
Yolov10: 자세한 설명, 배포, 적용이 모두 한곳에!

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB원래의
- 2024-06-07 12:05:271209검색
1. 서문
지난 몇 년 동안 YOLO는 계산 비용과 감지 성능 간의 효과적인 균형으로 인해 실시간 객체 감지 분야에서 지배적인 패러다임이 되었습니다. 연구원들은 YOLO의 아키텍처 설계, 최적화 목표, 데이터 확장 전략 등을 탐색하여 상당한 진전을 이루었습니다. 동시에 사후 처리를 위해 NMS(비최대 억제)에 의존하면 YOLO의 엔드투엔드 배포가 방해되고 추론 대기 시간에 부정적인 영향을 미칩니다.
YOLO에서는 다양한 구성 요소의 설계에 포괄적이고 철저한 검사가 부족하여 상당한 계산 중복이 발생하고 모델의 기능이 제한됩니다. 이는 최적이 아닌 효율성을 제공하며 성능 향상을 위한 상대적으로 큰 잠재력을 제공합니다. 이 작업의 목표는 사후 처리와 모델 아키텍처 모두에서 YOLO의 성능 효율성 경계를 더욱 향상시키는 것입니다. 이를 위해 우리는 먼저 경쟁력 있는 성능과 낮은 추론 지연 시간을 동시에 제공하는 NMS 없는 YOLO 교육을 위한 일관된 이중 할당을 제안합니다. 또한 YOLO의 전반적인 효율성 정확도 중심 모델 설계 전략도 소개됩니다.
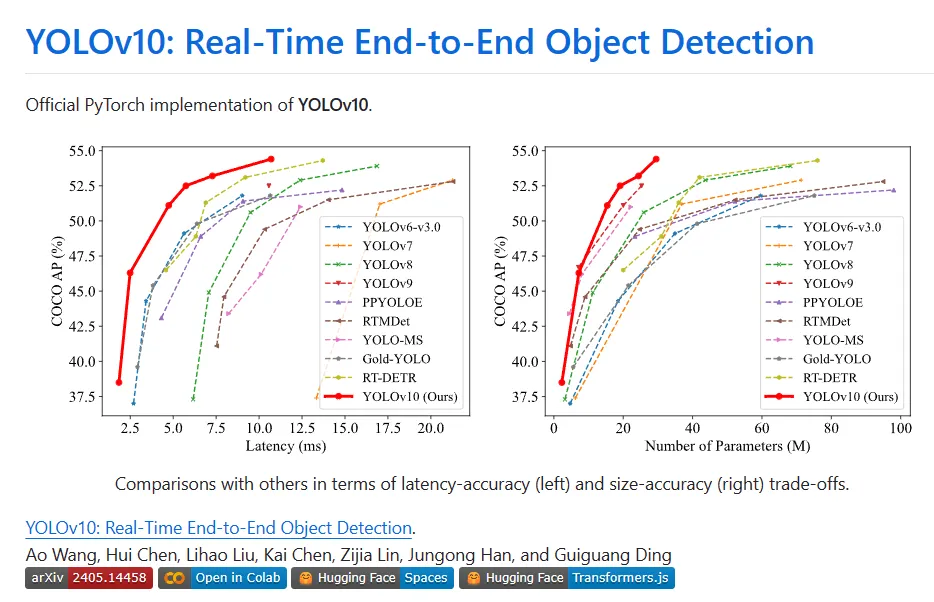
YOLO의 다양한 구성 요소는 효율성과 정확성을 향상하고 컴퓨팅 오버헤드를 크게 줄이고 기능을 향상시키는 두 가지 관점에서 완전히 최적화되었습니다. 이 작업의 결과는 YOLOv10이라고 불리는 실시간 엔드투엔드 표적 탐지를 위한 차세대 YOLO 시리즈입니다. 광범위한 실험에 따르면 YOLOv10은 다양한 모델 규모에서 최첨단 성능과 효율성을 달성합니다. 예를 들어 COCO의 유사한 AP에서 YOLOv10-Sis1.8은 RT-DETR-R18보다 1.8배 빠르며 동시에 공유되는 매개변수 및 FLOP의 수는 2.8배입니다. 동일한 성능에서 YOLOv9-C와 비교하여 YOLOv10-B는 대기 시간이 46% 감소하고 매개변수가 25% 감소했습니다.
