AIxiv 칼럼은 본 사이트에서 학술 및 기술 콘텐츠를 게재하는 칼럼입니다. 지난 몇 년 동안 이 사이트의 AIxiv 칼럼에는 전 세계 주요 대학 및 기업의 최고 연구실을 대상으로 한 2,000개 이상의 보고서가 접수되어 학술 교류 및 보급을 효과적으로 촉진하고 있습니다. 공유하고 싶은 훌륭한 작품이 있다면 자유롭게 기여하거나 보고를 위해 연락주시기 바랍니다. 제출 이메일: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
Richard Sutton은 "The Bitter Lesson"에서 다음과 같이 평가했습니다. "70년간의 인공 지능 연구에서 도출할 수 있는 최고의 결론은 중요한 교훈은 계산을 활용하는 일반적인 방법이 궁극적으로 가장 효율적이며 이점이 크다는 것입니다. "자기 놀이는 계산을 완전히 활용하고 확장하기 위해 검색과 학습을 모두 사용하는 방법 중 하나입니다. . 올해 초, UCLA(UCLA) Gu Quanquan 교수 팀은 추가적인 미세 조정 데이터를 사용하지 않는 Self-Play Fine-Tuning, SPIN)
을 제안했습니다. 게임은 LLM의 기능을 크게 향상시킬 수 있습니다.
최근 카네기 멜론 대학(CMU)의 Gu Quanquan 교수 팀과 양이밍 교수 팀이 협력하여 "Self-Play Preference Optimization(SPPO)
"이라는 방법을 개발했습니다. 이 새로운 방법은 최적화를 목표로 합니다. 인간의 선호도에 더 잘 일치하도록 자체 게임 프레임워크를 통해 대규모 언어 모델의 동작을 구현합니다. 왼쪽에서 오른쪽으로 서로 싸우며 다시 마법의 힘을 과시하세요!
 논문 제목: 언어 모델 정렬을 위한 자체 재생 기본 설정 최적화
논문 제목: 언어 모델 정렬을 위한 자체 재생 기본 설정 최적화
- 논문 링크: https://arxiv.org/pdf/2405.00675.pdf
-
기술 배경 및 과제
대형 언어 모델(LLM)은 뛰어난 텍스트 생성 및 이해 능력으로 다양한 작업을 잘 수행하며 인공지능 분야의 중요한 원동력이 되고 있습니다. LLM의 기능은 인상적이지만 이러한 모델의 출력 동작을 실제 응용 프로그램의 요구 사항과 보다 일관되게 만들려면 정렬 프로세스를 통해 미세 조정이 필요한 경우가 많습니다. 이 프로세스의 핵심은 인간의 선호도와 행동 규범을 더 잘 반영하도록 모델을 조정하는 것입니다. 일반적인 방법에는 인간 피드백(RLHF)을 기반으로 한 강화 학습 또는 직접 선호도 최적화(Direct Preference Optimization, DPO)가 있습니다. 인간 피드백 기반 강화 학습(RLHF)은 보상 모델을 명시적으로 유지하여 대규모 언어 모델을 조정하고 개선하는 데 의존합니다. 즉, 예를 들어 InstructGPT는 먼저 인간 선호도 데이터를 기반으로 Bradley-Terry 모델을 따르는 보상 함수를 훈련한 다음 PPO(Proximal Policy Optimization)와 같은 강화 학습 알고리즘을 사용하여 대규모 언어 모델을 최적화합니다. 작년에 연구자들은 DPO(Direct Preference Optimization)를 제안했습니다. 명시적 보상 모델을 유지하는 RLHF와 달리 DPO 알고리즘은 암묵적으로 Bradley-Terry 모델을 따르지만 대규모 언어 모델 최적화에 직접 사용할 수 있습니다. 기존 작업에서는 DPO를 여러 번 반복하여 대규모 모델을 더욱 세부적으로 조정하려고 시도했습니다(그림 1). ㅋㅋ ~ 숫자 점수. 이러한 모델은 인간 선호도에 대한 합리적인 근사치를 제공하지만 인간 행동의 복잡성을 완전히 포착하지는 못합니다. 이러한 모델은 다양한 선택 간의 선호 관계가 단조롭고 전이적이라고 가정하는 경우가 많지만, 경험적 증거는 종종 인간 의사 결정의 비일관성과 비선형성을 보여줍니다. 예를 들어 Tversky의 연구에서는 인간의 의사 결정이 영향을 받을 수 있다는 것을 관찰했습니다. 다양한 요인이 영향을 미치고 불일치를 나타냅니다.
