
NVIDIA의 새로운 연구: 컨텍스트 길이가 심각하게 거짓이며 32K 성능이 검증된 경우가 많지 않습니다.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB원래의
- 2024-06-05 16:22:471209검색
"긴 컨텍스트" 대형 모델의 잘못된 표준 현상을 무자비하게 노출 -
NVIDIA의 새로운 연구에 따르면 GPT-4를 포함한 10개의 대형 모델이 128k 또는 심지어 1M의 컨텍스트 길이를 생성하는 것으로 나타났습니다.
그러나 몇 가지 테스트를 거친 후 새로운 지표인 "유효 컨텍스트"가 심각하게 줄어들었고 32K에 도달할 수 있는 사람은 많지 않습니다.
새로운 벤치마크는 RULER라고 하며, 여기에는 검색, 다중 홉 추적, 집계, 질문 및 답변 4개 범주의 총 13개 작업이 포함됩니다. RULER는 모델이 4K 길이에서 Llama-7B 기준과 동일한 성능을 유지할 수 있는 최대 길이인 "유효 컨텍스트 길이"를 정의합니다.

이 연구는 학계에서 "매우 통찰력이 있다"고 평가되었습니다.

이 새로운 연구를 본 많은 네티즌들도 문맥왕 클로드와 제미니의 도전 결과를 보고 싶어 했습니다. (논문에서는 다루지 않음)


NVIDIA가 "효과적인 컨텍스트" 지표를 어떻게 정의하는지 살펴보겠습니다.

테스트 과제가 점점 더 어려워지고 있습니다
대형 모델의 긴 텍스트 이해 능력을 평가하려면 먼저 ZeroSCROLLS, L-Eval, LongBench, InfiniteBench 등과 같은 좋은 표준을 선택해야 합니다. 서클에서 인기가 있거나 평가만 할 수도 있습니다. 모델 검색 능력은 사전 지식의 간섭으로 인해 제한됩니다.
그래서 NVIDIA가 제거한 RULER 방법은 “훈련 데이터에서 정보를 기억하는 능력보다는 긴 맥락을 처리하고 이해하는 모델의 능력에 평가가 초점을 맞추도록 하세요” 로 한 문장으로 요약할 수 있습니다.
RULER의 평가 데이터는 대형 모델이 훈련 과정에서 자체 매개변수로 인코딩한 지식인 '매개변수화된 지식'에 대한 의존도를 줄입니다.
특히 RULER 벤치마크는 4가지 새로운 작업 범주를 추가하여 인기 있는 "건초 더미 속의 바늘" 테스트를 확장합니다.
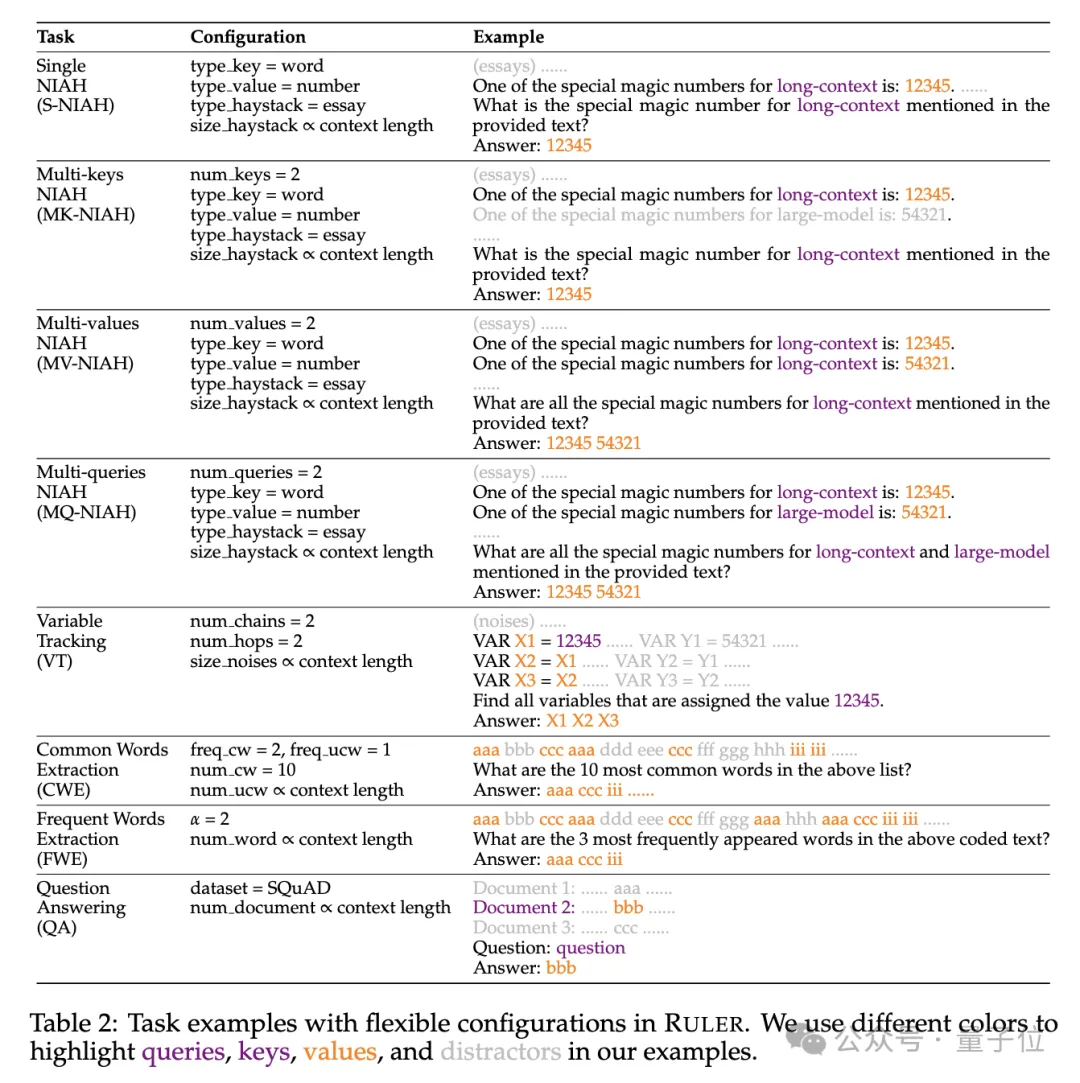
검색의 관점에서 건초 더미에서 바늘을 찾는 표준 단일 키 검색 작업을 시작으로 다음과 같은 새로운 유형이 추가되었습니다.
- 다중 키 검색 -keys NIAH, MK-NIAH): 다중 간섭 핀이 컨텍스트에 삽입되고 모델은 지정된 것을 검색해야 합니다
