



- 논문 제목: Feature Contamination: Neural Networks Learn Uncorlated Feature and Fail to Generalize
- 논문 링크: https://arxiv.org/pdf/2406.03345
- 코드 링크: https:/ /github.com/trzhang0116/feature-contamination
최근 GPT로 대표되는 대형 모델의 큰 성공과 함께 심층신경망+SGD+스케일링의 머신러닝 패러다임이 다시 한번 AI 현황 분야의 지배력을 입증했습니다. . 심층 신경망 기반 패러다임이 성공한 이유는 무엇입니까? 보다 일반적인 견해는 신경망이 대규모 고차원 입력 데이터로부터 추상적이고 일반화 가능한 특징을 자동으로 학습할 수 있다는 것입니다. 불행하게도 현재 분석 방법과 수학적 도구의 단점으로 인해 "(심층) 신경망이 이러한 특성 학습 프로세스를 구현하는 방법"에 대한 현재의 이해는 아직 그리 깊지 않습니다. 이 때문에 현재 학계 내 관련 연구의 대부분은 여전히 모델이 학습한 특징을 '설명'하는 수준에 머물고 있으며, '개입'을 통해 보다 데이터 효율적이고 일반화 가능한 모델을 얻기 어렵다. 학습 과정. 신경망의 특징 학습 과정을 논의할 때 가장 기본적인 질문 중 하나는 신경망이 입력 데이터에서 어떤 특징을 학습할 것인가입니다. 목표 관점에서 볼 때 신경망의 특징 학습은 작업에 의해 구동되는 "부산물"이며, 그 목적은 훈련 오류를 최소화하는 것입니다. 따라서 우리는 신경망이 데이터에서 "작업 관련" 기능을 추출해야 하고 나머지 "작업 관련 없는" 기능은 데이터 노이즈와 동일하다고 직관적으로 생각할 것입니다. 그러면 신경망은 "필요하지 않으면 학습하지 않는다"(더 정확하게는 단순 편향)라는 특성을 갖고 있기 때문에 신경망은 이를 학습하지 않는 경향이 있어야 합니다. 이는 현재 문헌에서도 공통적으로 나타나는 견해이다.
그러나 최근 ICML 2024에 승인된 작업에서 우리는 이러한 직관적인 인식이 실제로
잘못이라는 것을 발견했습니다! 구체적으로, 우리는 비선형 신경망이 작업 관련 기능을 학습할 때 작업과 관련 없는 기능(우리는 이를 "기능 오염"이라고 함)도 학습하는 경향이 있으며 이러한 경향은 신경망에 영향을 미치기 어렵다는 것을 발견했습니다. 배포 변화가 있는 시나리오로 일반화하기 위한 네트워크입니다. 이론적으로 우리는 단순한 2계층 ReLU 네트워크에서도 특징 오염이 발생하고 신경망의 뉴런 활성화 카테고리 비대칭과 밀접하게 관련되어 있음을 실험적으로 증명했습니다. 또한 특징 오염이 심층에도 존재한다는 일련의 증거를 제시했습니다. ResNet 및 Vision Transformer와 같은 네트워크는 일반화에 부정적인 영향을 미칩니다. 우리가 발견한 실패 모드는 현재 OOD(Out-of-Distribution) 일반화 문헌의 허위 상관 관계를 기반으로 한 주류 분석과 완전히 직교한다는 점은 언급할 가치가 있습니다. 따라서 더 큰 관점에서 우리의 연구 결과는 OOD 일반화에 대한 신경망 자체의 귀납적 편향의 중요성을 보여줍니다. 또한 신경망 특성 학습 및 일반화에 대한 많은 연구도 직관에 대해 재고되어야 할 수도 있음을 보여줍니다.
다음으로 기사의 구체적인 내용을 소개하자면:
연구 배경데이터 분포가 변화하는 시나리오에서의 일반화 능력(즉, OOD 일반화 능력)은 머신러닝 시스템이 현실 환경 배포의 주요 지표 중 하나입니다. 그러나 현재 신경망은 OOD 일반화 시나리오에서 상당한 성능 손실을 겪는 경우가 많습니다. OOD 일반화가 실패하는 이유에 대해 문헌에서 더 주류적인 진술은 표현에 가짜 상관 관계가 존재한다는 것입니다. 즉, 모델은 작업 목표와 관련이 있지만 인과 관계가 없는 특징을 학습할 것입니다. 따라서 분포 변화로 인해 이러한 기능과 작업 목표 간의 상관 관계가 변경되면 예측을 위해 이러한 기능에 의존하는 모델은 원래 성능을 보장할 수 없습니다.
