


대형 모델의 물결 속에서 최첨단 밀집 세트 LLM을 교육하고 배포하는 것은 특히 수백억 또는 수천억 개의 매개변수 규모에서 계산 요구 사항 및 관련 비용 측면에서 큰 과제를 안겨줍니다. 이러한 과제를 해결하기 위해 전문가 혼합(MoE) 모델과 같은 희소 모델이 점점 더 중요해지고 있습니다. 이러한 모델은 리소스 요구 사항이 매우 낮은 밀집된 세트 모델의 성능과 일치하거나 심지어 그 성능을 초과할 가능성이 있는 다양한 특수 하위 모델 또는 "전문가"에게 계산을 분산함으로써 경제적으로 실행 가능한 대안을 제공합니다.
6월 3일, 오픈 소스 대형 모델 분야에서 또 다른 중요한 소식이 전해졌습니다. Kunlun Wanwei는 강력한 성능을 유지하면서 추론 비용을 대폭 절감하는 2000억 개의 희소 대형 모델 Skywork-MoE의 오픈 소스를 발표했습니다.
Kunlun Wanwei의 이전 오픈 소스 Skywork-13B 모델 중간 체크포인트를 기반으로 확장되었습니다. 이는 MoE 업사이클링 기술을 완전히 적용하고 구현하는 최초의 오픈 소스 1000억 MoE 대형 모델이기도 합니다. 단일 4090 서버. 수십억 개의 MoE 대형 모델.
대규모 모델 커뮤니티에서 더욱 주목을 끄는 점은 Skywork-MoE의 모델 가중치 및 기술 보고서가 완전히 오픈 소스이며 상업적 용도로 무료이며 애플리케이션이 필요하지 않다는 것입니다.
모델 체중 다운로드 주소 :
○ https://huggingface.co/Skywork/Skywork-MoE-base
○ https://huggingface.co/Skywork/Skywork-MoE-Base-FP8
모델 오픈 소스 웨어하우스: https://github.com/SkyworkAI/Skywork-MoE
모델 기술 보고서: https://github.com/SkyworkAI/Skywork-MoE/blob/main/skywork-moe - tech-report.pdf
모델 추론 코드: (8x4090 서버에서 8비트 양자화 로드 추론 지원) https://github.com/SkyworkAI/vllm
Skywork-MoE는 현재 다음을 추론할 수 있습니다. 8x4090 서버 최대 규모의 오픈 소스 MoE 모델입니다. 8x4090 서버에는 총 192GB의 GPU 메모리가 있습니다. Kunlun Wanwei 팀이 개척한 비균일 Tensor 병렬 추론 방법을 사용하여 FP8 양자화(무게는 146GB를 차지함)에서 Skywork-MoE는 적합한 범위 내에서 초당 2200개의 토큰에 도달할 수 있습니다. 배치 크기.
전체 관련 추론 프레임워크 코드 및 설치 환경은 https://github.com/SkyworkAI/Skywork-MoE
Skywork-MoE Introduction
이 오픈 소스 Skywork-MoE 모델에 속합니다. Tiangong 3.0 R&D 모델 시리즈는 중급 모델(Skywork-MoE-Medium)로 모델의 총 매개변수 양은 146B, 활성화 매개변수 양은 22B이며 각 전문가 크기는 총 16개입니다. , 그리고 매번 2개씩 활성화됩니다.
Tiangong 3.0은 이 오픈 소스에 포함되지 않은 75B(Skywork-MoE-Small) 및 400B(Skywork-MoE-Large)라는 두 가지 MoE 모델도 훈련한 것으로 이해됩니다.
Kunlun Wanwei는 주요 주류 모델의 현재 평가 목록을 기반으로 Skywork-MoE를 평가했습니다. 동일한 활성화 매개변수 금액 20B(추론 계산 금액)에서 Skywork-MoE의 기능은 70B 밀도에 가까운 업계 최전선에 있습니다. 모델. 이를 통해 모델의 추론 비용이 거의 3배 감소합니다.

