상식 작업을 기반으로 상태 변화를 시뮬레이션할 때 GPT-4의 정확도가 약 60%에 불과한 경우에도 대규모 언어 모델을 월드 시뮬레이터로 사용하는 것을 고려해야 할까요?
지난 이틀 동안 ACL 2024에 선정된 논문 "Can Language Models Serve as Text-Based World Simulators?"는 소셜 미디어 X에서 열띤 토론을 불러일으켰고 Turing Award 수상자 Yann LeCun도 관련된. 이 백서에서 탐구한 질문은 다음과 같습니다. 현재 언어 모델 자체가 세계 시뮬레이터 역할을 하고 작업이 다양한 세계 상태를 어떻게 변경하는지 정확하게 예측하여 광범위한 수동 코딩이 필요하지 않게 할 수 있습니까? 이 문제에 대해 애리조나 대학교, 뉴욕 대학교, 존스 홉킨스 대학교, 마이크로소프트 연구소, Allen 인공 지능 연구소 및 기타 기관의 연구자들은 "텍스트 기반 시뮬레이터"라는 맥락에서 그들의 대답은 다음과 같습니다. 에 주어진다. 그들은 언어 모델을 세계 시뮬레이터로 사용할 수 없다고 믿습니다. 예를 들어 GPT-4는 물 끓이기 등 상식적인 작업을 기반으로 상태 변화를 시뮬레이션할 때 정확도가 약 60%에 불과합니다.  동의를 표명하며 "세계적인 모델 없이는 계획도 없다"고 믿었습니다
동의를 표명하며 "세계적인 모델 없이는 계획도 없다"고 믿었습니다
과제 훈련의 정확도는 60%에 달합니다. 어느 정도 모델”? 그리고 LLM이 반복되면서 계속해서 개선될 것입니다. LeCun은 또한 세계 모델이 LLM이 아닐 것이라고 말했습니다.
백서에서 연구원들은 "ByteSized32-State-Prediction"이라는 새로운 벤치마크를 구축하고 사용했습니다. 이 벤치마크에는 텍스트 게임 상태 전환과 이에 수반되는 게임 작업으로 구성된 데이터 세트가 포함되어 있습니다. 그들은 처음으로 이 벤치마크를 사용하여 텍스트 기반 세계 시뮬레이터인 LLM(대형 언어 모델)의 성능을 직접적으로 정량화했습니다.