위의 이론적 설명은 매우 직관적이고 자연스러우며 최근 몇 년 동안 OOD 알고리즘 연구를 안내하는 주요 라인이 되었습니다. 즉, 더 나은 최적화 목적 함수와 정규 항을 설계함으로써 모델은 거짓 상관 없이 더 나은 표현을 학습할 수 있습니다. 보다 강력한 일반화 성능을 얻기 위해. 최근 몇 년 동안 알고리즘 설계를 통해 모델의 OOD 일반화를 개선하려는 노력이 이 주요 라인을 따라 많이 진행되었습니다. 그러나 최근 연구에 따르면 이론적 보장이 내장된 많은 알고리즘은 실제 데이터를 기반으로 한 OOD 일반화 작업에 대한 성능 향상이 매우 제한적입니다. 왜 이런 일이 발생하나요? 우리는 현재 OOD 일반화 연구의 어려움이 기존 분석의
두 가지 한계에서 비롯될 수 있다고 믿습니다.
- 기존 연구의 대부분은 허위 상관관계로 인한 실패 모드만 고려합니다.
- 현재 연구의 대부분은 선형 모델에 국한되어 있으며 신경망의 비선형성 및 SGD의 귀납적 편향을 고려하지 않으므로 기존 분석 결과는 다음과 같습니다. 우리가 실제로 사용하는 신경망에 반드시 적합한 것은 아닙니다.
즉, OOD 일반화에 대한 현재의 설명과 이론적 모델은 실제 유통 변화 시나리오를 정확하게 반영하지 못할 수도 있습니다. 따라서 우리는 심층 신경망 기반 OOD의 일반화를 이해하기 위해서는 신경망과 SGD의 귀납적 편향을 고려하는 것이 매우 필요하다고 생각합니다.
Experiment
먼저 실험 설계를 통해 표현 학습 목표를 기반으로 설계된 현재 OOD 일반화 알고리즘이 달성할 수 있는 "성능 상한"을 추정해 봅니다. 허위 상관 이론의 지침에 따라 기존 작업은 주로 보조 표현 학습 목적 함수를 설계하여 OOD로 일반화할 수 있는 표현을 학습하도록 모델을 제한하려고 시도합니다. 이러한 목표를 최적화하면 실제로 원하는 표현을 추출할 수 있는지 연구하기 위해 이상적인 시나리오를 설계했습니다.
- 먼저 훈련 과정에서 모델이 OOD로 일반화할 수 있는 교사 모델에 명시적으로 적합하도록 허용했습니다. 추출된 표현은 표현 증류입니다. 실험에서 이 교사 모델은 대규모 사전 학습 모델(예: CLIP)이 될 수 있습니다. 변수를 제어하기 위해 실제 동작에서는 학생 모델과 교사 모델의 모델 구조가 완전히 동일하도록 제어합니다.
- 두 번째 단계에서는 교사 모델과 학생 모델이 각각 제공한 표현을 기반으로 훈련 세트에서 선형 분류기(선형 프로빙)를 훈련합니다. ,
- 마지막으로 동일하게 분포된 테스트 세트와 OOD 테스트 세트에 대해 Teacher 모델과 Student 모델 기반의 선형 분류기를 테스트하여 이 두 모델에서 추출된 표현의 OOD 일반화를 측정했습니다.

실험 결과는 위 사진에 나와 있습니다. 그림에서 우리는 두 가지 주요 결과를 얻었습니다.
- 훈련 과정에서 교사 모델 표현에 직접적으로 맞지 않는 표준 모델(파란색)과 비교했을 때, 학생 모델(주황색)을 기반으로 한 선형 분류기는 더 나은 OOD 일반화 가능성을 가집니다.
- 그러나 학생 모델(주황색)을 기반으로 한 선형 분류기의 OOD 일반화 성능은 여전히 교사 모델(보라색)을 기반으로 한 선형 분류기에 크게 뒤떨어져 있습니다.
그러므로 우리는 자연스럽게 질문합니다. 교사 모델의 표현을 직접 맞추었으므로 학생 모델과 교사 모델 사이의 일반화 격차는 어디에서 오는 걸까요? 우리는 이 실험 현상을 기존 이론적 설명으로는 직접 설명하기 어렵다는 것을 발견했습니다.
- 우선, 이 격차는 허위 상관 이론으로는 직접 설명할 수 없습니다. training set)은 기본적으로 동일합니다. 그러면 이 두 표현을 기반으로 하는 선형 분류기는 훈련 과정에서 잘못된 상관 특성에 의해 유사하게 영향을 받아야 하며 그렇게 큰 차이가 없어야 합니다.
- 또 다른 가능한 설명은 교사 모델입니다. CLIP) 자체 사전 훈련 과정에서 많은 OOD 샘플을 "확인"했을 수 있으므로 OOD 샘플에 대한 훈련 세트에서 찾을 수 없는 일부 기능을 추출할 수 있습니다. 그러나 최근 연구에 따르면 OOD 테스트 샘플과 유사한 샘플을 모두 CLIP의 사전 학습 데이터에서 제거하더라도 CLIP은 여전히 강력한 OOD 일반화를 갖고 있는 것으로 나타났습니다[1]. 이는 단순히 이러한 관점에서만 교사 모델과 학생 모델의 격차를 설명하는 것만으로는 충분하지 않음을 보여줍니다.