II. Background
실시간 객체 감지는 항상 컴퓨터 비전 분야의 연구 핫스팟이었습니다. 그 목적은 짧은 지연 시간으로 이미지에 있는 객체의 카테고리와 위치를 정확하게 예측하는 것입니다. . 자율주행, 로봇 내비게이션, 객체 추적 등 다양한 실무 응용 분야에 널리 사용됩니다. 최근 몇 년 동안 연구자들은 실시간 감지를 달성하기 위해 CNN 기반 객체 감지기를 설계하는 데 중점을 두었습니다. 실시간 물체 감지기는 단일 단계 감지기와 2단계 감지기의 두 가지 범주로 나눌 수 있습니다. 단일 단계 감지기는 입력 이미지에 대해 직접 조밀한 예측을 수행하는 반면, 2단계 감지기는 먼저 후보 상자를 생성한 다음 이러한 후보 상자에 대해 분류 및 위치 회귀를 수행합니다.
그 중에서도 YOLO는 성능과 효율성 사이의 영리한 균형으로 인해 점점 더 인기를 얻고 있습니다. YOLO의 탐지 파이프라인은 모델 전달 처리와 NMS 사후 처리의 두 부분으로 구성됩니다. 그러나 두 방법 모두 여전히 단점이 있어 정확도와 지연 시간 한계가 최적이 아닙니다. 특히 YOLO는 일반적으로 훈련 중에 하나의 기본 구현 개체가 여러 샘플 책에 해당하는 일대다 레이블 할당 전략을 채택합니다. 뛰어난 성능을 제공함에도 불구하고 이 접근 방식에서는 NMS가 추론 중에 가장 긍정적인 예측을 선택해야 합니다. 이로 인해 추론 속도가 느려지고 성능이 NMS의 하이퍼파라미터에 민감해져서 YOLO가 최적의 엔드투엔드 배포를 달성하지 못하게 됩니다. 이 문제를 해결하는 한 가지 방법은 최근 도입된 엔드투엔드 DETR 아키텍처를 채택하는 것입니다. 예를 들어, RT-DETR은 불확실성을 최소화하면서 효율적인 하이브리드 인코더 및 쿼리 선택을 제공하여 DETR을 실시간 애플리케이션에 적용합니다. 그러나 DETR 배포의 본질적인 복잡성으로 인해 정확성과 속도 간의 최적의 균형을 달성하는 능력이 방해를 받습니다. 또 다른 라인에서는 중복 예측을 억제하기 위해 일반적으로 일대일 할당 전략을 활용하는 CNN 기반 감지기의 엔드투엔드 감지를 탐구합니다.
그러나 추가 추론 오버헤드를 도입하거나 최적이 아닌 성능을 달성하는 경우가 많습니다. 또한 모델 아키텍처 설계는 정확성과 속도에 큰 영향을 미치는 YOLO의 근본적인 과제로 남아 있습니다. 보다 효율적이고 효과적인 모델 아키텍처를 달성하기 위해 연구자들은 다양한 설계 전략을 모색했습니다. 특징 추출 기능을 향상시키기 위해 DarkNet, CSPNet, EfficientRep 및 ELAN을 포함한 다양한 주요 컴퓨팅 장치가 백본에 제공됩니다. 목 부분에서는 PAN, BiC, GD, RepGFPN 등을 연구하여 Multi-Scale Feature 융합을 향상시켰습니다. 또한 모델 확장 전략과 재매개변수화 기술을 조사합니다. 이러한 노력이 상당한 진전을 이루었지만 여전히 효율성과 정확성 측면에서 YOLO의 다양한 구성 요소를 포괄적으로 검토할 여지가 있습니다. 따라서 모델을 제한하는 결과적인 기능은 성능 차등으로 이어져 정확도 향상을 위한 충분한 여지를 남겨줍니다.
3. 신기술
NMS 없는 교육을 위한 일관된 이중 과제
훈련 중에 YOLO는 일반적으로 TAL을 활용하여 인스턴스당 여러 개의 양성 샘플을 할당합니다. 일대다 할당을 채택하면 우수한 성능을 최적화하고 달성하는 데 도움이 되는 풍부한 모니터링 신호가 생성됩니다. 그러나 YOLO는 NMS 후처리에 의존해야 하므로 배포 추론 효율성이 만족스럽지 않습니다. 이전 연구에서는 중복 예측을 억제하기 위해 일대일 일치를 탐색했지만 종종 추가 추론 오버헤드를 도입하거나 차선의 성능을 생성합니다. 이 작업에서 YOLO는 이중 라벨 할당 및 일관된 매칭 측정항목을 통해 NMS 없는 교육 전략을 제공하여 높은 효율성과 경쟁력 있는 성능을 달성합니다.
