
자바스크립트 배열 중복 제거_javascript 기술에 대한 세 가지 방법의 성능 테스트 및 비교

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB원래의
- 2016-05-16 17:39:131164검색
어제 참여한 프론트엔드 인터뷰에서 배열의 중복제거에 대한 질문이 있었는데, 가장 먼저 떠오른 것이 키값을 객체에 저장하는 방식이었습니다.
방법 1: (간단한 키 값 저장)
코드 복사 코드는 다음과 같습니다.
Array.prototype.distinct1 = function() {
var i=0 ,tmp={},that=this.slice(0)
this.length=0
for(;i< ;that.length;i ){
if(!(tmp의 that[i])){
this[this.length]=that[i]; true;
}
}
return this;
} ;
방법 2: (이중 루프)
코드 복사 코드는 다음과 같습니다.
Array.prototype.distinct2 = function () {
var i=0,flag,that=this.slice(0)
this.length=0
for(;ivar tmp=that[i];
플래그=true;
for(var j=0;jif(this[j]===tmp){flag= false;break}
}
if(flag)this[this.length]=tmp;
}
return this
}; 메소드는 원하는 결과를 얻었지만 2계층 루프 효율이 상대적으로 낮습니다. 첫 번째 메소드부터 시작하여 배열 항목의 유형을 저장하기 위해 문자열을 추가하는 방법을 찾아보겠습니다. 검색 시 저장된 유형의 문자열을 빈 문자열로 대체합니다.
방법 3 : (키 값 및 유형 저장)
var i=0,flag,that=this.slice(0)
this.length=0
for(;i
플래그=true;
for(var j=0;j
}
if(flag)this[this.length]=tmp;
}
return this
}; 메소드는 원하는 결과를 얻었지만 2계층 루프 효율이 상대적으로 낮습니다. 첫 번째 메소드부터 시작하여 배열 항목의 유형을 저장하기 위해 문자열을 추가하는 방법을 찾아보겠습니다. 검색 시 저장된 유형의 문자열을 빈 문자열로 대체합니다.
방법 3 : (키 값 및 유형 저장)
코드 복사
코드는 다음과 같습니다. Array .prototype.distinct4 = function() { var i=0,tmp={},t2,that=this.slice(0),one;
this.length=0 for(; ione=that[i];
t2=typeof one;
if(!(one in tmp)){
this[this.length]= one; ]=t2;
}else if(tmp[one].indexOf(t2)==-1){
this[this.length]=one
tmp [one] =t2; >}
}
return this;
}
다양한 데이터에 대한 다양한 알고리즘 간의 효율성 차이를 구별하기 위해 여러 가지 극단적인 예를 살펴보겠습니다. 1부터 80까지의 배열 항목이 모두 다르고 1000번 반복되는 상황에서는 글쎄요, IE6은 약합니다
IE9:
t2=typeof one;
if(!(one in tmp)){
this[this.length]= one; ]=t2;
}else if(tmp[one].indexOf(t2)==-1){
this[this.length]=one
tmp [one] =t2; >}
}
return this;
}
다양한 데이터에 대한 다양한 알고리즘 간의 효율성 차이를 구별하기 위해 여러 가지 극단적인 예를 살펴보겠습니다. 1부터 80까지의 배열 항목이 모두 다르고 1000번 반복되는 상황에서는 글쎄요, IE6은 약합니다
IE9:
Chrome: 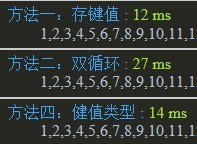 Firefox:
Firefox: IE6:
IE6: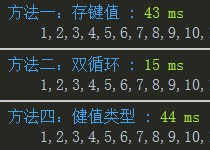 다음은 위 데이터를 기준으로 80개 항목이 모두 1000번 반복되는 상황입니다. IE6-8과 다른 브라우저의 이중 루프 성능은 좋지만 IE6-8의 이중 루프는 약 10~20배 정도 느려지는 것이 안타깝습니다. 귀하의 웹사이트가 IE9 이상만 지원한다면 이중 루프 방법을 사용해도 됩니다. 그렇지 않은 경우에는 데이터 상황에 따라 방법 1 또는 방법 3을 선택해야 합니다(그림의 방법 4, I). 사진을 바꾸기에는 너무 늦었다는 것을 알게 되었고, 원래 방법 3은 Array의 indexOf를 사용하는 것이었지만 느리고 호환되지 않아서 출시되지 않았습니다.)
다음은 위 데이터를 기준으로 80개 항목이 모두 1000번 반복되는 상황입니다. IE6-8과 다른 브라우저의 이중 루프 성능은 좋지만 IE6-8의 이중 루프는 약 10~20배 정도 느려지는 것이 안타깝습니다. 귀하의 웹사이트가 IE9 이상만 지원한다면 이중 루프 방법을 사용해도 됩니다. 그렇지 않은 경우에는 데이터 상황에 따라 방법 1 또는 방법 3을 선택해야 합니다(그림의 방법 4, I). 사진을 바꾸기에는 너무 늦었다는 것을 알게 되었고, 원래 방법 3은 Array의 indexOf를 사용하는 것이었지만 느리고 호환되지 않아서 출시되지 않았습니다.)
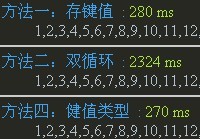
Chrome:
Firefox: IE6: 

성명:
본 글의 내용은 네티즌들의 자발적인 기여로 작성되었으며, 저작권은 원저작자에게 있습니다. 본 사이트는 이에 상응하는 법적 책임을 지지 않습니다. 표절이나 침해가 의심되는 콘텐츠를 발견한 경우 admin@php.cn으로 문의하세요.