
Llama 2를 로컬로 다운로드하고 설치하는 방법

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB원래의
- 2024-06-14 20:33:401066검색
이를 염두에 두고 Text-Generation-WebUI를 사용하여 양자화된 Llama 2 LLM을 컴퓨터에 로컬로 로드하는 방법에 대한 단계별 가이드를 만들었습니다.
Llama 2를 로컬에 설치하는 이유
사람들이 Llama 2를 직접 실행하는 데에는 여러 가지 이유가 있습니다. 일부는 개인 정보 보호 문제를 위해, 일부는 사용자 정의를 위해, 다른 일부는 오프라인 기능을 위해 수행합니다. 프로젝트를 위해 Llama 2를 연구, 미세 조정 또는 통합하는 경우 API를 통해 Llama 2에 액세스하는 것이 적합하지 않을 수 있습니다. PC에서 로컬로 LLM을 실행하는 목적은 잠재적으로 민감한 데이터가 회사 및 기타 조직에 유출될 염려 없이 타사 AI 도구에 대한 의존도를 줄이고 언제 어디서나 AI를 사용하는 것입니다.
이제 Llama 2를 로컬에 설치하는 단계별 가이드부터 시작하겠습니다.
1단계: Visual Studio 2019 빌드 도구 설치
작업을 단순화하기 위해 Text-Generation-WebUI(GUI로 Llama 2를 로드하는 데 사용되는 프로그램)용 원클릭 설치 프로그램을 사용하겠습니다. 그러나 이 설치 관리자가 작동하려면 Visual Studio 2019 빌드 도구를 다운로드하고 필요한 리소스를 설치해야 합니다.
다운로드: Visual Studio 2019(무료)
소프트웨어의 커뮤니티 에디션을 다운로드하세요. 이제 Visual Studio 2019를 설치하고 소프트웨어를 엽니다. 열리면 C++를 사용한 데스크톱 개발 확인란을 선택하고 설치를 누르세요.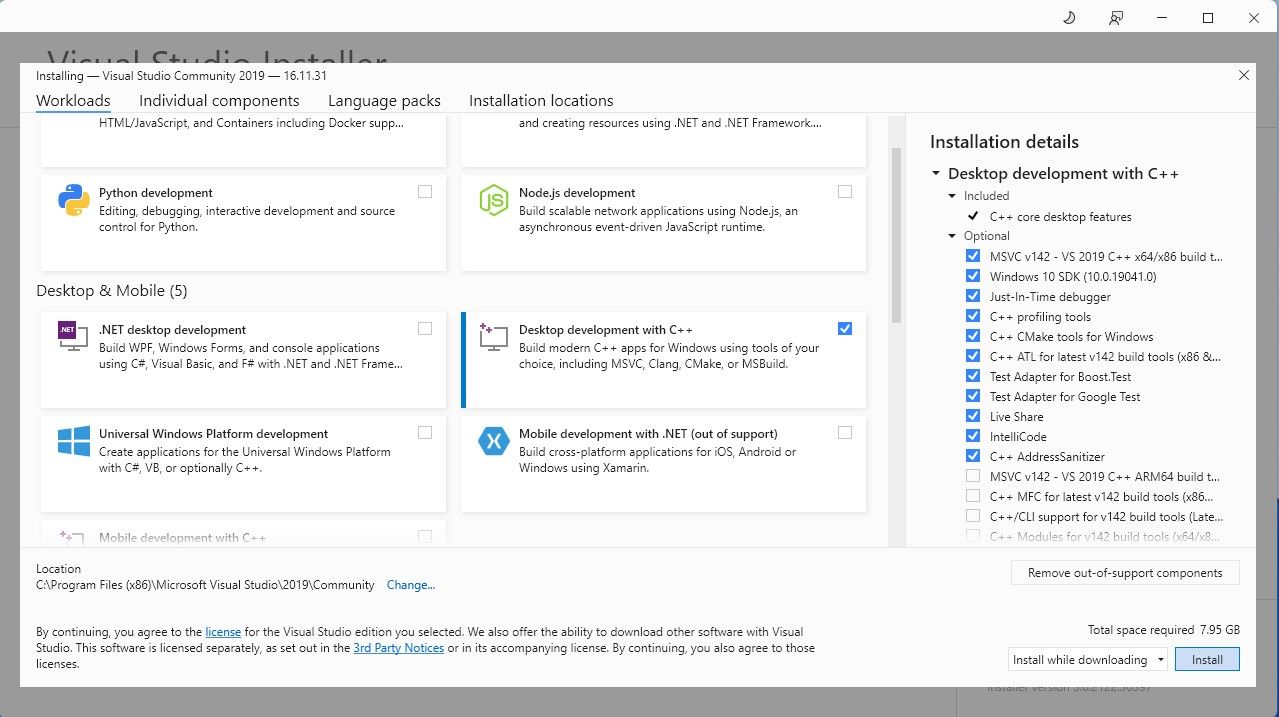
이제 C++를 사용한 데스크톱 개발이 설치되었으므로 Text-Generation-WebUI 원클릭 설치 프로그램을 다운로드할 차례입니다.
2단계: Text-Generation-WebUI 설치
Text-Generation-WebUI 원클릭 설치 프로그램은 필요한 폴더를 자동으로 생성하고 AI 모델을 실행하는 데 필요한 Conda 환경과 모든 요구 사항을 설정하는 스크립트입니다.