연구원들은 이 데이터세트에서 GPT-4를 테스트함으로써 인상적인 성능에도 불구하고 추가 혁신 없이는 여전히 신뢰할 수 없는 세계 시뮬레이터라는 사실을 발견했습니다.
따라서 연구원들은 자신의 작업이 현재 LLM의 기능과 약점에 대한 새로운 통찰력과 새로운 모델이 등장함에 따라 향후 진행 상황을 추적하기 위한 새로운 기준을 제공한다고 믿습니다.
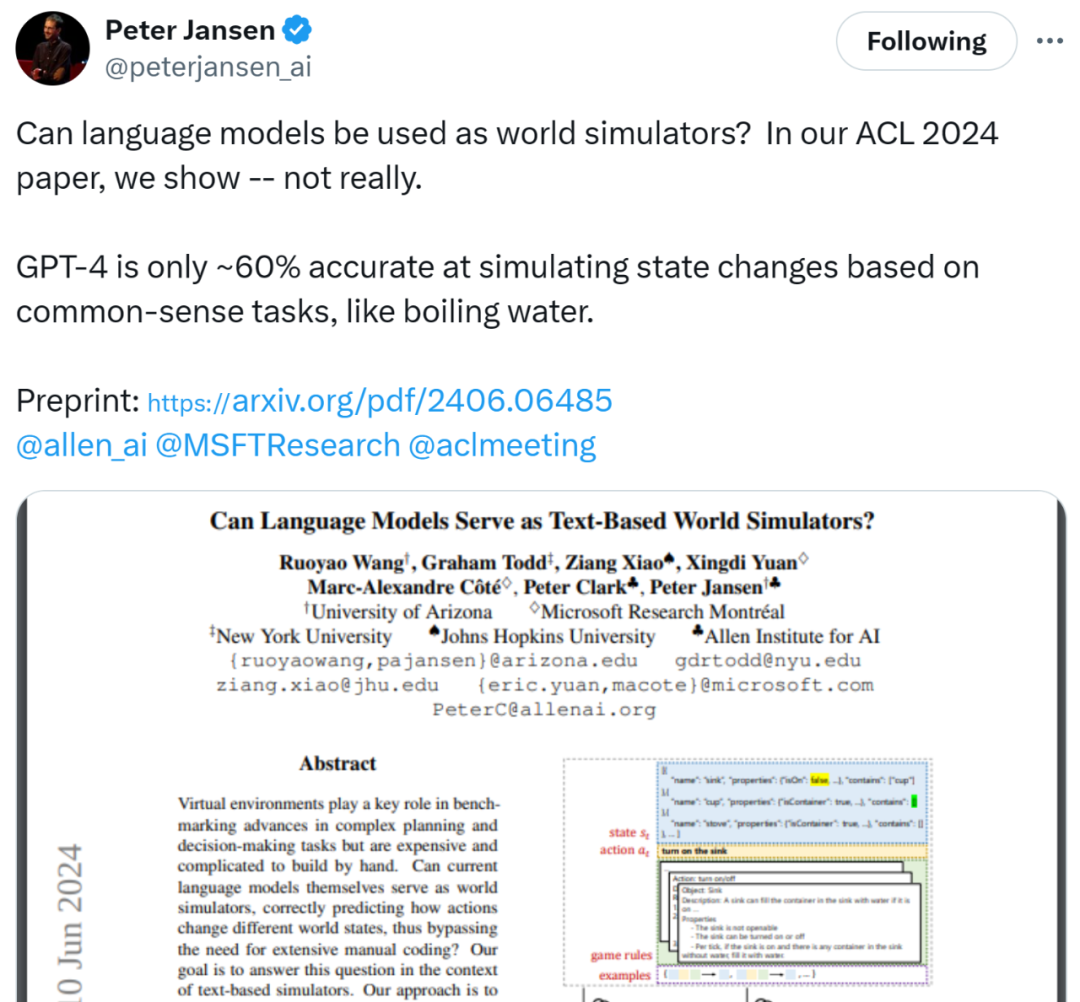
논문 주소: https://arxiv.org/pdf/2406.06485연구원들은 텍스트 기반 가상 환경에서 세계 시뮬레이터 역할을 하는 LLM의 능력을 탐구했습니다. 이 환경에서 에이전트는 관찰을 받고 일부 목표를 달성하기 위해 자연어로 작업을 제안합니다. 각 텍스트 환경은 공식적으로 7개의 튜플(S,A,T,O,R,C,D)이 있는 목표 조건부 부분 관찰 가능 마르코프 결정 프로세스(POMDP)로 표현될 수 있으며, S는 상태 공간을 나타냅니다. , A는 행동 공간을 나타내고, T : S×A→S는 변환 함수를 나타내고, O는 관찰 함수를 나타내고, R : S×A→R은 보상 함수를 나타내고, C는 대상을 설명하는 자연어 "컨텍스트 메시지"를 나타내고, 동작 의미론, D: S×A→{0,1}은 바이너리 완료 표시기 함수를 나타냅니다. 연구원들은 정량적 평가를 위해 LLM as-a-Simulator(LLM-Sim)라는 예측 작업을 제안했습니다. 언어 모델의 능력 신뢰할 수 있는 시뮬레이터 역할을 하기 위해. LLM-Sim 작업은 F : C×S×A→S×R×{0,1} 함수를 월드 시뮬레이터로 구현하는 것입니다. 실제로 완전한 상태 전환 시뮬레이터 F는 액션 기반 전환과 환경 기반 전환이라는 두 가지 유형의 상태 전환을 고려해야 합니다. 그림 1은 LLM을 텍스트 게임 시뮬레이터로 사용하는 예입니다. 싱크대가 열린 후 싱크대에 있는 컵에 물이 채워집니다. 작업 기반 전환은 싱크대를 여는 작업을 수행한 후 싱크대가 열리는 반면(isOn=true) 환경 기반 전환은 싱크대를 열면 싱크대의 컵이 채워집니다.
