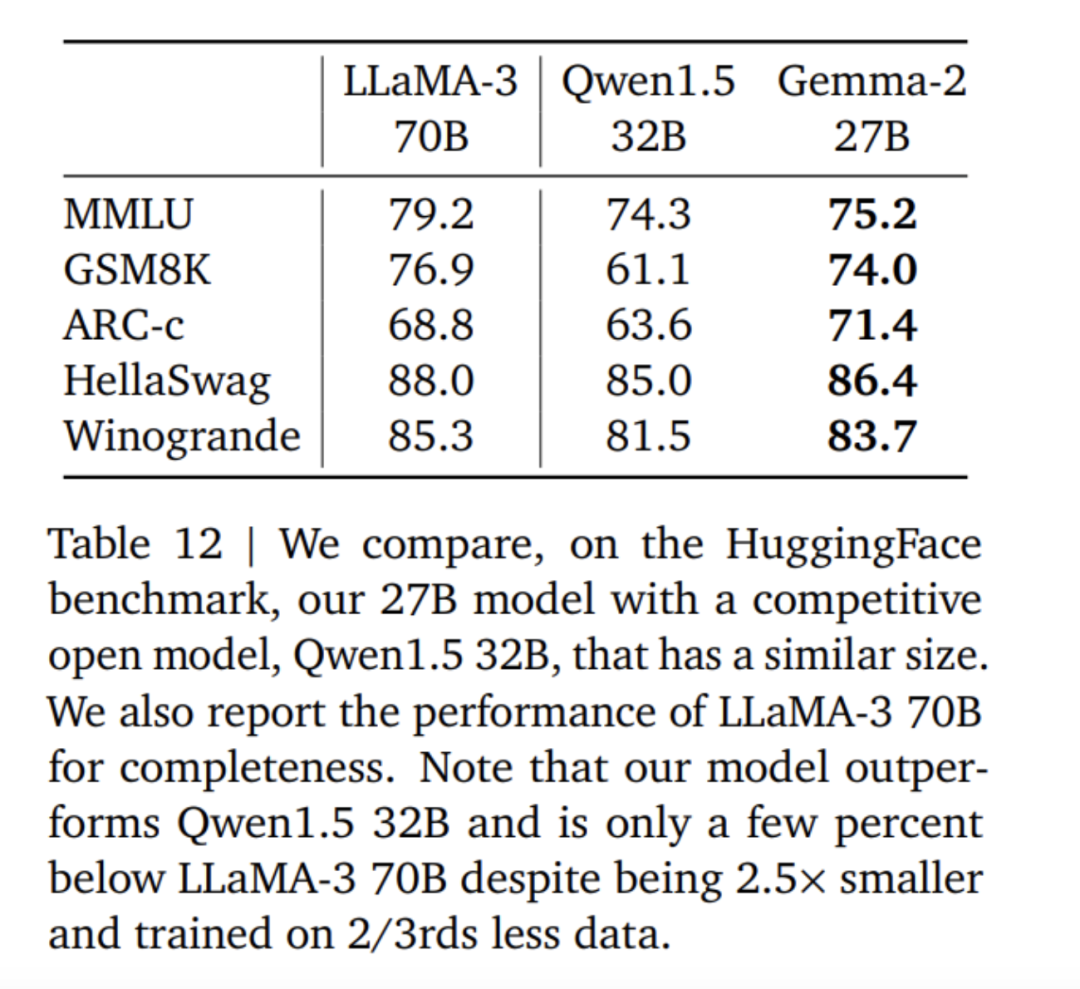
위는 Gemma2, Llama3 및 Grok-1의 점수 데이터 비교입니다.
사실 다양한 점수 데이터로 판단하면 오픈소스 9B 대형 모델의 장점은 특별히 뚜렷하지 않습니다. 거의 한 달 전 Zhipu AI가 오픈소스로 공개한 국내 대형 모델 GLM-4-9B는 훨씬 더 많은 장점을 가지고 있습니다.