- 이중 라벨 할당
일대다 할당과 달리 일대일 일치는 NMS에 의한 사후 처리를 방지하여 각 실제 진실에 하나의 예측만 할당합니다. . 그러나 감독이 제대로 이루어지지 않아 정확도와 수렴 속도가 최적화되지 않습니다. 다행히도 일대다 할당을 통해 이러한 결함을 해결할 수 있습니다. 이를 달성하기 위해 YOLO는 두 전략의 장점을 결합하는 이중 라벨 할당을 도입합니다. 구체적으로는 아래 그림(a)와 같다.
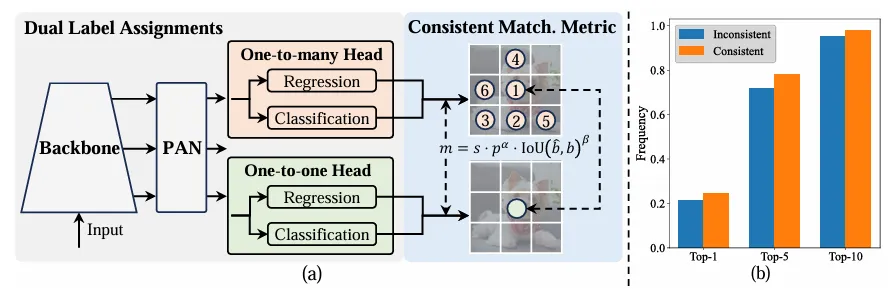
YOLO의 또 다른 일대일 헤더를 소개합니다. 이는 원래의 일대다 분기와 동일한 구조를 유지하고 동일한 최적화 목표를 채택하지만 일대일 일치를 활용하여 레이블 할당을 얻습니다. 훈련 과정에서 두 개의 머리가 모델과 함께 최적화되어 백본과 목이 일대다 작업을 통해 제공되는 풍부한 감독을 즐길 수 있습니다. 추론 중에는 일대다 헤더가 삭제되고 일대일 헤더가 예측에 활용됩니다. 이를 통해 추가 추론 비용을 발생시키지 않고 YOLO를 엔드 투 엔드로 배포할 수 있습니다. 또한 일대일 매칭에서는 이전 선택을 채택하여 추가 훈련 시간을 적게 들여 헝가리어 매칭과 동일한 성능을 달성합니다.
- 일관된 일치 측정항목
할당 프로세스 중에 일대일 및 일대다 방법 모두 측정항목을 사용하여 예측과 인스턴스 간의 일관성 수준을 정량적으로 평가합니다. 두 분기의 예측 인식 일치를 달성하기 위해 통합 일치 측정항목이 사용됩니다.
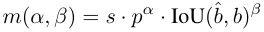
이중 레이블 할당에서 일대다 분기는 일대일 분기보다 풍부한 모니터링 신호를 제공합니다. 직관적으로 일대일 헤더 감독이 일대다 헤더 감독과 조화를 이룰 수 있다면 일대일 헤더 최적화 방향으로 일대일 헤더를 최적화할 수 있습니다. 따라서 일대일 헤드는 추론 중에 향상된 샘플 품질을 제공하여 더 나은 성능을 제공할 수 있습니다. 이를 위해 먼저 둘 사이의 규제 격차를 분석한다. 훈련 과정의 무작위성으로 인해 동일한 값으로 초기화된 두 개의 헤드로 검사를 시작하고 동일한 예측을 생성합니다. 즉, 일대일 헤드와 일대다 헤드는 예측된 각 헤드에 대해 동일한 결과를 생성합니다. 인스턴스 쌍 p와 IoU. 두 가지 모두에 대한 회귀 목표를 기록해 두십시오.
