


function getObject(objectId) {
if (document.getElementById && document.getElementById(objectId)) {
return document.getElementById(objectId);
} else if (document.all && document.all(objectId)) {
return document.all(objectId);
} else if (document.layers && document.layers[objectId]) {
return document.layers[objectId];
} else {
return false;
}
}
함수 get(p){
//var url=location.search;
var url= document.URL.toString();
var tmpStr=p "=";
var tmp_reg =eval("/[?&]" tmpStr "/i");
if(url.search(tmp_reg)==-1)return null;
else{
var a=url.split (/[?&]/);
for(var i=0;i
}
}
window.onload=function (){
getObject("key" ).value = get("k");
//키 입력 이름 이름, 接收到的值就是浏览器里的k参数
//k是浏览器里的参数name
}
以上代码放에서 html页face最下方即可

 PHP函数介绍—get_headers(): 获取URL的响应头信息Jul 25, 2023 am 09:05 AM
PHP函数介绍—get_headers(): 获取URL的响应头信息Jul 25, 2023 am 09:05 AMPHP函数介绍—get_headers():获取URL的响应头信息概述:在PHP开发中,我们经常需要获取网页或远程资源的响应头信息。PHP函数get_headers()能够方便地获取目标URL的响应头信息,并以数组形式返回。本文将介绍get_headers()函数的用法,以及提供一些相关的代码示例。get_headers()函数的用法:get_header
 怎样透过几个步骤获取您的 Steam ID?May 08, 2023 pm 11:43 PM
怎样透过几个步骤获取您的 Steam ID?May 08, 2023 pm 11:43 PM现在很多热爱游戏的windows用户都进入了Steam客户端,可以搜索、下载和玩任何好游戏。但是,许多用户的个人资料可能具有完全相同的名称,这使得查找个人资料或什至将Steam个人资料链接到其他第三方帐户或加入Steam论坛以共享内容变得困难。为配置文件分配了一个唯一的17位id,它保持不变,用户无法随时更改,而用户名或自定义URL可以更改。无论如何,一些用户并不知道他们的Steamid,这对于了解这一点非常重要。如果您也不知道如何找到您帐户的Steamid,请不要惊慌。在这篇文
 为什么NameResolutionError(self.host, self, e) from e,怎么解决Mar 01, 2024 pm 01:20 PM
为什么NameResolutionError(self.host, self, e) from e,怎么解决Mar 01, 2024 pm 01:20 PM报错的原因NameResolutionError(self.host,self,e)frome是由urllib3库中的异常类型,这个错误的原因是DNS解析失败,也就是说,试图解析的主机名或IP地址无法找到。这可能是由于输入的URL地址不正确,或者DNS服务器暂时不可用导致的。如何解决解决此错误的方法可能有以下几种:检查输入的URL地址是否正确,确保它是可访问的确保DNS服务器可用,您可以尝试在命令行中使用"ping"命令来测试DNS服务器是否可用尝试使用IP地址而不是主机名来访问网站如果是在代理
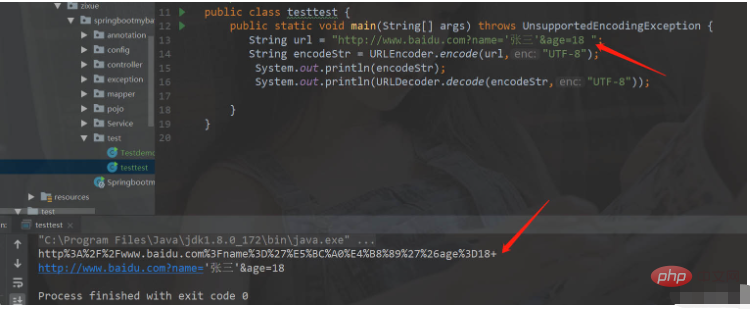 如何在Java中使用URL编码和解码May 08, 2023 pm 05:46 PM
如何在Java中使用URL编码和解码May 08, 2023 pm 05:46 PM使用url进行编码和解码编码和解码的类java.net.URLDecoder.decode(url,解码格式)解码器.解码方法。转化成普通字符串,URLEncoder.decode(url,编码格式)将普通字符串变成指定格式的字符串packagecom.zixue.springbootmybatis.test;importjava.io.UnsupportedEncodingException;importjava.net.URLDecoder;importjava.net.URLEncoder
 html和url的区别是什么Mar 06, 2024 pm 03:06 PM
html和url的区别是什么Mar 06, 2024 pm 03:06 PM区别:1、定义不同,url是是统一资源定位符,而html是超文本标记语言;2、一个html中可以有很多个url,而一个url中只能存在一个html页面;3、html指的是网页,而url指的是网站地址。
 SpringBoot多controller如何添加URL前缀May 12, 2023 pm 06:37 PM
SpringBoot多controller如何添加URL前缀May 12, 2023 pm 06:37 PM前言在某些情况下,服务的controller中前缀是一致的,例如所有URL的前缀都为/context-path/api/v1,需要为某些URL添加统一的前缀。能想到的处理办法为修改服务的context-path,在context-path中添加api/v1,这样修改全局的前缀能够解决上面的问题,但存在弊端,如果URL存在多个前缀,例如有些URL需要前缀为api/v2,就无法区分了,如果服务中的一些静态资源不想添加api/v1,也无法区分。下面通过自定义注解的方式实现某些URL前缀的统一添加。一、
 Scrapy优化技巧:如何减少重复URL的爬取,提高效率Jun 22, 2023 pm 01:57 PM
Scrapy优化技巧:如何减少重复URL的爬取,提高效率Jun 22, 2023 pm 01:57 PMScrapy是一个功能强大的Python爬虫框架,可以用于从互联网上获取大量的数据。但是,在进行Scrapy开发时,经常会遇到重复URL的爬取问题,这会浪费大量的时间和资源,影响效率。本文将介绍一些Scrapy优化技巧,以减少重复URL的爬取,提高Scrapy爬虫的效率。一、使用start_urls和allowed_domains属性在Scrapy爬虫中,可
 url是啥意思Aug 04, 2023 am 11:43 AM
url是啥意思Aug 04, 2023 am 11:43 AMurl是“Uniform Resource Locator”的缩写,中文意为“统一资源定位符”。URL是通过互联网来定位和访问特定资源的地址,常见于网页浏览和HTTP请求中。URL的主要作用是定位和访问互联网上的资源,这些资源可以是网页、图片、视频、文档或其他文件。


핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

에디트플러스 중국어 크랙 버전
작은 크기, 구문 강조, 코드 프롬프트 기능을 지원하지 않음

VSCode Windows 64비트 다운로드
Microsoft에서 출시한 강력한 무료 IDE 편집기

ZendStudio 13.5.1 맥
강력한 PHP 통합 개발 환경

맨티스BT
Mantis는 제품 결함 추적을 돕기 위해 설계된 배포하기 쉬운 웹 기반 결함 추적 도구입니다. PHP, MySQL 및 웹 서버가 필요합니다. 데모 및 호스팅 서비스를 확인해 보세요.

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