각 전환을 모델링하는 LLM의 능력을 더 잘 이해하기 위해 연구원들은 시뮬레이터 기능 F를 세 단계로 더 분해했습니다. , F_act: C×S×A→S는 s^act_t+1을 예측합니다. 여기서 s^act_t+1은 동작으로 인한 직접적인 상태 변경을 나타냅니다.
환경 중심 전환 시뮬레이터- : c 및 s^act_t+1이 주어지면 F_env: C×S→S는 s_t+1을 예측합니다. 여기서 s_t+1은 환경 중심 전환으로 인한 상태입니다.
게임 진행 시뮬레이터- : 주어진 c, s_t+1 및 a_t, F_R: C×S×A→R×{0,1}는 보상 r_t+1 및 게임 완료 상태 d_t+1을 예측합니다.
- 또한 연구원들은 LLM-Sim 작업의 두 가지 변형을 고려했습니다
전체 상태 예측
상태 차이 예측- : LLM은 입력 상태와 출력 상태의 차이만 출력합니다.
이 작업을 수행하기 위해 연구원들은 새로운 텍스트 게임 상태 전환 데이터 세트를 도입했습니다. 데이터 세트는 "BYTESIZED32-State-Prediction(BYTESIZED32-SP)"이며, 이는 (c,s_t,rt,d_t,a_t,s^act_t+1,s_t+1,r_t+1,d_t로 표현되는 76,369개의 변환을 포함합니다. +1) 튜플 . 이러한 전환은 31개의 다양한 텍스트 게임에서 수집되었습니다.
아래 표 1에는 추가 코퍼스 통계가 요약되어 있습니다.
LLM-Sim의 성능은 테스트 샘플 데이터 세트의 실제 레이블을 기준으로 모델의 예측 정확도에 따라 결정됩니다. 실험 조건에 따라 LLM은 다음과 같이 정의된 개체 속성(F_act, F_env 또는 F 시뮬레이션) 및/또는 게임 진행(F_R 또는 F 시뮬레이션)을 시뮬레이션해야 합니다.
- Object Properties: 게임, 각 개체의 속성(예: 온도, 크기) 및 다른 개체와의 관계(예: 다른 개체 내부 또는 위에 있음).
- 게임 진행: 현재 누적된 보상, 게임 종료 여부, 전체 목표 달성 여부 등 전체 목표 대비 에이전트의 상태입니다.
연구원들은 각 경우에 LLM이 전체 작업 컨텍스트뿐만 아니라 실제 이전 상태(함수가 F_env인 경우 이전 상태는 s^act_t+1)를 제공한다는 사실을 알아냈습니다. 즉, LLM은 항상 단일 단계 예측을 수행합니다. 위의 그림 1은 연구원이 LLM-Sim 작업에서 모델의 성능을 평가하기 위해 상황별 학습을 사용하는 것을 보여줍니다. 그들은 완전한 상태 및 상태차 예측 메커니즘에서 GPT-4의 정확성을 평가했습니다. 모델은 이전 상태(JSON 개체로 인코딩됨), 이전 작업 및 컨텍스트 메시지를 수신하고 후속 상태(완전한 JSON 개체 또는 차이점)를 생성합니다. 아래 표 2는 전체 상태 전환을 시뮬레이션할 뿐만 아니라 작업 기반 전환 및 환경 기반 전환을 개별적으로 시뮬레이션하는 GPT-4의 정확도를 보여줍니다.