Skywork-MoE의 전체 매개변수 크기가 DeepSeekV2의 전체 매개변수 크기보다 1/3 작아서 더 작은 매개변수 크기로 유사한 기능을 달성한다는 점은 주목할 가치가 있습니다.
기술 혁신
어려운 MoE 모델 훈련과 열악한 일반화 성능 문제를 해결하기 위해 Skywork-MoE는 두 가지 훈련 최적화 알고리즘을 설계했습니다.
Gating Logits 정규화 작업
Skywork-MoE in Gating 정규화 작업이 레이어의 토큰 배포 논리에 추가되어 게이팅 레이어의 매개변수 학습이 선택된 상위 2개 전문가에게 더욱 기울어지고 상위 2개 전문가에 대한 MoE 모델의 신뢰도가 높아집니다.
 적응형 보조 손실
적응형 보조 손실
은 고정 계수(고정 하이퍼파라미터)를 사용하는 기존 보조 손실과 다릅니다. Skywork-MoE를 사용하면 모델이 MoE 교육의 여러 단계에서 적절한 보조 손실 하이퍼파라미터 계수를 적응적으로 선택할 수 있으므로 드롭 토큰 비율을 다음으로 유지할 수 있습니다. 적절한 구간을 설정하면 전문가 분포의 균형을 맞추고 전문가 학습을 차별화할 수 있어 모델의 전반적인 성능과 일반화 수준이 향상됩니다. MoE 훈련 초기에는 매개변수 학습이 부족하여 토큰 드롭 비율이 너무 높습니다(토큰 분배 차이가 너무 큼). 이때 나중에 토큰 로드 밸런싱을 돕기 위해 더 큰 보조 손실이 필요합니다. MoE 교육 단계에서 Skywork-MoE 팀은 토큰을 무작위로 배포하는 Gating의 경향을 피하기 위해 전문가 간에 어느 정도의 차별화가 여전히 보장되므로 수정을 줄이기 위해 더 낮은 보조 손실이 필요하기를 바랍니다.

Training Infra
MoE 모델의 대규모 분산 교육을 효율적으로 수행하는 방법은 어려운 과제입니다. Skywork-MoE는 킬로칼로리 클러스터에서 MFU의 38% 훈련 처리량을 달성하기 위해 두 가지 중요한 병렬 최적화 설계를 제안합니다. 여기서 MFU는 활성화 매개변수 22B를 사용하여 이론적 계산 부하를 계산합니다.
전문 데이터 병렬
Megatron-LM 커뮤니티의 기존 EP(Expert Parallel) 및 ETP(Expert Tensor Parallel) 설계와 달리 Skywork-MoE 팀은 Expert Data Parallel이라는 병렬 설계 솔루션을 제안했습니다. 숫자가 작아도 모델을 효율적으로 분할할 수 있으며 Expert가 도입한 all2all 커뮤니케이션도 최대한 최적화하고 마스킹할 수 있습니다. GPU 수에 대한 EP의 제한과 킬로 카드 클러스터에 대한 ETP의 비효율성과 비교할 때 EDP는 대규모 분산 교육 MoE의 병렬 문제점을 더 잘 해결할 수 있습니다. 동시에 EDP의 디자인은 간단하고 강력하며 확장하기 쉽습니다. 빠른 구현 및 검증이 가능합니다. E 가장 간단한 EDP 예 중 하나, TP = 2, 2개의 카드의 경우 EP = 2, Attention 부분은 Tensor Parallel을 사용하고 Expert 부분은 Expert Parallel

비균일 절삭수 평행수 평행을 사용 water 첫 번째 단계의 Embedding 계산과 마지막 단계의 Loss 계산, 파이프라인 버퍼의 존재로 인해 각 단계의 컴퓨팅 부하와 비디오 메모리 부하에 불균형이 발생합니다. 레이어는 파이프라인 병렬 처리에 따라 균등하게 나뉩니다. Skywork-MoE 팀은 전체 컴퓨팅/그래픽 메모리 부하의 균형을 맞추고 종단 간 훈련 처리량을 약 10% 향상시키기 위해 비균일 파이프라인 병렬 분할 및 재계산 레이어 할당 방법을 제안했습니다.
균일 분할과 비균일 분할 하의 파이프라인 병렬 버블 비교: 24레이어 LLM의 경우 (a)는 4단계로 균등하게 나뉘며 각 단계의 레이어 수는 [ 6 , 6, 6, 6] (b)는 최적화된 비균일 분할 방법으로, 각 단계의 레이어 수는 [5, 5, 5, 5, 4]입니다. 중간 단계에는 흐르는 물이 채워지고, 고르지 않게 나누어진 거품은 더욱 낮아집니다.