요컨대, 우리가 실험에서 실제로 관찰한 OOD 일반화 능력의 차이를 기존 분석으로는 설명하기 부족하다고 생각합니다. 동시에 "OOD로 일반화할 수 있는 직접 피팅 표현"은 OOD로 일반화할 수 있는 모델을 보장할 수 없으므로 표현 학습의 "목표" 외에도 표현 학습의 "과정"도 고려해야 합니다. 표현 학습. "은 신경망의 특징 학습 역학으로 인해 발생하는 귀납적 편향입니다. 이론상 심층 신경망의 특징 학습 과정을 직접 분석하는 것은 매우 어렵지만, 2계층 ReLU 네트워크에서도 흥미로운 특징 학습 경향, 즉 "특성 오염"이 나타날 것이라는 사실을 발견했습니다. 또한 신경망의 OOD 일반화와 직접적으로 관련됩니다.
이론
이 섹션에서는 2계층 ReLU 네트워크 기반 이진 분류 문제에서 "특성 오염" 현상의 존재를 증명하고 이 현상의 원인을 분석합니다. 구체적으로, 네트워크에 대한 입력은 "핵심 기능"과 "배경 기능"이라는 두 가지 기능의 선형 조합으로 구성된다고 가정합니다. 그 중 핵심 특징의 분포는 카테고리 라벨에 따라 달라지며(이미지 분류 문제에서 분류할 객체로 시각화 가능), 배경 특징의 분포는 라벨과 관련이 없습니다(이미지 분류 문제에서 분류 대상으로 시각화 가능). 이미지 분류 문제의 그림 배경 및 기타 요소). 다른 요인의 간섭을 제거하기 위해 우리는 이 두 가지 유형의 기능에 대해 다음과 같은 가정을 합니다.
- 배경 기능은 레이블과 상관 관계가 없습니다(따라서 허위 상관 관계로 인한 실패 모드를 제거합니다).
- 핵심 기능은 100% 정확도로 라벨을 예측할 수 있습니다(이렇게 하면 훈련 세트의 기능 부족으로 인한 실패 모드를 제거할 수 있습니다).
- 핵심 기능과 배경 기능은 직교 하위 공간에 배포됩니다(이 방법으로 분리하기 어려운 다양한 기능으로 인해 발생하는 실패 모드를 제외합니다).
위의 조건에서도 신경망은 핵심 기능을 학습하면서 작업과 전혀 관련이 없는 배경 기능을 계속 학습한다는 것을 발견했습니다. 네트워크 가중치 공간에서 이 두 가지 특징의 결합으로 인해 배경 특징에서 발생하는 분포 변화로 인해 신경망의 오류가 증가하여 네트워크의 OOD 일반화가 감소합니다. 따라서 우리는 이러한 신경망의 특징 학습 선호도를 "특성 오염"이라고 부릅니다. 아래에서는 기능 오염의 원인을 자세히 소개합니다. 전반적인 분석 아이디어의 개략도는 다음과 같습니다.

우리 분석의 핵심 포인트는 특성 오염이 실제로 신경망의 뉴런이 종종 비대칭 활성화(비대칭 활성화)를 갖는다는 사실과 관련이 있다는 것입니다. 다양한 카테고리에 대해. 구체적으로, 충분한 SGD 반복 후에 네트워크에 있는 뉴런의 적어도 상당 부분이 카테고리의 샘플과 양의 상관관계를 갖는 경향이 있음을 보여줄 수 있습니다(우리는 이를 이 뉴런의 양의 샘플이라고 부르며 ypos를 사용합니다) 해당 카테고리를 나타냄), 다른 카테고리의 샘플과 음의 상관관계를 유지합니다(우리는 이를 이 뉴런의 음의 샘플이라고 부르고 yneg는 해당 카테고리를 나타냄). 이는 정리 4.1에 표시된 것처럼 이러한 뉴런의 활성화에서 카테고리 비대칭으로 이어질 것입니다.

이러한 카테고리 비대칭이 신경망의 기능 학습 프로세스에 어떤 영향을 미치나요? 우리는 먼저 네트워크 은닉층의 k번째 뉴런에 대해 가중치 벡터 wk가 t번째 반복 후에 분할될 수 있다는 것을 알아냈습니다.

위 공식에서 Score과 S bg는 각각 핵심 기능 및 배경 기능 세트를 나타내며, 여기서 각 mj은 핵심 기능 또는 배경 기능에 해당합니다. 이 공식에서 우리는 뉴런의 가중치가 다양한 특징에 대한 투영으로 분해될 수 있다는 것을 알 수 있습니다(여기서는 다양한 mj이 직교 단위 벡터라고 가정합니다). 또한, 각 배경 특징 mj, j가 Sbg에 속하는 wk의 음의 기울기 투영이 다음을 만족함을 증명할 수 있습니다.