연구원들은 다음과 같은 중요한 사실을 발견했습니다. 환경 중심 전환을 예측하는 것보다 행동 중심 전환을 예측하는 것이 더 쉽습니다. 최상의 경우 GPT-4는 동적 동작 중심 전환의 77.1%를 올바르게 모델링할 수 있습니다. 이에 비해 GPT-4는 동적 환경 기반 변환의 최대 49.7%를 정확하게 시뮬레이션합니다. 동적 전환보다 정적 전환을 예측하는 것이 더 쉽습니다. 예상한 대로 대부분의 경우 동적 변환보다 정적 변환을 모델링하는 것이 훨씬 쉽습니다. 동적 상태의 경우 전체 게임 상태를 예측하기가 더 쉽고 정적 상태의 경우 상태 차이를 예측하기가 더 쉽습니다. 동적 상태의 상태 차이를 예측하면 정적 전환을 시뮬레이션할 때 성능이 크게 향상(>10%)될 수 있지만 동적 전환을 시뮬레이션할 때는 성능이 저하됩니다. 게임 규칙은 매우 중요합니다. LLM은 충분한 게임 규칙을 생성할 수 있습니다. 컨텍스트 메시지에 게임 규칙이 제공되지 않으면 대부분의 경우 세 가지 시뮬레이션 작업 모두에서 GPT-4 성능이 저하됩니다. GPT-4는 대부분의 경우 게임 진행 상황을 예측할 수 있습니다. 아래 표 3은 GPT-4의 게임 진행 예측 결과를 보여준다. GPT-4는 상황에 따른 게임 규칙 정보를 통해 테스트 사례의 92.1%에서 게임 진행 상황을 정확하게 예측할 수 있습니다. 이러한 규칙의 존재는 맥락에서 매우 중요합니다. 규칙이 없으면 GPT-4의 예측 정확도는 61.5%로 떨어집니다.
LLM-Sim 작업의 인간 성능이 GPT-4보다 낫습니다. 연구원들은 LLM-Sim 작업에 대한 예비 인간 연구를 수행했습니다. 그 결과를 하기 표 4에 나타내었다. 사람의 전체 정확도는 80%인 반면 샘플링된 LLM의 정확도는 50%로 다른 주석자 간에 거의 차이가 없는 것으로 나타났습니다. 이는 작업이 일반적으로 인간에게는 직관적이고 상대적으로 쉽지만 LLM에는 여전히 상당한 개선 여지가 있음을 보여줍니다.
GPT-4는 산술, 상식 또는 과학적 지식이 필요할 때 오류가 발생하기 더 쉽습니다. 아래 그림 2는 전체 상태 전환, 작업 중심 전환 및 환경 중심 전환에 대한 예측 결과가 올바른 비율, 속성을 잘못된 값으로 설정한 비율, 속성 값을 변경하지 못한 비율을 보여줍니다. GPT-4가 대부분의 간단한 부울 속성을 매우 잘 처리할 수 있다는 것을 알 수 있습니다. 산술(예: 온도, timeAboveMaxTemp), 상식(예: current_aperture, current_focus) 또는 과학적 지식(예: on)이 필요한 중요 속성 주변에 오류가 모여 있습니다.
더 자세한 기술적 내용과 실험 결과는 원본 논문을 참고해주세요. 위 내용은 ACL 2024 논문의 최종 결론: 대규모 언어 모델 ≠ 월드 시뮬레이터, Yann LeCun: 그렇군요.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!


 동의를 표명하며 "세계적인 모델 없이는 계획도 없다"고 믿었습니다
동의를 표명하며 "세계적인 모델 없이는 계획도 없다"고 믿었습니다  백서에서 연구원들은 "ByteSized32-State-Prediction"이라는 새로운 벤치마크를 구축하고 사용했습니다. 이 벤치마크에는 텍스트 게임 상태 전환과 이에 수반되는 게임 작업으로 구성된 데이터 세트가 포함되어 있습니다. 그들은 처음으로 이 벤치마크를 사용하여 텍스트 기반 세계 시뮬레이터인 LLM(대형 언어 모델)의 성능을 직접적으로 정량화했습니다.
백서에서 연구원들은 "ByteSized32-State-Prediction"이라는 새로운 벤치마크를 구축하고 사용했습니다. 이 벤치마크에는 텍스트 게임 상태 전환과 이에 수반되는 게임 작업으로 구성된 데이터 세트가 포함되어 있습니다. 그들은 처음으로 이 벤치마크를 사용하여 텍스트 기반 세계 시뮬레이터인 LLM(대형 언어 모델)의 성능을 직접적으로 정량화했습니다. 