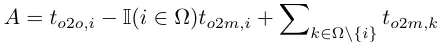
2m일 때 i=u*에 도달하면 위의 (a)와 같이 i가 Ω 단위의 가장 좋은 양성 샘플입니다. 이를 달성하기 위해 일관된 매칭 메트릭, 즉 αo2o=r·αo2m 및 βo2o=r·βo2m이 제안되며 이는 mo2o=mro2m을 의미합니다. 따라서 일대다 머리에 대한 가장 좋은 양성 샘플은 일대일 머리에도 가장 좋은 샘플입니다. 결과적으로 두 헤드 모두 일관되고 조화롭게 최적화될 수 있습니다. 단순화를 위해 기본적으로 r=1, 즉 αo2o=αo2m 및 βo2o=βo2m이 사용됩니다. 개선된 감독 정렬을 확인하기 위해 훈련 후 일대다 결과의 처음 1/5/10 내에서 일대일 일치 쌍의 수가 계산됩니다. 위의 (b)에서 볼 수 있듯이 일관된 매칭 방법을 사용하면 정렬이 향상됩니다.
제한된 공간으로 인해 YOLOv10의 주요 혁신은 이중 레이블 할당 전략을 도입하는 것입니다. 핵심 아이디어는 일대다 감지 헤드를 사용하여 훈련 단계에서 더 많은 긍정적인 샘플을 제공하여 모델을 강화하는 것입니다. . 추론 단계에서는 그라디언트 잘림을 사용하여 일대일 감지 헤드로 전환하므로 NMS 후처리가 필요하지 않아 추론 오버헤드가 줄어듭니다. 원리는 실제로 어렵지 않습니다. 코드를 보면 이해할 수 있습니다.
#https://github.com/THU-MIG/yolov10/blob/main/ultralytics/nn/modules/head.pyclass v10Detect(Detect):max_det = -1def __init__(self, nc=80, ch=()):super().__init__(nc, ch)c3 = max(ch[0], min(self.nc, 100))# channelsself.cv3 = nn.ModuleList(nn.Sequential(nn.Sequential(Conv(x, x, 3, g=x), Conv(x, c3, 1)), \ nn.Sequential(Conv(c3, c3, 3, g=c3), Conv(c3, c3, 1)), \nn.Conv2d(c3, self.nc, 1)) for i, x in enumerate(ch))self.one2one_cv2 = copy.deepcopy(self.cv2)self.one2one_cv3 = copy.deepcopy(self.cv3)def forward(self, x):one2one = self.forward_feat([xi.detach() for xi in