범주 비대칭 활성화를 갖는 뉴런의 경우, 정리에 따르면 4.1에서 우리는 그 기울기가 주로 뉴런의 양성 샘플 y=ypos에 의존하고 음성 샘플 y=yneg과는 거의 관련이 없다는 것을 알 수 있습니다. 이로 인해 양성 샘플에 존재하는 핵심 기능과 배경 기능이 동시에 긍정적인 그라데이션 투영을 얻게 되며 이 프로세스는 기능과 레이블 간의 상관 관계와 관련이 없습니다. 정리 4.2에서 볼 수 있듯이, 충분한 SGD 반복 후에 위의 경사 투영이 축적되면 뉴런이 학습한 특징에 핵심 특징과 결합된 배경 특징이 모두 포함된다는 것을 증명합니다.
 결합으로 인해 뉴런 가중치의 핵심 특징과 배경 특징의 경우, 배경 특징의 음수 분포 이동은 뉴런의 활성화를 감소시켜 추가적인 OOD 오류를 발생시킵니다. 정리 4.3에서 볼 수 있듯이 ID 및 OOD의 일반화 위험에 대한 특성 오염의 영향을 정량적으로 설명합니다.
결합으로 인해 뉴런 가중치의 핵심 특징과 배경 특징의 경우, 배경 특징의 음수 분포 이동은 뉴런의 활성화를 감소시켜 추가적인 OOD 오류를 발생시킵니다. 정리 4.3에서 볼 수 있듯이 ID 및 OOD의 일반화 위험에 대한 특성 오염의 영향을 정량적으로 설명합니다.
 동시에, 신경망의 비선형성을 제거한 후에는 특성 오염이 더 이상 발생하지 않는다는 것을 증명합니다.
동시에, 신경망의 비선형성을 제거한 후에는 특성 오염이 더 이상 발생하지 않는다는 것을 증명합니다.
아래 그림과 같이 수치 실험을 통해 이론적 결과를 검증했습니다. 동시에, 2계층 ReLU 네트워크 + SGD 외에도 다른 유형의 활성화 함수, 적응형 단계 크기를 갖춘 최적화 프로그램 등을 포함하여 보다 일반적인 설정으로 결론을 확장했습니다. 결과는 그림 3( d) ), 이는 기능 오염이 보다 일반적인 설정에서도 널리 퍼져 있음을 나타냅니다.

동시에 우리가 일상적으로 사용하는 ResNet, Vision Transformer와 같은 심층 네트워크에서도 특징 오염 현상이 발생한다는 사실을 보여주기 위해 더 많은 실험적 증거와 특징 시각화를 제공하며, 우리 실험의 관찰 결과 OOD 일반화 격차에 도달했습니다. 이 부분에 관심이 있는 사람은 원본 논문의 5장을 참조할 수 있습니다.
요약 및 토론
마지막으로, 미래에 더 중요할 수 있거나 심도 있게 계속될 수 있는 몇 가지 연구 사항을 나열합니다. 우리와 더 깊이 소통하고 싶은 모든 분들을 환영합니다:- 더 깊은 네트워크. :심층 네트워크에도 특징 오염 문제가 있다는 것을 실험적으로 입증했지만 지금까지 이론적 분석은 2계층 ReLU 네트워크만 수행했습니다. 우리는 특징 오염이 보다 일반적인 개념일 수 있으며 범주에 대한 뉴런의 활성화 비대칭이 발생 원인 중 하나일 수 있다고 의심합니다. 더 깊은 네트워크나 더 복잡한 네트워크 구조(예: 정규화 계층 도입 등)를 분석함으로써 기능 오염의 더 많은 원인을 발견하고 타겟 솔루션을 제공할 수 있습니다.
- 사전 훈련의 역할: 이 기사의 이론적 분석에서는 처음부터 훈련하는 경우만 고려하지만 실제로 사용하는 모델은 사전 훈련된 모델인 경우가 많습니다. 사전 훈련이 모델의 OOD 일반화를 개선하는 데 도움이 될 수 있다는 실험적 증거가 많이 있습니다. 그러면 이러한 일반화 개선의 본질이 특성 오염 문제를 완화하는 것과 관련이 있습니까? 사전 훈련은 어떻게 이루어지나요?
- Feature 오염 문제 해결 방법: 우리 연구에서 Feature 오염 문제를 지적했지만 아직 명확한 해결책을 제시하지 못했습니다. 그러나 우리의 후속 연구 중 일부에서는 대형 모델을 미세 조정할 때 유사한 문제가 발생한다는 사실을 보여 주었으며, 기울기 조정을 기반으로 한 일부 방법이 실제로 이 문제를 완화하여 미세 조정 모델을 크게 향상시킬 수 있음을 발견했습니다. 능력. 앞으로 이 부분의 구체적인 내용도 공개할 예정이니 많은 관심 부탁드립니다.
저자 소개 | 이 기사의 저자인 Zhang Tianren은 칭화대학교 자동화학과에서 박사 과정을 밟고 있습니다. 그의 지도교수는 Chen 교수입니다. 풍. 박사 과정 동안 저자는 주로 기계 학습의 표현 학습 및 일반화 문제에 대한 이론 및 알고리즘 연구를 수행했으며 ICML, NeurIPS, ICLR, IEEE TPAMI 등과 같은 최고의 기계 학습 컨퍼런스 및 저널에 많은 기사를 게재했습니다.