- 다중 값 검색(다중 값 NIAH, MV-NIAH ): 하나의 키(key)는 여러 값 (values)에 해당하며, 모델은 특정 키와 관련된 모든 값을 검색해야 합니다.
- 다중 쿼리 검색(다중 쿼리 NIAH, MQ-NIAH): 모델은 여러 쿼리를 기반으로 텍스트에서 해당 바늘을 여러 개 검색해야 합니다.
RULER에는 업그레이드된 검색 버전 외에도 Multi-hop Tracing(Multi-hop Tracing)챌린지가 추가되었습니다.
특히 연구원들은 상호 참조 해결의 최소 작업을 시뮬레이션하는변수 추적(VT)을 제안했습니다. 이는 모델이 텍스트에 있는 변수 할당 체인을 추적하도록 요구합니다. 비 연속적. 챌린지의 세 번째 레벨은 Aggregation
(Aggregation)입니다. 여기에는 다음이 포함됩니다.
Common Words Extraction- (CWE): 모델은 텍스트에서 가장 일반적인 단어를 추출해야 합니다. Frequent Words Extraction
- (Frequent Words Extraction, FWE): CWE와 유사하지만 단어의 빈도는 어휘 순위와 Zeta 분포 매개변수 α에 따라 결정됩니다.
챌린지의 네 번째 레벨은 Question and Answer Task (QA) 입니다. 기존 독해 데이터 세트 (예: SQuAD) 를 기반으로 긴 시퀀스 QA를 테스트하기 위해 많은 수의 간섭 문단이 삽입됩니다. 능력.
각 모델 컨텍스트의 실제 길이는 얼마나 되나요?
실험 단계에서 연구원들은 처음에 언급했듯이 GPT-4를 포함하여 긴 컨텍스트를 지원한다고 주장하는 10개의 언어 모델과 Command-R, Yi-34B, Mixtral(8x7B), Mixtral( 7B), ChatGLM, LWM, Together, LongChat, LongAlpaca.
이 모델 매개변수 크기의 범위는 MoE 아키텍처에서 6B~8x7B이고 최대 컨텍스트 길이 범위는 32K~1M입니다.
RULER 벤치마크 테스트에서 각 모델은 단순부터 복잡한 난이도에 이르는 4가지 작업 범주를 포함하는 13가지 작업에 대해 평가되었습니다. 각 작업에 대해 6개 레벨(4K, 8K, 16K, 32K, 64K, 128K)의 입력 길이가 4K에서 128K까지인 500개의 테스트 샘플이 생성됩니다.
 모델이 질문에 대한 답변을 거부하는 것을 방지하기 위해 입력에 답변 접두어가 추가되고 대상 출력의 존재 여부는 재현 기반 정확도를 기반으로 확인됩니다.