스크립트를 설치하려면 코드 >를 클릭하여 원클릭 설치 프로그램을 다운로드하세요. ZIP을 다운로드하세요.
다운로드:Text-Generation-WebUI 설치 프로그램(무료)
다운로드가 완료되면 원하는 위치에 ZIP 파일의 압축을 푼 다음 추출된 폴더를 엽니다. 폴더 내에서 아래로 스크롤하여 운영 체제에 적합한 시작 프로그램을 찾으십시오. 해당 스크립트를 두 번 클릭하여 프로그램을 실행합니다. Windows를 사용하는 경우 MacOS용 start_windows 배치 파일, Linux용 start_macos 쉘 스크립트, start_linux 쉘 스크립트를 선택하세요.
바이러스 백신이 경고를 생성할 수 있습니다. 이건 괜찮아. 프롬프트는 배치 파일이나 스크립트를 실행하기 위한 바이러스 백신 오탐지일 뿐입니다. 어쨌든 실행을 클릭하세요. 터미널이 열리고 설정이 시작됩니다. 초기에는 설정이 일시 중지되고 어떤 GPU를 사용하고 있는지 묻습니다. 컴퓨터에 설치된 적절한 GPU 유형을 선택하고 Enter 키를 누르세요. 전용 그래픽 카드가 없는 경우 없음(모델을 CPU 모드에서 실행하고 싶습니다)을 선택합니다. CPU 모드에서 실행하는 것은 전용 GPU로 모델을 실행하는 것과 비교할 때 훨씬 느립니다.
 설정이 완료되면 이제 Text-Generation-WebUI를 로컬에서 시작할 수 있습니다. 선호하는 웹 브라우저를 열고 제공된 IP 주소를 URL에 입력하면 됩니다.
설정이 완료되면 이제 Text-Generation-WebUI를 로컬에서 시작할 수 있습니다. 선호하는 웹 브라우저를 열고 제공된 IP 주소를 URL에 입력하면 됩니다. 이제 WebUI를 사용할 준비가 되었습니다.
이제 WebUI를 사용할 준비가 되었습니다.
그러나 프로그램은 모델 로더일 뿐입니다. 모델 로더를 실행하기 위해 Llama 2를 다운로드해 보겠습니다.
3단계: Llama 2 모델 다운로드
필요한 Llama 2 버전을 결정할 때 고려해야 할 몇 가지 사항이 있습니다. 여기에는 매개변수, 양자화, 하드웨어 최적화, 크기 및 사용량이 포함됩니다. 이 모든 정보는 모델 이름에 표시되어 있습니다.