저자 소속 | 칭화대학교 VIPLAB
연락처 이메일 | zhangtr22@mails.tsinghua.edu.cn
참고자료
[1] Mayilvahanan, P., Wiedemer, T., Rusak , E. , Bethge, M. 및 Brendel, W. CLIP의 일반화 성능은 주로 학습 표현에 관한 국제 회의, 2024에서 높은 훈련 테스트 유사성에서 비롯됩니까?위 내용은 ICML 2024 | 기능 오염: 신경망이 관련 없는 기능을 학습하고 일반화에 실패함의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

 五个时间序列预测的深度学习模型对比总结May 05, 2023 pm 05:16 PM
五个时间序列预测的深度学习模型对比总结May 05, 2023 pm 05:16 PMMakridakisM-Competitions系列(分别称为M4和M5)分别在2018年和2020年举办(M6也在今年举办了)。对于那些不了解的人来说,m系列得比赛可以被认为是时间序列生态系统的一种现有状态的总结,为当前得预测的理论和实践提供了经验和客观的证据。2018年M4的结果表明,纯粹的“ML”方法在很大程度上胜过传统的统计方法,这在当时是出乎意料的。在两年后的M5[1]中,最的高分是仅具有“ML”方法。并且所有前50名基本上都是基于ML的(大部分是树型模型)。这场比赛看到了LightG
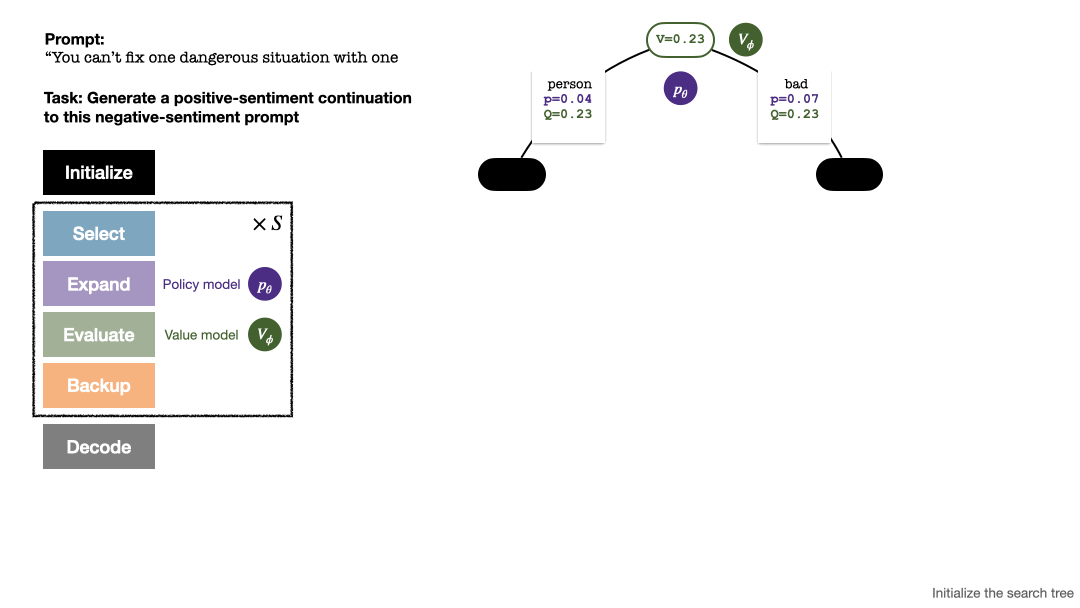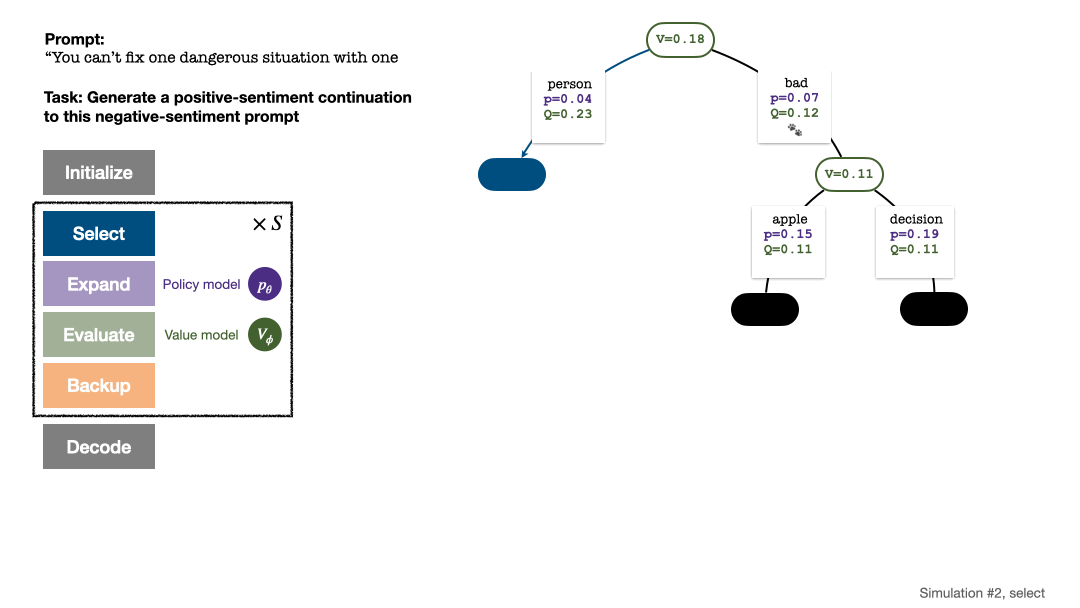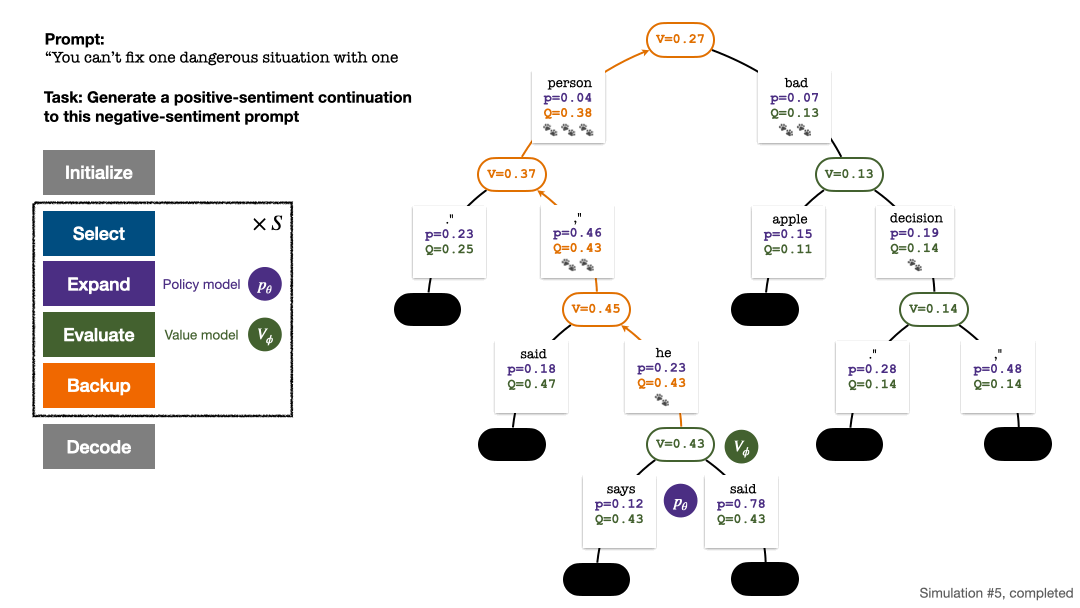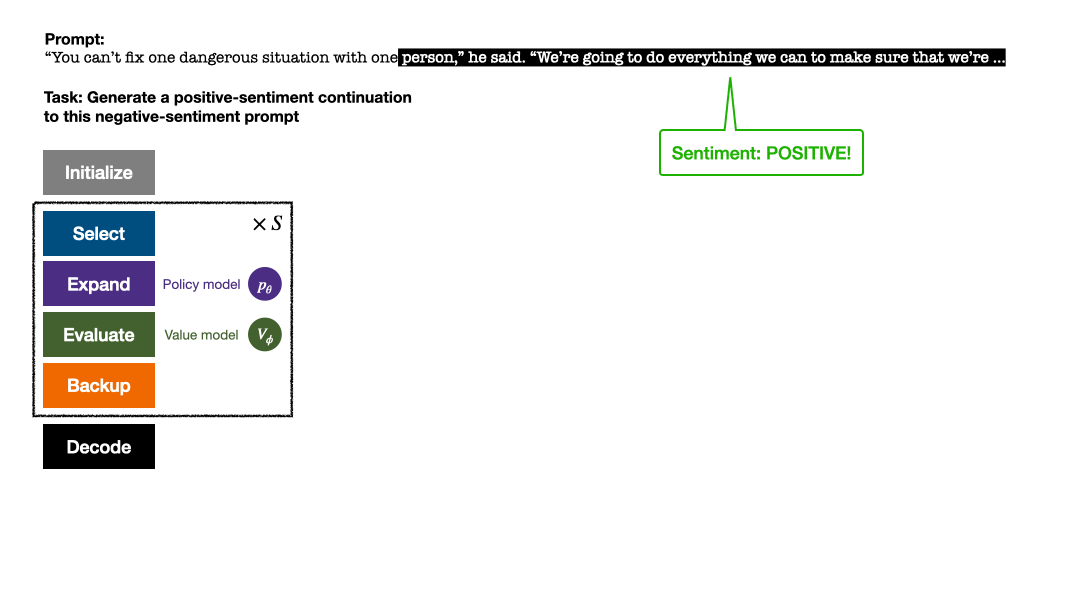 RLHF与AlphaGo核心技术强强联合,UW/Meta让文本生成能力再上新台阶Oct 27, 2023 pm 03:13 PM