SPPO
의 이론적 근거와 방법两 그림 2. 상상의 두 가지 언어 모델이 자주 재생되고 재생됩니다.
이러한 맥락에서 저자는 새로운 자체 게임 프레임워크 SPPO를 제안합니다. SPPO는 2인용 불변 합계 게임을 해결하기 위한 입증 가능한 보장을 제공할 뿐만 아니라 효율적으로 미세 조정되는 대규모 언어 모델을 제공합니다. 대규모로 확장됩니다.
구체적으로 이 기사에서는 RLHF 문제를 2인 정규합 게임으로 엄격하게 정의합니다(그림 2). 이 작업의 목표는 평균적으로 항상 다른 전략보다 더 선호되는 반응을 제공하는 내쉬 균형 전략을 식별하는 것입니다.
내쉬 균형 전략을 대략적으로 식별하기 위해 저자는 2인 게임을 해결하기 위한 고급 프레임워크 알고리즘으로 곱셈 가중치를 갖는 고전적인 온라인 적응 알고리즘을 채택합니다.
이 프레임워크의 각 단계 내에서 알고리즘은 자체 게임 메커니즘을 통해 곱셈 가중치 업데이트를 근사화할 수 있습니다. 여기서 각 라운드에서 대규모 언어 모델은 모델 Synthesize에 의해 생성된 이전 라운드에 대해 자체적으로 미세 조정됩니다. 최적화를 위한 데이터 및 선호 모델 주석.
특히, 대규모 언어 모델은 선호도 모델의 주석을 기반으로 각 라운드의 각 프롬프트에 대해 여러 응답을 생성하며 이를 통해 알고리즘은 각 응답의 승률을 추정할 수 있습니다. 매개변수는 높은 승률을 가진 응답이 나타날 확률을 더 높게 만듭니다(그림 3).
실험 설계 및 결과실험에서 연구팀은 Mistral-7B를 기준 모델로 채택하고 UltraFeedback의 60,000개 프롬프트를 사용했습니다. 비지도 학습을 위한 데이터 세트입니다. 그들은 자체 플레이를 통해 모델이 AlpacaEval 2.0 및 MT-Bench와 같은 여러 평가 플랫폼에서 성능을 크게 향상시킬 수 있음을 발견했습니다. 이러한 플랫폼은 모델 생성 텍스트의 품질과 관련성을 평가하는 데 널리 사용됩니다. SPPO 방법을 통해 모델은 생성된 텍스트의 유창성 및 정확성