개방성과 접근성: 원래 Gemma 모델과 마찬가지로 Gemma 2를 사용하면 개발자와 연구원이 혁신을 공유하고 상용화할 수 있습니다. 광범위한 프레임워크 호환성: Gemma 2는 Hugging Face Transformers와 같은 주요 AI 프레임워크는 물론 Keras 3.0, vLLM, Gemma.cpp, Llama.cpp 및 Ollama를 통해 기본적으로 지원되는 JAX, PyTorch 및 TensorFlow와도 호환됩니다. 사용자가 선호하는 도구 및 워크플로우와 쉽게 통합됩니다. 또한 Gemma는 NVIDIA TensorRT-LLM으로 최적화되었으며 NVIDIA 가속 인프라에서 실행되거나 NVIDIA NIM 추론 마이크로서비스로 실행될 수 있으며 향후 NVIDIA의 NeMo에도 최적화될 예정이며 Keras 및 Hugging Face를 사용하여 미세 조정할 수 있습니다. 또한 Google은 미세 조정 기능을 적극적으로 업그레이드하고 있습니다. 간편한 배포: 다음 달부터 Google Cloud 고객은 Vertex AI에서 Gemma 2를 쉽게 배포하고 관리할 수 있습니다.
최신 블로그에서 Google은 모든 개발자에게 Gemini 1.5 Pro의 200만 토큰 컨텍스트 창 액세스를 공개했다고 발표했습니다. 그러나 컨텍스트 창이 증가하면 입력 비용도 증가할 수 있습니다. 개발자가 동일한 토큰을 사용하여 여러 프롬프트 작업의 비용을 줄일 수 있도록 Google은 Gemini 1.5 Pro 및 1.5 Flash용 Gemini API에서 컨텍스트 캐싱 기능을 신중하게 출시했습니다. 수학이나 데이터 추론을 처리할 때 정확성을 높이기 위해 대규모 언어 모델이 코드를 생성하고 실행해야 하는 문제를 해결하기 위해 Google은 Gemini 1.5 Pro 및 1.5 Flash에서 코드 실행을 활성화했습니다. 활성화되면 모델은 Python 코드를 동적으로 생성 및 실행하고 원하는 최종 출력이 달성될 때까지 결과에서 반복적으로 학습할 수 있습니다. 실행 샌드박스는 인터넷에 연결되지 않으며 일부 숫자 라이브러리와 함께 표준으로 제공됩니다. 개발자는 모델의 출력 토큰을 기준으로만 비용을 청구하면 됩니다. Google이 모델 기능의 한 단계로 코드 실행을 도입한 것은 이번이 처음입니다. 현재 Google AI Studio의 Gemini API 및 고급 설정을 통해 사용할 수 있습니다. Google은 API 키를 통해 Gemini 모델을 통합하든 개방형 모델 Gemma 2를 사용하든 관계없이 모든 개발자가 AI에 액세스할 수 있도록 하고자 합니다. 개발자가 Gemma 2 모델을 활용할 수 있도록 Google 팀은 Google AI Studio에서 해당 모델을 실험할 수 있도록 할 것입니다.

문서 주소: https://storage.googleapis.com/deepmind-media/gemma/gemma-2-report.pdf 블로그 주소: https://blog.google/ technology/developers/google-gemma-2/