RLHF与AlphaGo核心技术强强联合,UW/Meta让文本生成能力再上新台阶Oct 27, 2023 pm 03:13 PM在一项最新的研究中,来自UW和Meta的研究者提出了一种新的解码算法,将AlphaGo采用的蒙特卡洛树搜索算法(Monte-CarloTreeSearch,MCTS)应用到经过近端策略优化(ProximalPolicyOptimization,PPO)训练的RLHF语言模型上,大幅提高了模型生成文本的质量。PPO-MCTS算法通过探索与评估若干条候选序列,搜索到更优的解码策略。通过PPO-MCTS生成的文本能更好满足任务要求。论文链接:https://arxiv.org/pdf/2309.150
 MIT团队运用机器学习闭环自主分子发现平台,成功发现、合成和描述了303种新分子Jan 04, 2024 pm 05:38 PM
MIT团队运用机器学习闭环自主分子发现平台,成功发现、合成和描述了303种新分子Jan 04, 2024 pm 05:38 PM编辑|X传统意义上,发现所需特性的分子过程一直是由手动实验、化学家的直觉以及对机制和第一原理的理解推动的。随着化学家越来越多地使用自动化设备和预测合成算法,自主研究设备越来越接近实现。近日,来自MIT的研究人员开发了由集成机器学习工具驱动的闭环自主分子发现平台,以加速具有所需特性的分子的设计。无需手动实验即可探索化学空间并利用已知的化学结构。在两个案例研究中,该平台尝试了3000多个反应,其中1000多个产生了预测的反应产物,提出、合成并表征了303种未报道的染料样分子。该研究以《Autonom
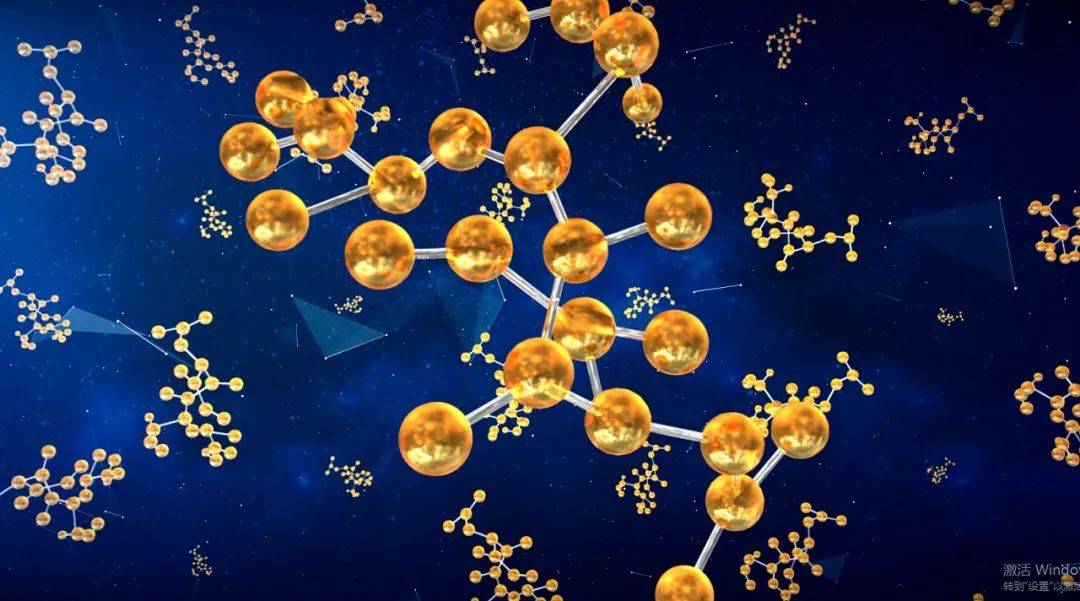
 Code Llama代码能力飙升,微调版HumanEval得分超越GPT-4,一天发布Aug 26, 2023 pm 09:01 PM
Code Llama代码能力飙升,微调版HumanEval得分超越GPT-4,一天发布Aug 26, 2023 pm 09:01 PM昨天,Meta开源专攻代码生成的基础模型CodeLlama,可免费用于研究以及商用目的。CodeLlama系列模型有三个参数版本,参数量分别为7B、13B和34B。并且支持多种编程语言,包括Python、C++、Java、PHP、Typescript(Javascript)、C#和Bash。Meta提供的CodeLlama版本包括:代码Llama,基础代码模型;代码羊-Python,Python微调版本;代码Llama-Instruct,自然语言指令微调版就其效果来说,CodeLlama的不同版
 AI助力脑机接口研究,纽约大学突破性神经语音解码技术,登Nature子刊Apr 17, 2024 am 08:40 AM
