


网络爬虫(Web Crawler, Spider)就是一个在网络上乱爬的机器人。当然它通常并不是一个实体的机器人,因为网络本身也是虚拟的东西,所以这个“机器人”其实也就是一段程序,并且它也不是乱爬,而是有一定目的的,并且在爬行的时候会搜集一些信息。例如 Google 就有一大堆爬虫会在 Internet 上搜集网页内容以及它们之间的链接等信息;又比如一些别有用心的爬虫会在 Internet 上搜集诸如 foo@bar.com 或者 foo [at] bar [dot] com 之类的东西。除此之外,还有一些定制的爬虫,专门针对某一个网站,例如前一阵子 JavaEye 的 Robbin 就写了几篇专门对付恶意爬虫的 blog (原文链接似乎已经失效了,就不给了),还有诸如小众软件或者 LinuxToy 这样的网站也经常被整个站点 crawl 下来,换个名字挂出来。其实爬虫从基本原理上来讲很简单,只要能访问网络和分析 Web 页面即可,现在大部分语言都有方便的 Http 客户端库可以抓取 Web 页面,而 HTML 的分析最简单的可以直接用正则表达式来做,因此要做一个最简陋的网络爬虫实际上是一件很简单的事情。不过要实现一个高质量的 spider 却是非常难的。
爬虫的两部分,一是下载 Web 页面,有许多问题需要考虑,如何最大程度地利用本地带宽,如何调度针对不同站点的 Web 请求以减轻对方服务器的负担等。一个高性能的 Web Crawler 系统里,DNS 查询也会成为急需优化的瓶颈,另外,还有一些“行规”需要遵循(例如 robots.txt)。而获取了网页之后的分析过程也是非常复杂的,Internet 上的东西千奇百怪,各种错误百出的 HTML 页面都有,要想全部分析清楚几乎是不可能的事;另外,随着 AJAX 的流行,如何获取由 Javascript 动态生成的内容成了一大难题;除此之外,Internet 上还有有各种有意或无意出现的 Spider Trap ,如果盲目的跟踪超链接的话,就会陷入 Trap 中万劫不复了,例如这个网站,据说是之前 Google 宣称 Internet 上的 Unique URL 数目已经达到了 1 trillion 个,因此这个人 is proud to announce the second trillion 。 :D
不过,其实并没有多少人需要做像 Google 那样通用的 Crawler ,通常我们做一个 Crawler 就是为了去爬特定的某个或者某一类网站,所谓知己知彼,百战不殆,我们可以事先对需要爬的网站结构做一些分析,事情就变得容易多了。通过分析,选出有价值的链接进行跟踪,就可以避免很多不必要的链接或者 Spider Trap ,如果网站的结构允许选择一个合适的路径的话,我们可以按照一定顺序把感兴趣的东西爬一遍,这样以来,连 URL 重复的判断也可以省去。
举个例子,假如我们想把 pongba 的 blog mindhacks.cn 里面的 blog 文字爬下来,通过观察,很容易发现我们对其中的两种页面感兴趣:
文章列表页面,例如首页,或者 URL 是 /page/\d+/ 这样的页面,通过 Firebug 可以看到到每篇文章的链接都是在一个 h1 下的 a 标签里的(需要注意的是,在 Firebug 的 HTML 面板里看到的 HTML 代码和 View Source 所看到的也许会有些出入,如果网页中有 Javascript 动态修改 DOM 树的话,前者是被修改过的版本,并且经过 Firebug 规则化的,例如 attribute 都有引号扩起来等,而后者通常才是你的 spider 爬到的原始内容。如果是使用正则表达式对页面进行分析或者所用的 HTML Parser 和 Firefox 的有些出入的话,需要特别注意),另外,在一个 class 为 wp-pagenavi 的 p 里有到不同列表页面的链接。
文章内容页面,每篇 blog 有这样一个页面,例如 /2008/09/11/machine-learning-and-ai-resources/ ,包含了完整的文章内容,这是我们感兴趣的内容。
因此,我们从首页开始,通过 wp-pagenavi 里的链接来得到其他的文章列表页面,特别地,我们定义一个路径:只 follow Next Page 的链接,这样就可以从头到尾按顺序走一遍,免去了需要判断重复抓取的烦恼。另外,文章列表页面的那些到具体文章的链接所对应的页面就是我们真正要保存的数据页面了。
这样以来,其实用脚本语言写一个 ad hoc 的 Crawler 来完成这个任务也并不难,不过今天的主角是 Scrapy ,这是一个用 Python 写的 Crawler Framework ,简单轻巧,并且非常方便,并且官网上说已经在实际生产中在使用了,因此并不是一个玩具级别的东西。不过现在还没有 Release 版本,可以直接使用他们的 Mercurial 仓库里抓取源码进行安装。不过,这个东西也可以不安装直接使用,这样还方便随时更新,文档里说得很详细,我就不重复了。
Scrapy 使用 Twisted 这个异步网络库来处理网络通讯,架构清晰,并且包含了各种中间件接口,可以灵活的完成各种需求。整体架构如下图所示:
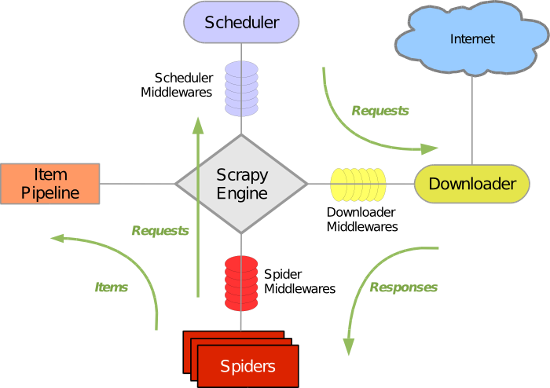
绿线是数据流向,首先从初始 URL 开始,Scheduler 会将其交给 Downloader 进行下载,下载之后会交给 Spider 进行分析,Spider 分析出来的结果有两种:一种是需要进一步抓取的链接,例如之前分析的“下一页”的链接,这些东西会被传回 Scheduler ;另一种是需要保存的数据,它们则被送到 Item Pipeline 那里,那是对数据进行后期处理(详细分析、过滤、存储等)的地方。另外,在数据流动的通道里还可以安装各种中间件,进行必要的处理。
具体的内容在最后的附属中还会介绍。