따라야 할 경험 법칙은 다음과 같습니다. MoE 모델 교육의 FLOP가 Dense 모델 교육의 FLOP의 2배 이상이면 스크래치에서 MoE 교육을 선택하는 것이 더 좋습니다. MoE 교육을 위해 업사이클링을 선택하면 교육 비용을 크게 줄일 수 있습니다.
위 내용은 단일 4090 추론 가능, 2000억 희소 대형 모델 'Tiangong MoE'가 오픈 소스입니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

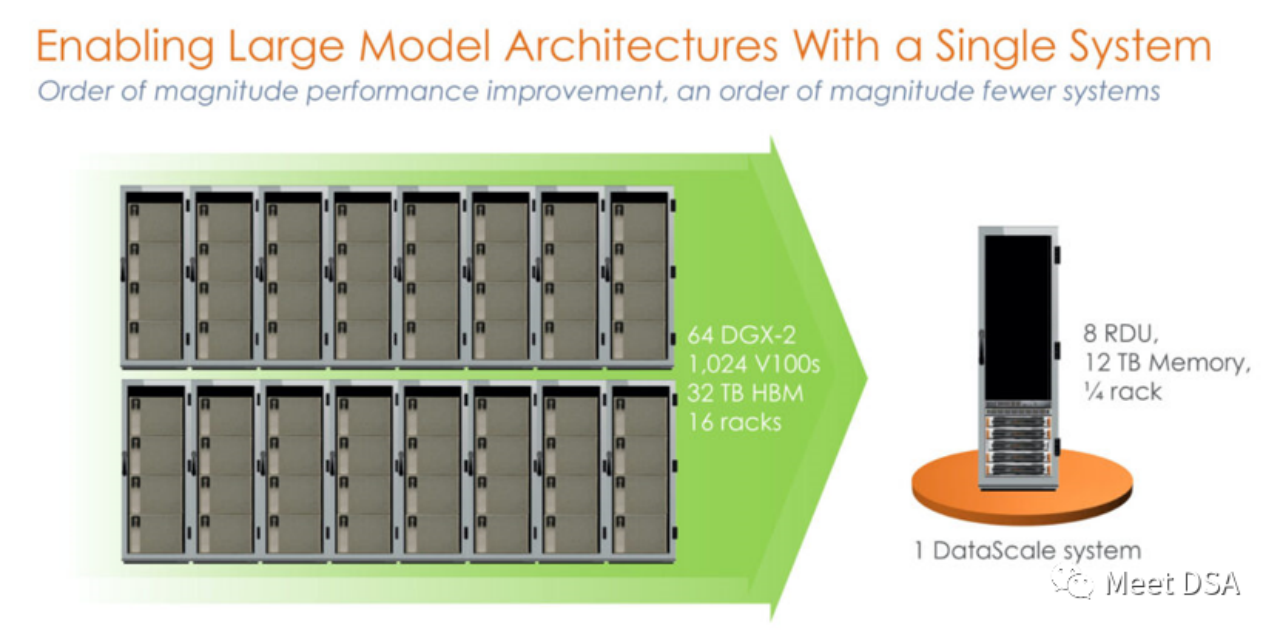 DSA如何弯道超车NVIDIA GPU?Sep 20, 2023 pm 06:09 PM
DSA如何弯道超车NVIDIA GPU?Sep 20, 2023 pm 06:09 PM你可能听过以下犀利的观点:1.跟着NVIDIA的技术路线,可能永远也追不上NVIDIA的脚步。2.DSA或许有机会追赶上NVIDIA,但目前的状况是DSA濒临消亡,看不到任何希望另一方面,我们都知道现在大模型正处于风口位置,业界很多人想做大模型芯片,也有很多人想投大模型芯片。但是,大模型芯片的设计关键在哪,大带宽大内存的重要性好像大家都知道,但做出来的芯片跟NVIDIA相比,又有何不同?带着问题,本文尝试给大家一点启发。纯粹以观点为主的文章往往显得形式主义,我们可以通过一个架构的例子来说明Sam
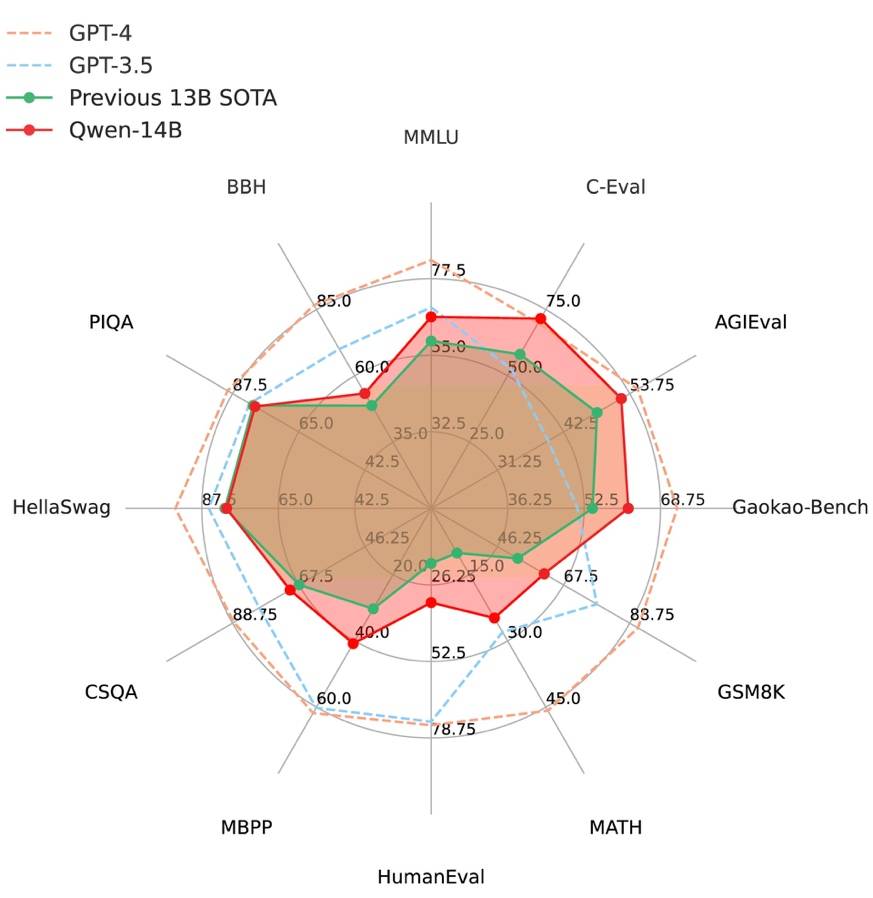 阿里云通义千问14B模型开源!性能超越Llama2等同等尺寸模型Sep 25, 2023 pm 10:25 PM
阿里云通义千问14B模型开源!性能超越Llama2等同等尺寸模型Sep 25, 2023 pm 10:25 PM2021年9月25日,阿里云发布了开源项目通义千问140亿参数模型Qwen-14B以及其对话模型Qwen-14B-Chat,并且可以免费商用。Qwen-14B在多个权威评测中表现出色,超过了同等规模的模型,甚至有些指标接近Llama2-70B。此前,阿里云还开源了70亿参数模型Qwen-7B,仅一个多月的时间下载量就突破了100万,成为开源社区的热门项目Qwen-14B是一款支持多种语言的高性能开源模型,相比同类模型使用了更多的高质量数据,整体训练数据超过3万亿Token,使得模型具备更强大的推
