


ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是第二流行的企业搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
我们建立一个网站或应用程序,并要添加搜索功能,令我们受打击的是:搜索工作是很难的。我们希望我们的搜索解决方案要快,我们希望有一个零配置和一个完全免费的搜索模式,我们希望能够简单地使用JSON通过HTTP的索引数据,我们希望我们的搜索服务器始终可用,我们希望能够一台开始并扩展到数百,我们要实时搜索,我们要简单的多租户,我们希望建立一个云的解决方案。Elasticsearch旨在解决所有这些问题和更多的问题。
Elasticsearch 是开源搜索平台的新成员,实时数据分析的神器,发展迅猛,基于 Lucene、RESTful、分布式、面向云计算设计、实时搜索、全文搜索、稳定、高可靠、可扩展、安装+使用方便,介绍都说的很好听,好不好用拿出来遛一遛。
做了个简单测试,在两台完全一样的虚拟机上,2000万条左右数据,Elasticsearch 插入数据速度比 MongoDB 慢很多(可以忍受),但是搜索/查询速度快10倍以上,这只是单机情况,多机集群情况下 Elasticsearch 表现更好一些。以下安装步骤在 Ubuntu Server 14.04 LTS 上完成。
安装 Elasticsearch
升级系统后安装 Oracle Java 7,既然 Elasticsearch 官方推荐使用 Oracle JDK 7 就不要尝试 JDK 8 和 OpenJDK 了:
$ sudo apt-get update $ sudo apt-get upgrade $ sudo apt-get install software-properties-common $ sudo add-apt-repository ppa:webupd8team/java $ sudo apt-get update $ sudo apt-get install oracle-java7-installer
加入 Elasticsearch 官方源后安装 elasticsearch:
$ wget -O - http://packages.elasticsearch.org/GPG-KEY-elasticsearch | apt-key add - $ sudo echo "deb http://packages.elasticsearch.org/elasticsearch/1.1/debian stable main" >> /etc/apt/sources.list $ sudo apt-get update $ sudo apt-get install elasticsearch
加入到系统启动文件并启动 elasticsearch 服务,用 curl 测试一下安装是否成功:
$ sudo update-rc.d elasticsearch defaults 95 1
$ sudo /etc/init.d/elasticsearch start
$ curl -X GET 'http://localhost:9200'
{
"status" : 200,
"name" : "Fer-de-Lance",
"version" : {
"number" : "1.1.1",
"build_hash" : "f1585f096d3f3985e73456debdc1a0745f512bbc",
"build_timestamp" : "2014-04-16T14:27:12Z",
"build_snapshot" : false,
"lucene_version" : "4.7"
},
"tagline" : "You Know, for Search"
}
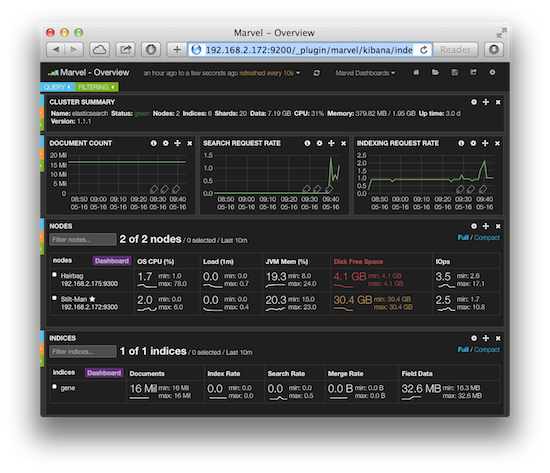
Elasticsearch 的集群和数据管理界面 Marvel 非常赞,可惜只对开发环境免费,如果这个工具也免费就无敌了,安装很简单,完成后重启服务访问 http://192.168.2.172:9200/_plugin/marvel/ 就可以看到界面:
$ sudo /usr/share/elasticsearch/bin/plugin -i elasticsearch/marvel/latest $ sudo /etc/init.d/elasticsearch restart * Stopping Elasticsearch Server [ OK ] * Starting Elasticsearch Server [ OK ]
安装 Python 客户端驱动
和 MongoDB 一样,我们一般用程序和 Elasticsearch 交互,Elasticsearch 也支持多种语言的客户端驱动,这里仅安装 Python 驱动,其他语言可以参考官方文档。
$ sudo apt-get install python-pip $ sudo pip install elasticsearch
写个简单程序把 gene_info.txt 的数据导入到 Elasticsearch:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import os, os.path, sys, re
import csv, time, string
from datetime import datetime
from elasticsearch import Elasticsearch
def import_to_db():
data = csv.reader(open('gene_info.txt', 'rb'), delimiter='\t')
data.next()
es = Elasticsearch()
for row in data:
doc = {
'tax_id': row[0],
'GeneID': row[1],
'Symbol': row[2],
'LocusTag': row[3],
'Synonyms': row[4],
'dbXrefs': row[5],
'chromosome': row[6],
'map_location': row[7],
'description': row[8],
'type_of_gene': row[9],
'Symbol_from_nomenclature_authority': row[10],
'Full_name_from_nomenclature_authority': row[11],
'Nomenclature_status': row[12],
'Other_designations': row[13],
'Modification_date': row[14]
}
res = es.index(index="gene", doc_type='gene_info', body=doc)
def main():
import_to_db()
if __name__ == "__main__":
main()
Kibana 是一个功能强大的数据显示客户端,通过插件方式和 Elasticsearch 集成在一起,安装很容易,下载解压就可以了,然后重启 Elasticsearch 服务访问 http://192.168.2.172:9200/_plugin/kibana/ 就能看到界面:
$ wget https://download.elasticsearch.org/kibana/kibana/kibana-3.0.1.tar.gz $ tar zxvf kibana-3.0.1.tar.gz $ sudo mv kibana-3.0.1 /usr/share/elasticsearch/plugins/_site $ sudo /etc/init.d/elasticsearch restart