看起来好像很复杂,其实用起来很简单,就如同 Rails 一样,首先新建一个工程:
scrapy-admin.py startproject blog_crawl
会创建一个 blog_crawl 目录,里面有个 scrapy-ctl.py 是整个项目的控制脚本,而代码全都放在子目录 blog_crawl 里面。为了能抓取 mindhacks.cn ,我们在 spiders 目录里新建一个mindhacks_spider.py ,定义我们的 Spider 如下:
from scrapy.spider import BaseSpider
class MindhacksSpider(BaseSpider):
domain_name = "mindhacks.cn"
start_urls = ["http://mindhacks.cn/"]
def parse(self, response):
return []
SPIDER = MindhacksSpider()
我们的 MindhacksSpider 继承自 BaseSpider (通常直接继承自功能更丰富的 scrapy.contrib.spiders.CrawlSpider 要方便一些,不过为了展示数据是如何 parse 的,这里还是使用 BaseSpider 了),变量 domain_name 和 start_urls 都很容易明白是什么意思,而 parse 方法是我们需要定义的回调函数,默认的 request 得到 response 之后会调用这个回调函数,我们需要在这里对页面进行解析,返回两种结果(需要进一步 crawl 的链接和需要保存的数据),让我感觉有些奇怪的是,它的接口定义里这两种结果竟然是混杂在一个 list 里返回的,不太清楚这里为何这样设计,难道最后不还是要费力把它们分开?总之这里我们先写一个空函数,只返回一个空列表。另外,定义一个“全局”变量 SPIDER ,它会在 Scrapy 导入这个 module 的时候实例化,并自动被 Scrapy 的引擎找到。这样就可以先运行一下 crawler 试试了:
./scrapy-ctl.py crawl mindhacks.cn
会有一堆输出,可以看到抓取了 http://mindhacks.cn ,因为这是初始 URL ,但是由于我们在 parse 函数里没有返回需要进一步抓取的 URL ,因此整个 crawl 过程只抓取了主页便结束了。接下来便是要对页面进行分析,Scrapy 提供了一个很方便的 Shell (需要 IPython )可以让我们做实验,用如下命令启动 Shell :
./scrapy-ctl.py shell http://mindhacks.cn
它会启动 crawler ,把命令行指定的这个页面抓取下来,然后进入 shell ,根据提示,我们有许多现成的变量可以用,其中一个就是 hxs ,它是一个 HtmlXPathSelector ,mindhacks 的 HTML 页面比较规范,可以很方便的直接用 XPath 进行分析。通过 Firebug 可以看到,到每篇 blog 文章的链接都是在 h1 下的,因此在 Shell 中使用这样的 XPath 表达式测试:
In [1]: hxs.x('//h1/a/@href').extract() Out[1]: [u'http://mindhacks.cn/2009/07/06/why-you-should-do-it-yourself/', u'http://mindhacks.cn/2009/05/17/seven-years-in-nju/', u'http://mindhacks.cn/2009/03/28/effective-learning-and-memorization/', u'http://mindhacks.cn/2009/03/15/preconception-explained/', u'http://mindhacks.cn/2009/03/09/first-principles-of-programming/', u'http://mindhacks.cn/2009/02/15/why-you-should-start-blogging-now/', u'http://mindhacks.cn/2009/02/09/writing-is-better-thinking/', u'http://mindhacks.cn/2009/02/07/better-explained-conflicts-in-intimate-relationship/', u'http://mindhacks.cn/2009/02/07/independence-day/', u'http://mindhacks.cn/2009/01/18/escape-from-your-shawshank-part1/']
这正是我们需要的 URL ,另外,还可以找到“下一页”的链接所在,连同其他几个页面的链接一同在一个 p 里,不过“下一页”的链接没有 title 属性,因此 XPath 写作
//p[@class="wp-pagenavi"]/a[not(@title)]
不过如果向后翻一页的话,会发现其实“上一页”也是这样的,因此还需要判断该链接上的文字是那个下一页的箭头 u'\xbb' ,本来也可以写到 XPath 里面去,但是好像这个本身是 unicode escape 字符,由于编码原因理不清楚,直接放到外面判断了,最终 parse 函数如下:
def parse(self, response):
items = []
hxs = HtmlXPathSelector(response)
posts = hxs.x('//h1/a/@href').extract()
items.extend([self.make_requests_from_url(url).replace(callback=self.parse_post)