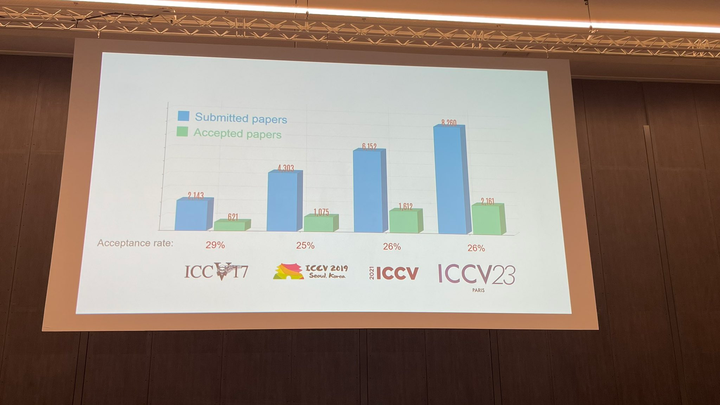 ICCV 2023揭晓:ControlNet、SAM等热门论文斩获奖项Oct 04, 2023 pm 09:37 PM
ICCV 2023揭晓:ControlNet、SAM等热门论文斩获奖项Oct 04, 2023 pm 09:37 PM在法国巴黎举行了国际计算机视觉大会ICCV(InternationalConferenceonComputerVision)本周开幕作为全球计算机视觉领域顶级的学术会议,ICCV每两年召开一次。ICCV的热度一直以来都与CVPR不相上下,屡创新高在今天的开幕式上,ICCV官方公布了今年的论文数据:本届ICCV共有8068篇投稿,其中有2160篇被接收,录用率为26.8%,略高于上一届ICCV2021的录用率25.9%在论文主题方面,官方也公布了相关数据:多视角和传感器的3D技术热度最高在今天的开
 复旦大学团队发布中文智慧法律系统DISC-LawLLM,构建司法评测基准,开源30万微调数据Sep 29, 2023 pm 01:17 PM
复旦大学团队发布中文智慧法律系统DISC-LawLLM,构建司法评测基准,开源30万微调数据Sep 29, 2023 pm 01:17 PM随着智慧司法的兴起,智能化方法驱动的智能法律系统有望惠及不同群体。例如,为法律专业人员减轻文书工作,为普通民众提供法律咨询服务,为法学学生提供学习和考试辅导。由于法律知识的独特性和司法任务的多样性,此前的智慧司法研究方面主要着眼于为特定任务设计自动化算法,难以满足对司法领域提供支撑性服务的需求,离应用落地有不小的距离。而大型语言模型(LLMs)在不同的传统任务上展示出强大的能力,为智能法律系统的进一步发展带来希望。近日,复旦大学数据智能与社会计算实验室(FudanDISC)发布大语言模型驱动的中
 百度文心一言全面向全社会开放,率先迈出重要一步Aug 31, 2023 pm 01:33 PM