 Python 학습 : 2 시간의 일일 연구가 충분합니까?Apr 18, 2025 am 12:22 AM
Python 학습 : 2 시간의 일일 연구가 충분합니까?Apr 18, 2025 am 12:22 AM하루에 2 시간 동안 파이썬을 배우는 것으로 충분합니까? 목표와 학습 방법에 따라 다릅니다. 1) 명확한 학습 계획을 개발, 2) 적절한 학습 자원 및 방법을 선택하고 3) 실습 연습 및 검토 및 통합 연습 및 검토 및 통합,이 기간 동안 Python의 기본 지식과 고급 기능을 점차적으로 마스터 할 수 있습니다.
 웹 개발을위한 파이썬 : 주요 응용 프로그램Apr 18, 2025 am 12:20 AM
웹 개발을위한 파이썬 : 주요 응용 프로그램Apr 18, 2025 am 12:20 AM웹 개발에서 Python의 주요 응용 프로그램에는 Django 및 Flask 프레임 워크 사용, API 개발, 데이터 분석 및 시각화, 머신 러닝 및 AI 및 성능 최적화가 포함됩니다. 1. Django 및 Flask 프레임 워크 : Django는 복잡한 응용 분야의 빠른 개발에 적합하며 플라스크는 소형 또는 고도로 맞춤형 프로젝트에 적합합니다. 2. API 개발 : Flask 또는 DjangorestFramework를 사용하여 RESTFULAPI를 구축하십시오. 3. 데이터 분석 및 시각화 : Python을 사용하여 데이터를 처리하고 웹 인터페이스를 통해 표시합니다. 4. 머신 러닝 및 AI : 파이썬은 지능형 웹 애플리케이션을 구축하는 데 사용됩니다. 5. 성능 최적화 : 비동기 프로그래밍, 캐싱 및 코드를 통해 최적화
 Python vs. C : 성능과 효율성 탐색Apr 18, 2025 am 12:20 AM
Python vs. C : 성능과 효율성 탐색Apr 18, 2025 am 12:20 AMPython은 개발 효율에서 C보다 낫지 만 C는 실행 성능이 높습니다. 1. Python의 간결한 구문 및 풍부한 라이브러리는 개발 효율성을 향상시킵니다. 2.C의 컴파일 유형 특성 및 하드웨어 제어는 실행 성능을 향상시킵니다. 선택할 때는 프로젝트 요구에 따라 개발 속도 및 실행 효율성을 평가해야합니다.
 Python in Action : 실제 예제Apr 18, 2025 am 12:18 AM
Python in Action : 실제 예제Apr 18, 2025 am 12:18 AMPython의 실제 응용 프로그램에는 데이터 분석, 웹 개발, 인공 지능 및 자동화가 포함됩니다. 1) 데이터 분석에서 Python은 Pandas 및 Matplotlib를 사용하여 데이터를 처리하고 시각화합니다. 2) 웹 개발에서 Django 및 Flask 프레임 워크는 웹 응용 프로그램 생성을 단순화합니다. 3) 인공 지능 분야에서 Tensorflow와 Pytorch는 모델을 구축하고 훈련시키는 데 사용됩니다. 4) 자동화 측면에서 파이썬 스크립트는 파일 복사와 같은 작업에 사용할 수 있습니다.
 Python의 주요 용도 : 포괄적 인 개요Apr 18, 2025 am 12:18 AM