매개변수: 모델을 훈련하는 데 사용되는 매개변수 수입니다. 매개변수가 클수록 더 유능한 모델이 만들어지지만 성능이 저하됩니다. 사용법: 표준 또는 채팅일 수 있습니다. 채팅 모델은 ChatGPT와 같은 챗봇으로 사용하기 위해 최적화되어 있으며, 표준이 기본 모델입니다. 하드웨어 최적화: 모델을 가장 잘 실행하는 하드웨어를 나타냅니다. GPTQ는 모델이 전용 GPU에서 실행되도록 최적화된 반면, GGML은 CPU에서 실행되도록 최적화되었음을 의미합니다. 양자화: 모델의 가중치 및 활성화의 정밀도를 나타냅니다. 추론의 경우 q4의 정밀도가 최적입니다. 크기: 특정 모델의 크기를 나타냅니다.일부 모델은 다르게 배열될 수 있으며 동일한 유형의 정보가 표시되지 않을 수도 있습니다. 그러나 이러한 유형의 명명 규칙은 HuggingFace 모델 라이브러리에서 매우 일반적이므로 여전히 이해할 가치가 있습니다.

이 예에서 모델은 전용 CPU를 사용하여 채팅 추론에 최적화된 130억 개의 매개변수를 훈련한 중형 Llama 2 모델로 식별할 수 있습니다.
전용 GPU에서 실행하는 경우 GPTQ 모델을 선택하고, CPU를 사용하는 경우 GGML을 선택하세요. ChatGPT와 마찬가지로 모델과 채팅하려면 채팅을 선택하세요. 그러나 모델의 모든 기능을 시험해보고 싶다면 표준 모델을 사용하세요. 매개변수의 경우, 더 큰 모델을 사용하면 성능이 저하되는 대신 더 나은 결과를 얻을 수 있다는 점을 기억하세요. 개인적으로 7B 모델로 시작하는 것이 좋습니다. 양자화의 경우 추론에만 사용되므로 q4를 사용하세요.