for url in posts])
page_links = hxs.x('//p[@class="wp-pagenavi"]/a[not(@title)]')
for link in page_links:
if link.x('text()').extract()[0] == u'\xbb':
url = link.x('@href').extract()[0]
items.append(self.make_requests_from_url(url))
return items
前半部分是解析需要抓取的 blog 正文的链接,后半部分则是给出“下一页”的链接。需要注意的是,这里返回的列表里并不是一个个的字符串格式的 URL 就完了,Scrapy 希望得到的是 Request 对象,这比一个字符串格式的 URL 能携带更多的东西,诸如 Cookie 或者回调函数之类的。可以看到我们在创建 blog 正文的 Request 的时候替换掉了回调函数,因为默认的这个回调函数 parse 是专门用来解析文章列表这样的页面的,而 parse_post 定义如下:
def parse_post(self, response): item = BlogCrawlItem() item.url = unicode(response.url) item.raw = response.body_as_unicode() return [item]
很简单,返回一个 BlogCrawlItem ,把抓到的数据放在里面,本来可以在这里做一点解析,例如,通过 XPath 把正文和标题等解析出来,但是我倾向于后面再来做这些事情,例如 Item Pipeline 或者更后面的 Offline 阶段。BlogCrawlItem 是 Scrapy 自动帮我们定义好的一个继承自 ScrapedItem 的空类,在 items.py 中,这里我加了一点东西:
from scrapy.item import ScrapedItem
class BlogCrawlItem(ScrapedItem):
def __init__(self):
ScrapedItem.__init__(self)
self.url = ''
def __str__(self):
return 'BlogCrawlItem(url: %s)' % self.url
定义了 __str__ 函数,只给出 URL ,因为默认的 __str__ 函数会把所有的数据都显示出来,因此会看到 crawl 的时候控制台 log 狂输出东西,那是把抓取到的网页内容输出出来了。-.-bb
这样一来,数据就取到了,最后只剩下存储数据的功能,我们通过添加一个 Pipeline 来实现,由于 Python 在标准库里自带了 Sqlite3 的支持,所以我使用 Sqlite 数据库来存储数据。用如下代码替换 pipelines.py 的内容:
import sqlite3
from os import path
from scrapy.core import signals
from scrapy.xlib.pydispatch import dispatcher
class SQLiteStorePipeline(object):
filename = 'data.sqlite'
def __init__(self):
self.conn = None
dispatcher.connect(self.initialize, signals.engine_started)
dispatcher.connect(self.finalize, signals.engine_stopped)
def process_item(self, domain, item):
self.conn.execute('insert into blog values(?,?,?)',
(item.url, item.raw, unicode(domain)))
return item
def initialize(self):
if path.exists(self.filename):
self.conn = sqlite3.connect(self.filename)
else:
self.conn = self.create_table(self.filename)
def finalize(self):
if self.conn is not None:
self.conn.commit()
self.conn.close()
self.conn = None
def create_table(self, filename):
conn = sqlite3.connect(filename)
conn.execute("""create table blog
(url text primary key, raw text, domain text)""")
conn.commit()
return conn
在 __init__ 函数中,使用 dispatcher 将两个信号连接到指定的函数上,分别用于初始化和关闭数据库连接(在 close 之前记得 commit ,似乎是不会自动 commit 的,直接 close 的话好像所有的数据都丢失了 dd-.-)。当有数据经过 pipeline 的时候,process_item 函数会被调用,在这里我们直接讲原始数据存储到数据库中,不作任何处理。如果需要的话,可以添加额外的 pipeline ,对数据进行提取、过滤等,这里就不细说了。
最后,在 settings.py 里列出我们的 pipeline :
ITEM_PIPELINES = ['blog_crawl.pipelines.SQLiteStorePipeline']
再跑一下 crawler ,就 OK 啦!