로컬 슬라이딩 윈도우와 글로벌 관심. 연구팀은 다른 모든 계층에서 로컬 슬라이딩 윈도우 관심과 글로벌 관심을 번갈아 가며 사용했습니다. 로컬 어텐션 레이어의 슬라이딩 윈도우 크기는 4096 토큰으로 설정되고, 글로벌 어텐션 레이어의 범위는 8192 토큰으로 설정됩니다. 로짓 소프트 캡. 연구팀은 Gemini 1.5의 방법에 따라 각 attention 레이어와 최종 레이어에서 로짓 값이 -soft_cap과 +soft_cap 사이에 유지되도록 로짓을 제한했다. 9B와 27B 모델에 대해 연구팀은 관심의 로그 상한을 50.0으로, 최종 로그 상한을 30.0으로 설정했습니다. 출판 당시 주의 로짓 소프트 캡핑은 일반적인 FlashAttention 구현과 호환되지 않으므로 FlashAttention을 사용하는 라이브러리에서 이 기능을 제거했습니다. 연구팀은 Attention Logit Soft Capping 유무에 관계없이 모델 생성에 대한 절제 실험을 수행한 결과, 대부분의 사전 훈련 및 사후 평가에서 생성 품질이 거의 영향을 받지 않는다는 것을 발견했습니다. 이 백서의 모든 평가는 주의 로짓 소프트 캡핑을 포함한 전체 모델 아키텍처를 사용합니다. 그러나 일부 다운스트림 성능은 이러한 제거로 인해 여전히 약간의 영향을 받을 수 있습니다. 사후 규범과 사전 규범에는 RMSNorm을 사용하세요. 연구팀은 훈련을 안정화하기 위해 RMSNorm을 사용해 각 변환 하위 계층, 주의 계층, 피드포워드 계층의 입력과 출력을 정규화했습니다. 그룹 단위로 관심을 물어보세요. 27B와 9B 모델 모두 GQA, num_groups = 2를 사용하며 절제 기반 실험에서는 다운스트림 성능을 유지하면서 향상된 추론 속도를 보여줍니다.

먼저 일반 텍스트, 순수 영어 합성 및 인위적으로 생성된 프롬프트-응답 쌍의 혼합에 감독 미세 조정(SFT)을 적용합니다. 그런 다음 보상 모델(RLHF) 기반 강화 학습이 이 모델에 적용됩니다. 보상 모델은 토큰 기반 순수 영어 선호도 데이터를 학습하고 전략은 SFT 단계와 동일한 프롬프트를 사용합니다. 마지막으로 각 단계에서 얻은 모델을 평균화하여 전반적인 성능을 향상시킵니다. 조정된 하이퍼파라미터를 포함한 최종 데이터 혼합 및 사후 학습 방법은 모델 유용성을 높이는 동시에 안전 및 환각과 관련된 모델 위험을 최소화하는 방식으로 선택됩니다.





위 내용은 효율성과 경제성에 중점을 둔 Google의 '성실한 작업', Gemma2의 오픈소스 9B 및 27B 버전!의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!
성명:
본 글의 내용은 네티즌들의 자발적인 기여로 작성되었으며, 저작권은 원저작자에게 있습니다. 본 사이트는 이에 상응하는 법적 책임을 지지 않습니다. 표절이나 침해가 의심되는 콘텐츠를 발견한 경우 admin@php.cn으로 문의하세요.
이전 기사:ICML 2024 | 상황별 학습에서 비선형 Transformer 학습 및 일반화 메커니즘 공개다음 기사:ICML 2024 | 상황별 학습에서 비선형 Transformer 학습 및 일반화 메커니즘 공개
관련 기사
더보기- 기술 혁신으로 우리나라의 뇌-컴퓨터 인터페이스 산업 구현이 가속화됩니다.
- 정부가 AI 핵심산업 지원을 위해 향후 5년간 5000억원을 투자하겠다고 밝혔다.
- Lightning News | JD.com, 소매, 의료, 물류 및 기타 산업 시나리오를 위한 Yanxi AI 대형 모델 출시
- 산업정보기술부: 우리나라의 AI 핵심 산업 규모는 5000억 위안에 달하고 2,500개 이상의 디지털 작업장과 스마트 공장이 건설되었습니다.
- 로봇 ETF(159770): 4일 연속 순자본 유입을 유치하는 '휴머노이드 로봇의 혁신 및 개발에 대한 지침 의견'은 산업 발전 프로세스를 촉진할 수 있습니다.