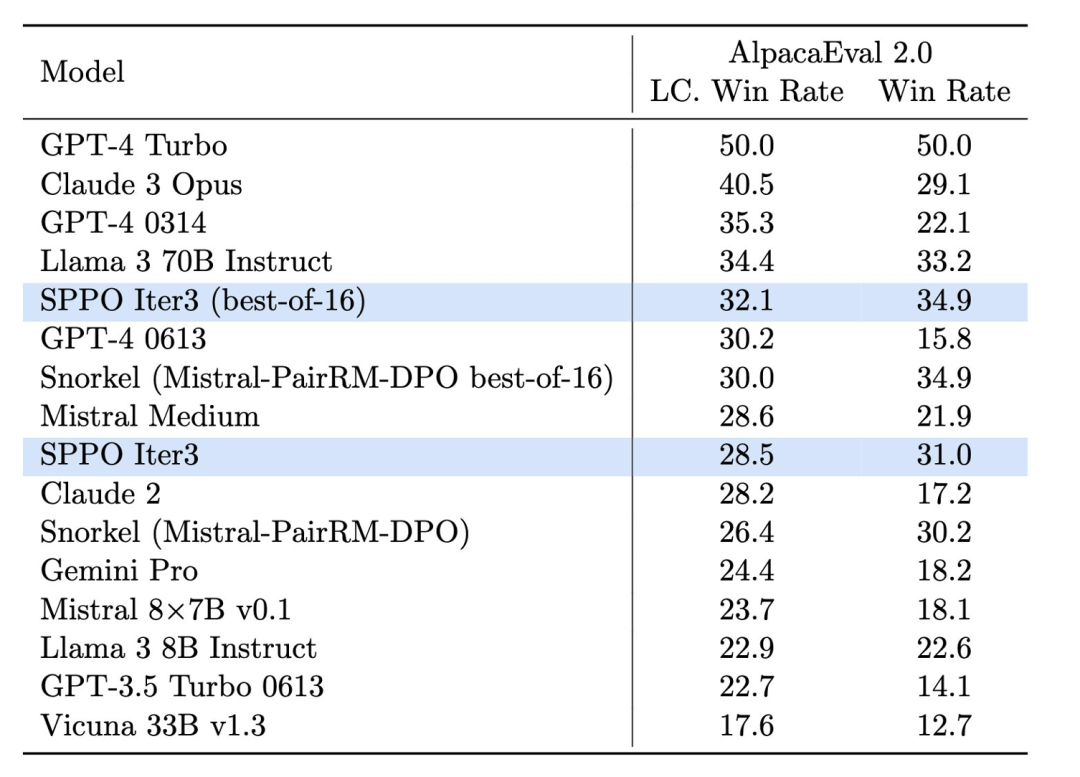
이 향상될 뿐만 아니라 더 중요하게는 "인간의 가치와 선호도에 더 잘 부합합니다." O 그림 4. Alpacaeval 2.0에서 sppo 모델의 효과가 크게 향상되었으며 ITERATIVE DPO와 같은 다른 벤치마크 방법보다 높습니다.
AlpacaEval 2.0 테스트(그림 4)에서 SPPO 최적화 모델은 기준 모델의 17.11%에서 28.53%로 길이 제어 승률을 향상시켜 인간 선호도에 대한 이해가 크게 향상되었습니다. . SPPO의 3라운드에 의해 최적화된 모델은 AlpacaEval2.0의 DPO, IPO 및 자기 보상 언어 모델(Self-Rewarding LM)의 다중 라운드 반복보다 훨씬 우수합니다.
또한 MT-Bench에서의 모델 성능도 인간의 피드백을 통해 조정된 기존 모델을 능가했습니다. 이는 모델 동작을 복잡한 작업에 자동으로 적용하는 SPPO의 효율성을 보여줍니다.
결론 및 향후 전망
SPPO(Self-Playing Preference Optimization)는 대규모 언어 모델에 대한 새로운 최적화 경로를 제공합니다. 이는 모델 생성의 품질을 향상시킬 뿐만 아니라 더 중요하게는 모델의 품질은 인간의 선호도와 일치합니다.
지속적인 기술 개발과 최적화를 통해 SPPO와 파생 기술은 인공 지능의 지속 가능한 개발과 사회적 적용에서 더 큰 역할을 수행하여 보다 지능적이고 책임감 있는 AI 시스템을 구축할 수 있는 길을 열 것으로 예상됩니다. . 위 내용은 인간의 취향이 지배자입니다! SPPO 정렬 기술을 사용하면 대규모 언어 모델이 서로 경쟁하고 스스로 경쟁할 수 있습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!



 논문 제목: 언어 모델 정렬을 위한 자체 재생 기본 설정 최적화
논문 제목: 언어 모델 정렬을 위한 자체 재생 기본 설정 최적화