모델이 질문에 대한 답변을 거부하는 것을 방지하기 위해 입력에 답변 접두어가 추가되고 대상 출력의 존재 여부는 재현 기반 정확도를 기반으로 확인됩니다.
 연구원들은 또한 "유효 컨텍스트 길이" 측정 기준을 정의했습니다. 즉, 모델은 이 길이에서 4K 길이에서 기준선 Llama-7B와 동일한 성능 수준을 유지할 수 있습니다.
연구원들은 또한 "유효 컨텍스트 길이" 측정 기준을 정의했습니다. 즉, 모델은 이 길이에서 4K 길이에서 기준선 Llama-7B와 동일한 성능 수준을 유지할 수 있습니다.
더 자세한 모델 비교를 위해 가중 평균 점수
(Weighted Average, wAvg)는 다양한 길이에서 성능의 가중 평균을 수행하는 포괄적인 지표로 사용됩니다. 두 가지 가중치 체계가 채택됩니다.
wAvg(inc): 가중치는 길이에 따라 선형적으로 증가하며 긴 시퀀스가 지배하는 애플리케이션 시나리오를 시뮬레이션합니다.- wAvg(dec): 가중치는 길이에 따라 선형적으로 감소하며 주로 짧은 시퀀스 장면을 시뮬레이션합니다.
- 결과를 확인해보세요.
일반적인 건초 더미 속의 바늘 찾기 및 비밀번호 검색 테스트에서는 차이가 눈에 띄지 않으며 거의 모든 모델이 주장된 컨텍스트 길이 범위 내에서 만점을 달성했습니다.
RULER를 사용하면 많은 모델이 32K 토큰 이상의 컨텍스트를 처리할 수 있다고 주장하지만 Mixtral을 제외한 어떤 모델도 주장된 길이에서 Llama2-7B 기준을 초과하는 성능을 유지하지 않습니다.
 다른 결과는 다음과 같습니다. 전반적으로 GPT-4는 4K 길이에서 가장 좋은 성능을 발휘하며 컨텍스트를 128K로 확장할 때 성능 저하가 최소화됩니다