다운로드:GGML(무료)
다운로드:GPTQ(무료)
이제 필요한 Llama 2 반복을 알았으니 원하는 모델을 다운로드하세요.
제 경우에는 울트라북에서 실행하고 있기 때문에 채팅에 맞게 미세 조정된 GGML 모델인 llama-2-7b-chat-ggmlv3.q4_K_S.bin을 사용하겠습니다.
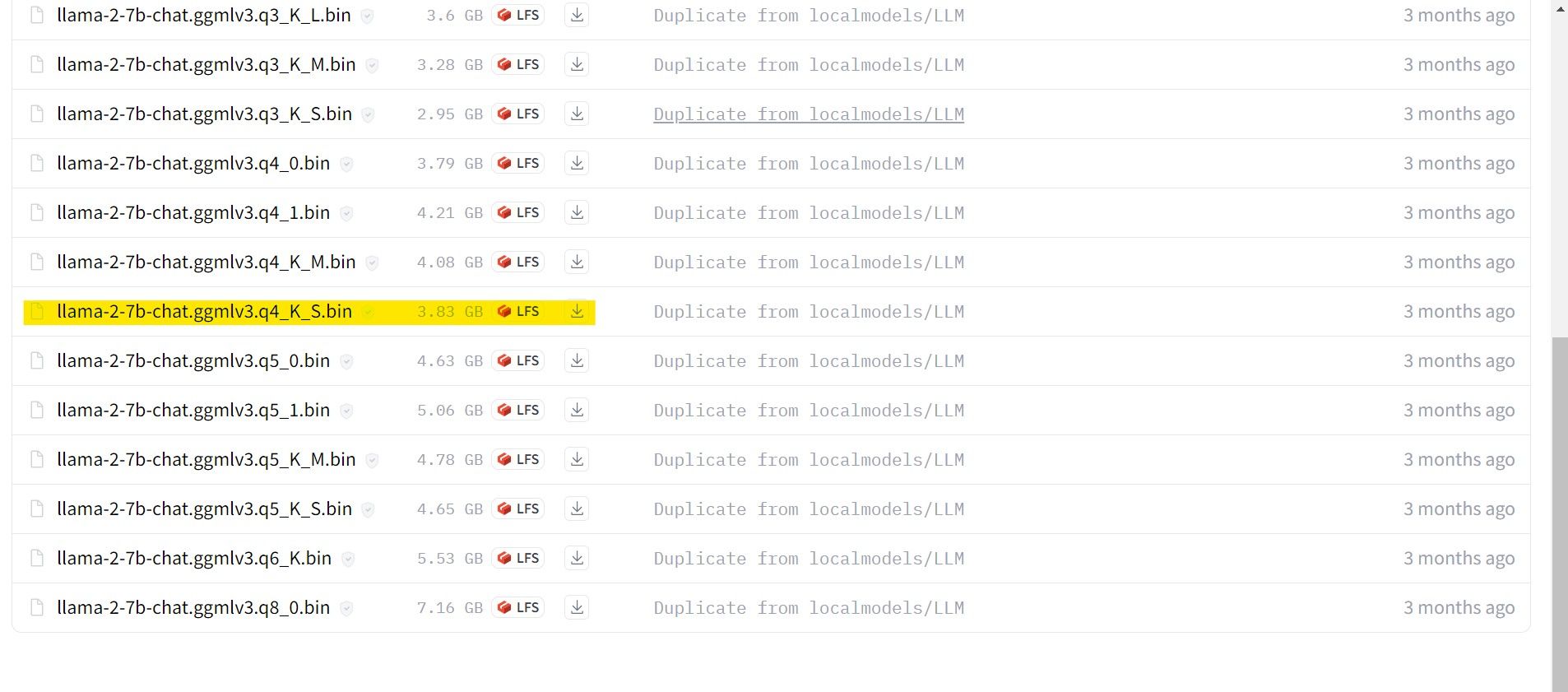
다운로드가 완료되면 모델을 text- Generation-webui-main > 모델.

이제 모델을 다운로드하여 모델 폴더에 넣었으므로 모델 로더를 구성할 차례입니다.
4단계: 텍스트 생성-WebUI 구성
이제 구성 단계를 시작하겠습니다.
다시 한 번 start_(귀하의 OS) 파일을 실행하여 Text-Generation-WebUI를 엽니다(위의 이전 단계 참조). GUI 위에 있는 탭에서 모델을 클릭합니다. 모델 드롭다운 메뉴에서 새로 고침 버튼을 클릭하고 모델을 선택하세요. 이제 모델 로더의 드롭다운 메뉴를 클릭하고 GTPQ 모델을 사용하는 경우 AutoGPTQ를 선택하고 GGML 모델을 사용하는 경우 ctransformers를 선택합니다. 마지막으로 로드를 클릭하여 모델을 로드합니다. 모델을 사용하려면 채팅 탭을 열고 모델 테스트를 시작하세요.