百度文心一言全面向全社会开放,率先迈出重要一步Aug 31, 2023 pm 01:33 PM8月31日,文心一言首次向全社会全面开放。用户可以在应用商店下载“文心一言APP”或登录“文心一言官网”(https://yiyan.baidu.com)进行体验据报道,百度计划推出一系列经过全新重构的AI原生应用,以便让用户充分体验生成式AI的理解、生成、逻辑和记忆等四大核心能力今年3月16日,文心一言开启邀测。作为全球大厂中首个发布的生成式AI产品,文心一言的基础模型文心大模型早在2019年就在国内率先发布,近期升级的文心大模型3.5也持续在十余个国内外权威测评中位居第一。李彦宏表示,当文心
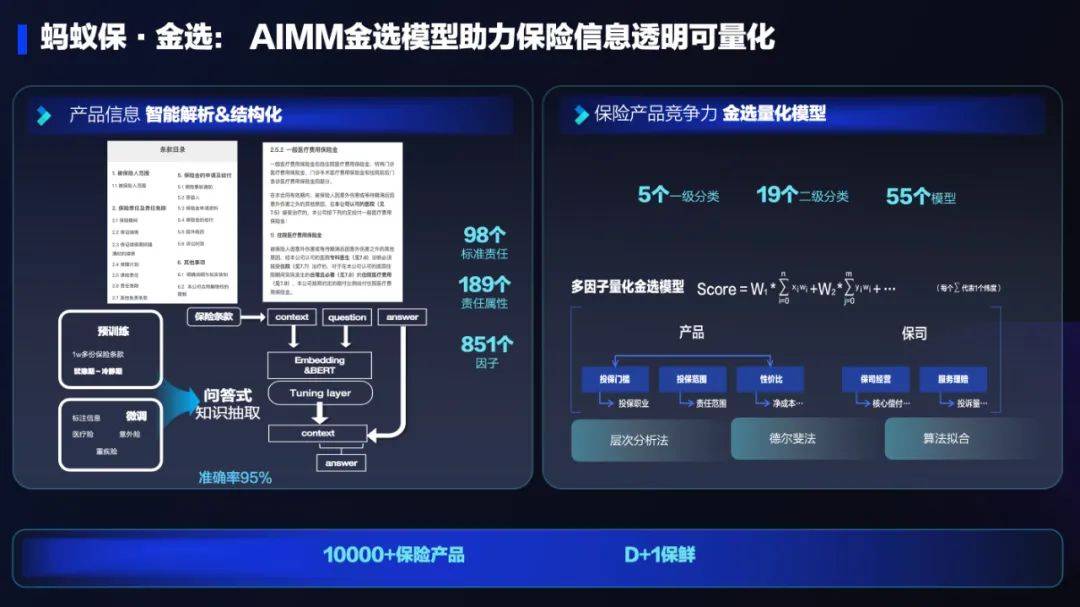 AI技术在蚂蚁集团保险业务中的应用:革新保险服务,带来全新体验Sep 20, 2023 pm 10:45 PM
AI技术在蚂蚁集团保险业务中的应用:革新保险服务,带来全新体验Sep 20, 2023 pm 10:45 PM保险行业对于社会民生和国民经济的重要性不言而喻。作为风险管理工具,保险为人民群众提供保障和福利,推动经济的稳定和可持续发展。在新的时代背景下,保险行业面临着新的机遇和挑战,需要不断创新和转型,以适应社会需求的变化和经济结构的调整近年来,中国的保险科技蓬勃发展。通过创新的商业模式和先进的技术手段,积极推动保险行业实现数字化和智能化转型。保险科技的目标是提升保险服务的便利性、个性化和智能化水平,以前所未有的速度改变传统保险业的面貌。这一发展趋势为保险行业注入了新的活力,使保险产品更贴近人民群众的实际
 致敬TempleOS,有开发者创建了启动Llama 2的操作系统,网友:8G内存老电脑就能跑Oct 07, 2023 pm 10:09 PM
致敬TempleOS,有开发者创建了启动Llama 2的操作系统,网友:8G内存老电脑就能跑Oct 07, 2023 pm 10:09 PM不得不说,Llama2的「二创」项目越来越硬核、有趣了。自Meta发布开源大模型Llama2以来,围绕着该模型的「二创」项目便多了起来。此前7月,特斯拉前AI总监、重回OpenAI的AndrejKarpathy利用周末时间,做了一个关于Llama2的有趣项目llama2.c,让用户在PyTorch中训练一个babyLlama2模型,然后使用近500行纯C、无任何依赖性的文件进行推理。今天,在Karpathyllama2.c项目的基础上,又有开发者创建了一个启动Llama2的演示操作系统,以及一个