다른 결과는 다음과 같습니다. 전반적으로 GPT-4는 4K 길이에서 가장 좋은 성능을 발휘하며 컨텍스트를 128K로 확장할 때 성능 저하가 최소화됩니다
. 상위 3개 오픈 소스 모델은 Command-R, Yi-34B 및 Mixtral이며 모두 다른 모델보다 더 큰 기본 주파수 RoPE를 사용하고 더 많은 매개변수를 가지고 있습니다. ㅋㅋㅋ 작업 구성 및 실패 모드가 RULER에 미치는 영향.
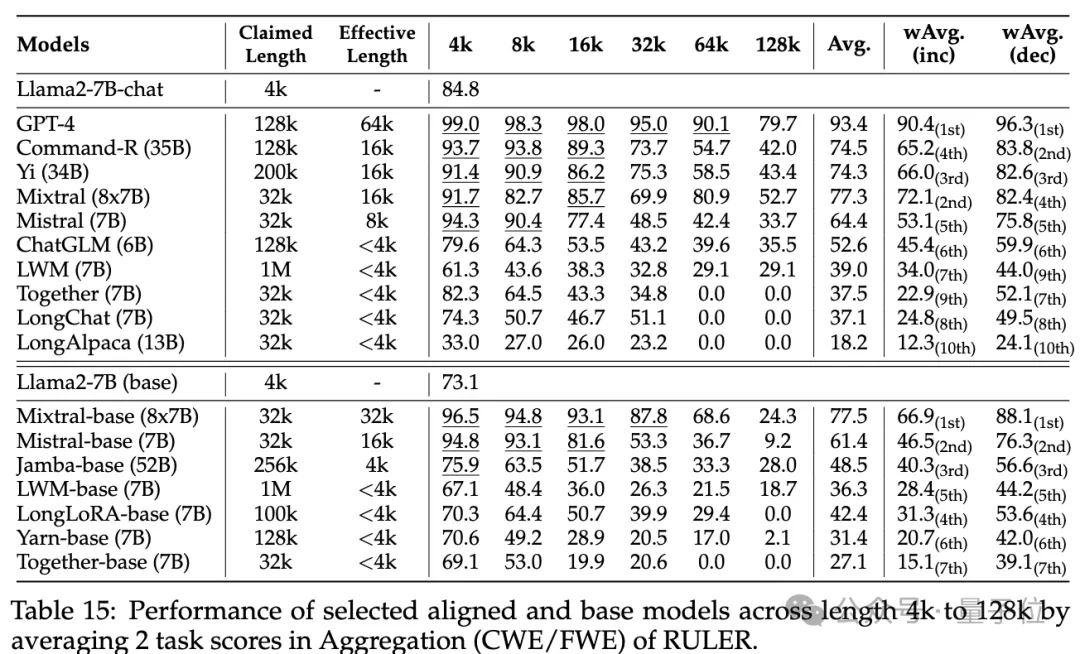
또한 훈련 컨텍스트 길이, 모델 크기 및 아키텍처가 모델 성능에 미치는 영향을 분석한 결과 일반적으로 더 큰
컨텍스트로 훈련하면 성능이 향상되지만 긴 시퀀스의 순위는 모델 크기가 커지면 일관되지 않을 수 있음을 발견했습니다. 긴 컨텍스트 모델링의 경우 Transformer가 아닌 아키텍처 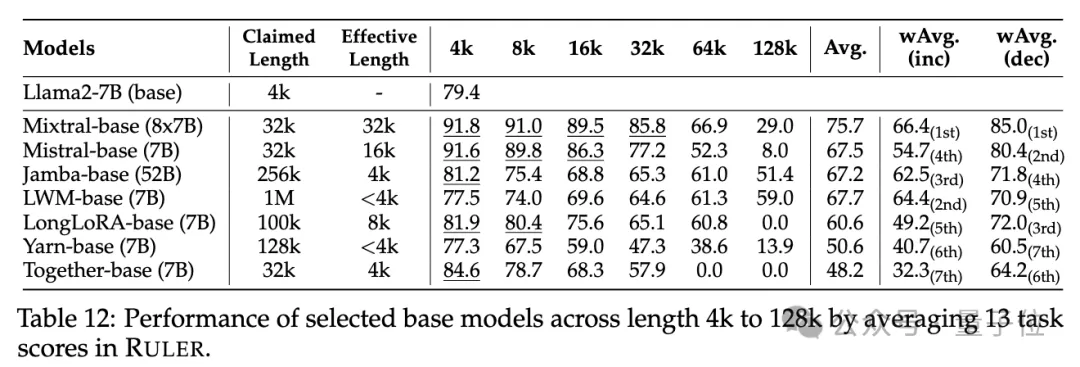 (예: RWKV 및 Mamba)
(예: RWKV 및 Mamba)
RULER의 Transformer 기반 Llama2-7B보다 상당히 뒤떨어집니다. 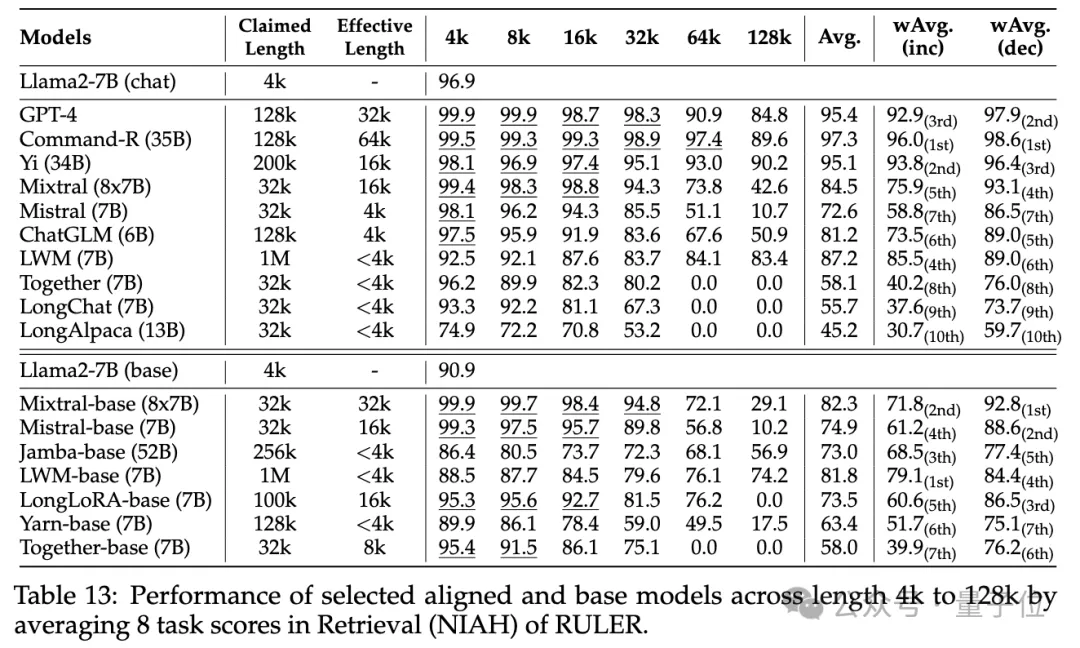
자세한 내용을 알아보려면 관심 있는 독자는 원본 논문을 확인하세요. 
 논문 링크: https://arxiv.org/abs/2404.06654
논문 링크: https://arxiv.org/abs/2404.06654
위 내용은 NVIDIA의 새로운 연구: 컨텍스트 길이가 심각하게 거짓이며 32K 성능이 검증된 경우가 많지 않습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!