AI助力脑机接口研究,纽约大学突破性神经语音解码技术,登Nature子刊Apr 17, 2024 am 08:40 AM作者|陈旭鹏编辑|ScienceAI由于神经系统的缺陷导致的失语会导致严重的生活障碍,它可能会限制人们的职业和社交生活。近年来,深度学习和脑机接口(BCI)技术的飞速发展为开发能够帮助失语者沟通的神经语音假肢提供了可行性。然而,神经信号的语音解码面临挑战。近日,约旦大学VideoLab和FlinkerLab的研究者开发了一个新型的可微分语音合成器,可以利用一个轻型的卷积神经网络将语音编码为一系列可解释的语音参数(例如音高、响度、共振峰频率等),并通过可微分神经网络将这些参数合成为语音。这个合成器
 准确率 >98%,基于电子密度的 GPT 用于化学研究,登 Nature 子刊Mar 27, 2024 pm 02:16 PM
准确率 >98%,基于电子密度的 GPT 用于化学研究,登 Nature 子刊Mar 27, 2024 pm 02:16 PM编辑|紫罗可合成分子的化学空间是非常广阔的。有效地探索这个领域需要依赖计算筛选技术,比如深度学习,以便快速地发现各种有趣的化合物。将分子结构转换为数字表示形式,并开发相应算法生成新的分子结构是进行化学发现的关键。最近,英国格拉斯哥大学的研究团队提出了一种基于电子密度训练的机器学习模型,用于生成主客体binders。这种模型能够以简化分子线性输入规范(SMILES)格式读取数据,准确率高达98%,从而实现对分子在二维空间的全面描述。通过变分自编码器生成主客体系统的电子密度和静电势的三维表示,然后通
 手机摄影技术让以假乱真的好莱坞级电影特效视频走红Sep 07, 2023 am 09:41 AM
手机摄影技术让以假乱真的好莱坞级电影特效视频走红Sep 07, 2023 am 09:41 AM一个普通人用一台手机就能制作电影特效的时代已经来了。最近,一个名叫Simulon的3D技术公司发布了一系列特效视频,视频中的3D机器人与环境无缝融合,而且光影效果非常自然。呈现这些效果的APP也叫Simulon,它能让使用者通过手机摄像头的实时拍摄,直接渲染出CGI(计算机生成图像)特效,就跟打开美颜相机拍摄一样。在具体操作中,你要先上传一个3D模型(比如图中的机器人)。Simulon会将这个模型放置到你拍摄的现实世界中,并使用准确的照明、阴影和反射效果来渲染它们。整个过程不需要相机解算、HDR