모델을 사용하려면 채팅 탭을 열고 모델 테스트를 시작하세요.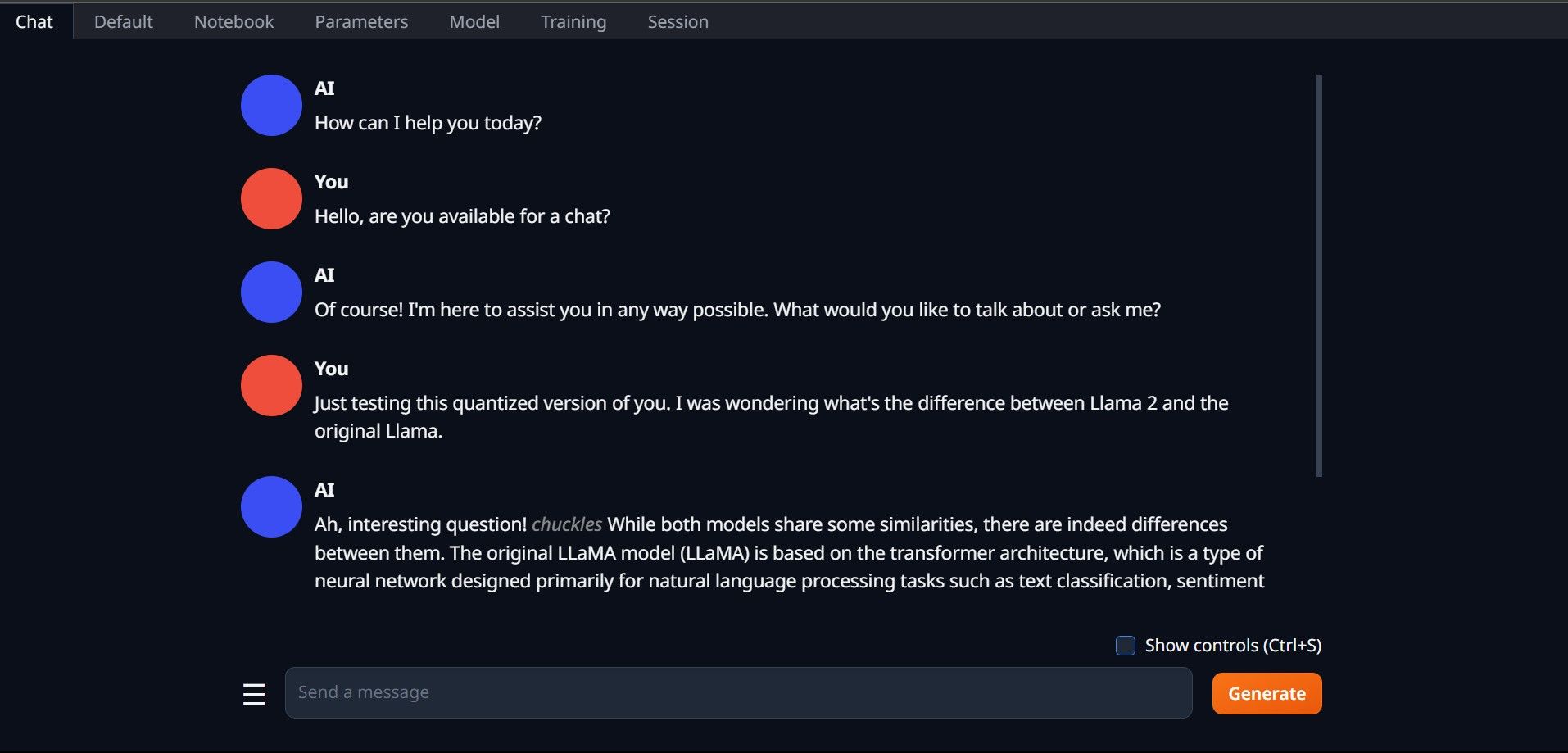
축하합니다. Llama2를 로컬 컴퓨터에 성공적으로 로드했습니다!
다른 LLM 사용해 보기
이제 Text-Generation-WebUI를 사용하여 컴퓨터에서 Llama 2를 직접 실행하는 방법을 알았으므로 Llama 외에 다른 LLM도 실행할 수 있습니다. 모델의 명명 규칙과 모델의 양자화된 버전(일반적으로 q4 정밀도)만 일반 PC에 로드할 수 있다는 점만 기억하세요. HuggingFace에서는 많은 양자화된 LLM을 사용할 수 있습니다. 다른 모델을 탐색하려면 HuggingFace의 모델 라이브러리에서 TheBloke를 검색하면 사용 가능한 많은 모델을 찾을 수 있습니다.
위 내용은 Llama 2를 로컬로 다운로드하고 설치하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!