Python의 주요 용도 : 포괄적 인 개요Apr 18, 2025 am 12:18 AMPython은 데이터 과학, 웹 개발 및 자동화 스크립팅 필드에 널리 사용됩니다. 1) 데이터 과학에서 Python은 Numpy 및 Pandas와 같은 라이브러리를 통해 데이터 처리 및 분석을 단순화합니다. 2) 웹 개발에서 Django 및 Flask 프레임 워크를 통해 개발자는 응용 프로그램을 신속하게 구축 할 수 있습니다. 3) 자동 스크립트에서 Python의 단순성과 표준 라이브러리가 이상적입니다.
 파이썬의 주요 목적 : 유연성과 사용 편의성Apr 17, 2025 am 12:14 AM
파이썬의 주요 목적 : 유연성과 사용 편의성Apr 17, 2025 am 12:14 AMPython의 유연성은 다중 파리가 지원 및 동적 유형 시스템에 반영되며, 사용 편의성은 간단한 구문 및 풍부한 표준 라이브러리에서 나옵니다. 유연성 : 객체 지향, 기능 및 절차 프로그래밍을 지원하며 동적 유형 시스템은 개발 효율성을 향상시킵니다. 2. 사용 편의성 : 문법은 자연 언어에 가깝고 표준 라이브러리는 광범위한 기능을 다루며 개발 프로세스를 단순화합니다.
 파이썬 : 다목적 프로그래밍의 힘Apr 17, 2025 am 12:09 AM
파이썬 : 다목적 프로그래밍의 힘Apr 17, 2025 am 12:09 AMPython은 초보자부터 고급 개발자에 이르기까지 모든 요구에 적합한 단순성과 힘에 호의적입니다. 다목적 성은 다음과 같이 반영됩니다. 1) 배우고 사용하기 쉽고 간단한 구문; 2) Numpy, Pandas 등과 같은 풍부한 라이브러리 및 프레임 워크; 3) 다양한 운영 체제에서 실행할 수있는 크로스 플랫폼 지원; 4) 작업 효율성을 향상시키기위한 스크립팅 및 자동화 작업에 적합합니다.
 하루 2 시간 안에 파이썬 학습 : 실용 가이드Apr 17, 2025 am 12:05 AM
하루 2 시간 안에 파이썬 학습 : 실용 가이드Apr 17, 2025 am 12:05 AM예, 하루에 2 시간 후에 파이썬을 배우십시오. 1. 합리적인 학습 계획 개발, 2. 올바른 학습 자원을 선택하십시오. 3. 실습을 통해 학습 된 지식을 통합하십시오. 이 단계는 짧은 시간 안에 Python을 마스터하는 데 도움이 될 수 있습니다.


핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

VSCode Windows 64비트 다운로드
Microsoft에서 출시한 강력한 무료 IDE 편집기

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

MinGW - Windows용 미니멀리스트 GNU
이 프로젝트는 osdn.net/projects/mingw로 마이그레이션되는 중입니다. 계속해서 그곳에서 우리를 팔로우할 수 있습니다. MinGW: GCC(GNU Compiler Collection)의 기본 Windows 포트로, 기본 Windows 애플리케이션을 구축하기 위한 무료 배포 가능 가져오기 라이브러리 및 헤더 파일로 C99 기능을 지원하는 MSVC 런타임에 대한 확장이 포함되어 있습니다. 모든 MinGW 소프트웨어는 64비트 Windows 플랫폼에서 실행될 수 있습니다.

WebStorm Mac 버전
유용한 JavaScript 개발 도구

SublimeText3 Linux 새 버전
SublimeText3 Linux 최신 버전