x], self.one2one_cv2, self.one2one_cv3)if not self.export:one2many = super().forward(x)if not self.training:one2one = self.inference(one2one)if not self.export:return {'one2many': one2many, 'one2one': one2one}else:assert(self.max_det != -1)boxes, scores, labels = ops.v10postprocess(one2one.permute(0, 2, 1), self.max_det, self.nc)return torch.cat([boxes, scores.unsqueeze(-1), labels.unsqueeze(-1)], dim=-1)else:return {'one2many': one2many, 'one2one': one2one}def bias_init(self):super().bias_init()'''Initialize Detect() biases, WARNING: requires stride availability.'''m = self# self.model[-1]# Detect() module# cf = torch.bincount(torch.tensor(np.concatenate(dataset.labels, 0)[:, 0]).long(), minlength=nc) + 1# ncf = math.log(0.6 / (m.nc - 0.999999)) if cf is None else torch.log(cf / cf.sum())# nominal class frequencyfor a, b, s in zip(m.one2one_cv2, m.one2one_cv3, m.stride):# froma[-1].bias.data[:] = 1.0# boxb[-1].bias.data[: m.nc] = math.log(5 / m.nc / (640 / s) ** 2)# cls (.01 objects, 80 classes, 640 img)Holistic Efficiency-Accuracy Driven Model Design
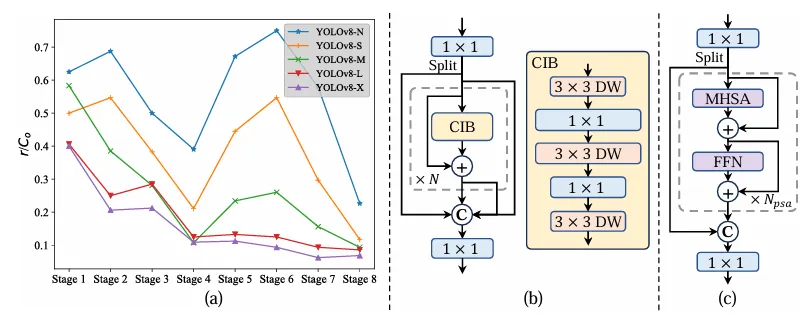
架构改进:
- Backbone & Neck:使用了先进的结构如 CSPNet 作为骨干网络,和 PAN 作为颈部网络,优化了特征提取和多尺度特征融合。
- 大卷积核与分区自注意力:这些技术用于增强模型从大范围上下文中学习的能力,提高检测准确性而不显著增加计算成本。