 快手黑科技“子弹时间”赋能亚运转播,打造智慧观赛新体验Oct 11, 2023 am 11:21 AM
快手黑科技“子弹时间”赋能亚运转播,打造智慧观赛新体验Oct 11, 2023 am 11:21 AM杭州第19届亚运会不仅是国际顶级体育盛会,更是一场精彩绝伦的中国科技盛宴。本届亚运会中,快手StreamLake与杭州电信深度合作,联合打造智慧观赛新体验,在击剑赛事的转播中,全面应用了快手StreamLake六自由度技术,其中“子弹时间”也是首次应用于击剑项目国际顶级赛事。中国电信杭州分公司智能亚运专班组长芮杰表示,依托快手StreamLake自研的4K3D虚拟运镜视频技术和中国电信5G/全光网,通过赛场内部署的4K专业摄像机阵列实时采集的高清竞赛视频,


핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

드림위버 CS6
시각적 웹 개발 도구

맨티스BT
Mantis는 제품 결함 추적을 돕기 위해 설계된 배포하기 쉬운 웹 기반 결함 추적 도구입니다. PHP, MySQL 및 웹 서버가 필요합니다. 데모 및 호스팅 서비스를 확인해 보세요.

ZendStudio 13.5.1 맥
강력한 PHP 통합 개발 환경

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

DVWA
DVWA(Damn Vulnerable Web App)는 매우 취약한 PHP/MySQL 웹 애플리케이션입니다. 주요 목표는 보안 전문가가 법적 환경에서 자신의 기술과 도구를 테스트하고, 웹 개발자가 웹 응용 프로그램 보안 프로세스를 더 잘 이해할 수 있도록 돕고, 교사/학생이 교실 환경 웹 응용 프로그램에서 가르치고 배울 수 있도록 돕는 것입니다. 보안. DVWA의 목표는 다양한 난이도의 간단하고 간단한 인터페이스를 통해 가장 일반적인 웹 취약점 중 일부를 연습하는 것입니다. 이 소프트웨어는
뜨거운 주제
 1371
1371 523819
523819