 谷歌用大型模型训练机器狗理解模糊指令,激动不已准备去野餐Jan 16, 2024 am 11:24 AM
谷歌用大型模型训练机器狗理解模糊指令,激动不已准备去野餐Jan 16, 2024 am 11:24 AM人类和四足机器人之间简单有效的交互是创造能干的智能助理机器人的途径,其昭示着这样一个未来:技术以超乎我们想象的方式改善我们的生活。对于这样的人类-机器人交互系统,关键是让四足机器人有能力响应自然语言指令。近来大型语言模型(LLM)发展迅速,已经展现出了执行高层规划的潜力。然而,对LLM来说,理解低层指令依然很难,比如关节角度目标或电机扭矩,尤其是对于本身就不稳定、必需高频控制信号的足式机器人。因此,大多数现有工作都会假设已为LLM提供了决定机器人行为的高层API,而这就从根本上限制了系统的表现能


핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

안전한 시험 브라우저
안전한 시험 브라우저는 온라인 시험을 안전하게 치르기 위한 보안 브라우저 환경입니다. 이 소프트웨어는 모든 컴퓨터를 안전한 워크스테이션으로 바꿔줍니다. 이는 모든 유틸리티에 대한 액세스를 제어하고 학생들이 승인되지 않은 리소스를 사용하는 것을 방지합니다.

DVWA
DVWA(Damn Vulnerable Web App)는 매우 취약한 PHP/MySQL 웹 애플리케이션입니다. 주요 목표는 보안 전문가가 법적 환경에서 자신의 기술과 도구를 테스트하고, 웹 개발자가 웹 응용 프로그램 보안 프로세스를 더 잘 이해할 수 있도록 돕고, 교사/학생이 교실 환경 웹 응용 프로그램에서 가르치고 배울 수 있도록 돕는 것입니다. 보안. DVWA의 목표는 다양한 난이도의 간단하고 간단한 인터페이스를 통해 가장 일반적인 웹 취약점 중 일부를 연습하는 것입니다. 이 소프트웨어는

SublimeText3 영어 버전
권장 사항: Win 버전, 코드 프롬프트 지원!

에디트플러스 중국어 크랙 버전
작은 크기, 구문 강조, 코드 프롬프트 기능을 지원하지 않음

SublimeText3 Linux 새 버전
SublimeText3 Linux 최신 버전