- 整体效率:引入空间-通道解耦下采样和基于秩引导的模块设计,减少计算冗余,提高整体模型效率。
四、实验
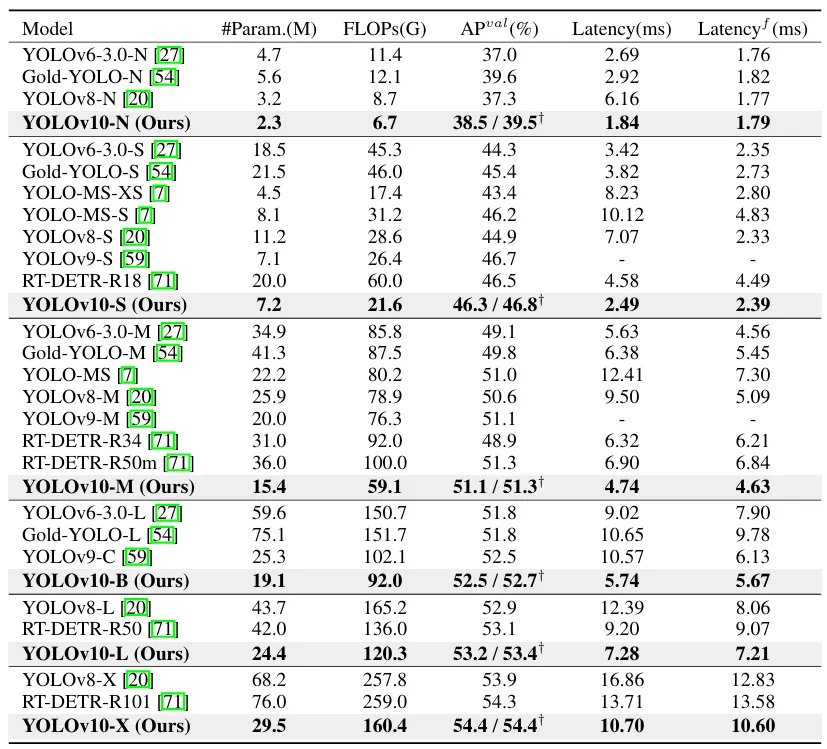
与最先进的比较。潜伏性是通过官方预训练的模型来测量的。潜在的基因测试在具有前处理的模型的前处理中保持了潜在性。†是指YOLOv10的结果,其本身对许多训练NMS来说都是如此。以下是所有结果,无需添加先进的训练技术,如知识提取或PGI或公平比较:

五、部署测试
首先,按照官方主页将环境配置好,注意这里 python 版本至少需要 3.9 及以上,torch 版本可以根据自己本地机器安装合适的版本,默认下载的是 2.0.1:
conda create -n yolov10 pythnotallow=3.9conda activate yolov10pip install -r requirements.txtpip install -e .
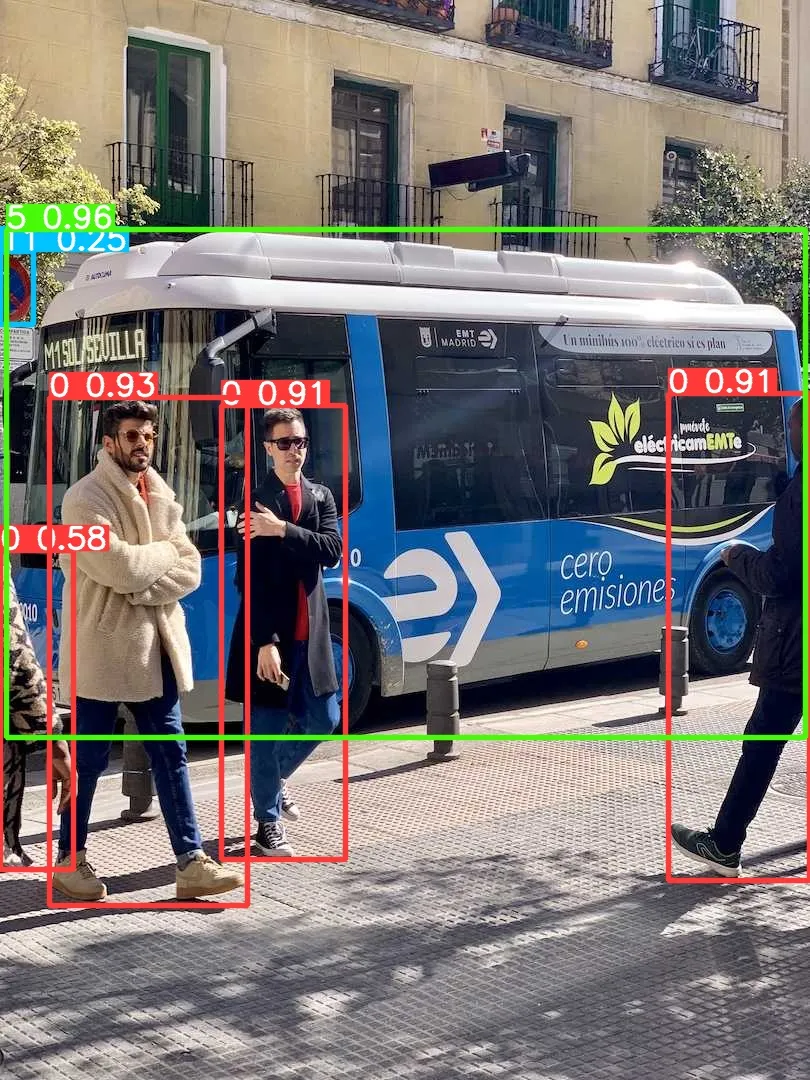
安装完成之后,我们简单执行下推理命令测试下效果:
yolo predict model=yolov10s.pt source=ultralytics/assets/bus.jpg
让我们尝试部署一下,譬如先导出个 onnx 模型出来看看:
yolo export model=yolov10s.pt format=onnx opset=13 simplify
好了,接下来通过执行 pip install netron 安装个可视化工具来看看导出的节点信息:
# run python fisrtimport netronnetron.start('/path/to/yolov10s.onnx')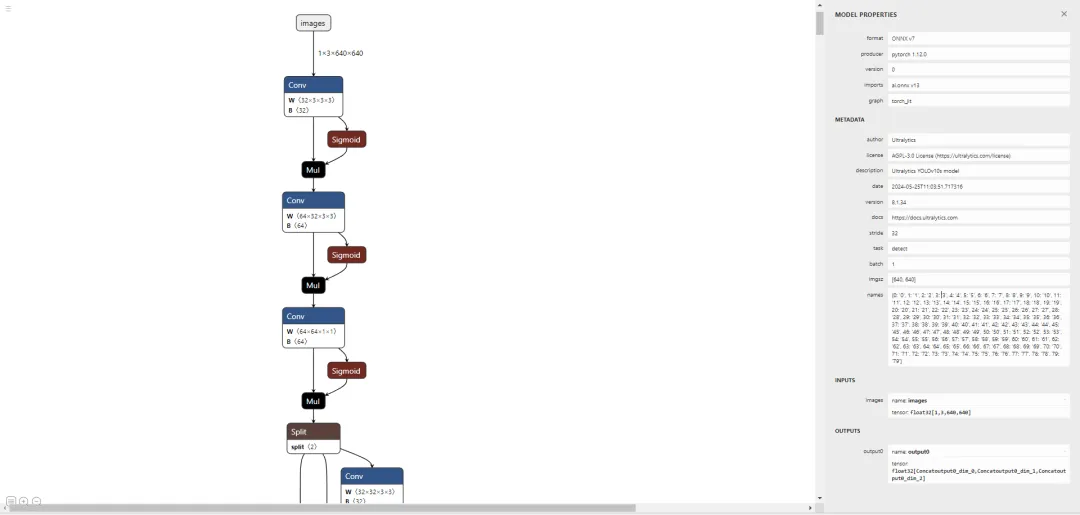
先直接通过 Ultralytics 框架预测一个测试下能否正常推理:
yolo predict model=yolov10s.onnx source=ultralytics/assets/bus.jpg

大家可以对比下上面的运行结果,可以看出 performance 是有些许的下降。问题不大,让我们基于 onnxruntime 写一个简单的推理脚本,代码地址如下,有兴趣的可以自行查看:
# 推理脚本https://github.com/CVHub520/X-AnyLabeling/blob/main/tools/export_yolov10_onnx.py# onnx 模型权重https://github.com/CVHub520/X-AnyLabeling/releases/tag/v2.3.6

위 내용은 Yolov10: 자세한 설명, 배포, 적용이 모두 한곳에!의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!