PS1:Scrapy的组件
1.Scrapy Engine(Scrapy引擎)
Scrapy引擎是用来控制整个系统的数据处理流程,并进行事务处理的触发。更多的详细内容可以看下面的数据处理流程。
2.Scheduler(调度程序)
调度程序从Scrapy引擎接受请求并排序列入队列,并在Scrapy引擎发出请求后返还给它们。
3.Downloader(下载器)
下载器的主要职责是抓取网页并将网页内容返还给蜘蛛(Spiders)。
4.Spiders(蜘蛛)
蜘蛛是有Scrapy用户自己定义用来解析网页并抓取制定URL返回的内容的类,每个蜘蛛都能处理一个域名或一组域名。换句话说就是用来定义特定网站的抓取和解析规则。
5.Item Pipeline(项目管道)
项目管道的主要责任是负责处理有蜘蛛从网页中抽取的项目,它的主要任务是清晰、验证和存储数据。当页面被蜘蛛解析后,将被发送到项目管道,并经过几个特定的次序处理数据。每个项目管道的组件都是有一个简单的方法组成的Python类。它们获取了项目并执行它们的方法,同时还需要确定的是是否需要在项目管道中继续执行下一步或是直接丢弃掉不处理。
项目管道通常执行的过程有:
清洗HTML数据 验证解析到的数据(检查项目是否包含必要的字段) 检查是否是重复数据(如果重复就删除) 将解析到的数据存储到数据库中
6.Middlewares(中间件)
中间件是介于Scrapy引擎和其他组件之间的一个钩子框架,主要是为了提供一个自定义的代码来拓展Scrapy的功能。
PS2:Scrapy的数据处理流程
Scrapy的整个数据处理流程有Scrapy引擎进行控制,其主要的运行方式为:
引擎打开一个域名,时蜘蛛处理这个域名,并让蜘蛛获取第一个爬取的URL。
引擎从蜘蛛那获取第一个需要爬取的URL,然后作为请求在调度中进行调度。
引擎从调度那获取接下来进行爬取的页面。
调度将下一个爬取的URL返回给引擎,引擎将它们通过下载中间件发送到下载器。
当网页被下载器下载完成以后,响应内容通过下载中间件被发送到引擎。
引擎收到下载器的响应并将它通过蜘蛛中间件发送到蜘蛛进行处理。
蜘蛛处理响应并返回爬取到的项目,然后给引擎发送新的请求。
引擎将抓取到的项目项目管道,并向调度发送请求。
系统重复第二部后面的操作,直到调度中没有请求,然后断开引擎与域之间的联系。
以上就是深入剖析Python的爬虫框架Scrapy的结构与运作流程的内容,更多相关内容请关注PHP中文网(www.php.cn)!

 Python vs. C : 응용 및 사용 사례가 비교되었습니다Apr 12, 2025 am 12:01 AM
Python vs. C : 응용 및 사용 사례가 비교되었습니다Apr 12, 2025 am 12:01 AMPython은 데이터 과학, 웹 개발 및 자동화 작업에 적합한 반면 C는 시스템 프로그래밍, 게임 개발 및 임베디드 시스템에 적합합니다. Python은 단순성과 강력한 생태계로 유명하며 C는 고성능 및 기본 제어 기능으로 유명합니다.
 2 시간의 파이썬 계획 : 현실적인 접근Apr 11, 2025 am 12:04 AM
2 시간의 파이썬 계획 : 현실적인 접근Apr 11, 2025 am 12:04 AM2 시간 이내에 Python의 기본 프로그래밍 개념과 기술을 배울 수 있습니다. 1. 변수 및 데이터 유형을 배우기, 2. 마스터 제어 흐름 (조건부 명세서 및 루프), 3. 기능의 정의 및 사용을 이해하십시오. 4. 간단한 예제 및 코드 스 니펫을 통해 Python 프로그래밍을 신속하게 시작하십시오.
 파이썬 : 기본 응용 프로그램 탐색Apr 10, 2025 am 09:41 AM
파이썬 : 기본 응용 프로그램 탐색Apr 10, 2025 am 09:41 AMPython은 웹 개발, 데이터 과학, 기계 학습, 자동화 및 스크립팅 분야에서 널리 사용됩니다. 1) 웹 개발에서 Django 및 Flask 프레임 워크는 개발 프로세스를 단순화합니다. 2) 데이터 과학 및 기계 학습 분야에서 Numpy, Pandas, Scikit-Learn 및 Tensorflow 라이브러리는 강력한 지원을 제공합니다. 3) 자동화 및 스크립팅 측면에서 Python은 자동화 된 테스트 및 시스템 관리와 같은 작업에 적합합니다.
 2 시간 안에 얼마나 많은 파이썬을 배울 수 있습니까?Apr 09, 2025 pm 04:33 PM
2 시간 안에 얼마나 많은 파이썬을 배울 수 있습니까?Apr 09, 2025 pm 04:33 PM2 시간 이내에 파이썬의 기본 사항을 배울 수 있습니다. 1. 변수 및 데이터 유형을 배우십시오. 이를 통해 간단한 파이썬 프로그램 작성을 시작하는 데 도움이됩니다.
 10 시간 이내에 프로젝트 및 문제 중심 방법에서 컴퓨터 초보자 프로그래밍 기본 사항을 가르치는 방법?Apr 02, 2025 am 07:18 AM
10 시간 이내에 프로젝트 및 문제 중심 방법에서 컴퓨터 초보자 프로그래밍 기본 사항을 가르치는 방법?Apr 02, 2025 am 07:18 AM10 시간 이내에 컴퓨터 초보자 프로그래밍 기본 사항을 가르치는 방법은 무엇입니까? 컴퓨터 초보자에게 프로그래밍 지식을 가르치는 데 10 시간 밖에 걸리지 않는다면 무엇을 가르치기로 선택 하시겠습니까?
 중간 독서를 위해 Fiddler를 사용할 때 브라우저에서 감지되는 것을 피하는 방법은 무엇입니까?Apr 02, 2025 am 07:15 AM
중간 독서를 위해 Fiddler를 사용할 때 브라우저에서 감지되는 것을 피하는 방법은 무엇입니까?Apr 02, 2025 am 07:15 AMFiddlerevery Where를 사용할 때 Man-in-the-Middle Reading에 Fiddlereverywhere를 사용할 때 감지되는 방법 ...
 Python 3.6에 피클 파일을로드 할 때 '__builtin__'모듈을 찾을 수없는 경우 어떻게해야합니까?Apr 02, 2025 am 07:12 AM
Python 3.6에 피클 파일을로드 할 때 '__builtin__'모듈을 찾을 수없는 경우 어떻게해야합니까?Apr 02, 2025 am 07:12 AMPython 3.6에 피클 파일로드 3.6 환경 보고서 오류 : modulenotfounderror : nomodulename ...
 경치 좋은 스팟 코멘트 분석에서 Jieba Word 세분화의 정확성을 향상시키는 방법은 무엇입니까?Apr 02, 2025 am 07:09 AM
경치 좋은 스팟 코멘트 분석에서 Jieba Word 세분화의 정확성을 향상시키는 방법은 무엇입니까?Apr 02, 2025 am 07:09 AM경치 좋은 스팟 댓글 분석에서 Jieba Word 세분화 문제를 해결하는 방법은 무엇입니까? 경치가 좋은 스팟 댓글 및 분석을 수행 할 때 종종 Jieba Word 세분화 도구를 사용하여 텍스트를 처리합니다 ...


핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

Atom Editor Mac 버전 다운로드
가장 인기 있는 오픈 소스 편집기

SecList
SecLists는 최고의 보안 테스터의 동반자입니다. 보안 평가 시 자주 사용되는 다양한 유형의 목록을 한 곳에 모아 놓은 것입니다. SecLists는 보안 테스터에게 필요할 수 있는 모든 목록을 편리하게 제공하여 보안 테스트를 더욱 효율적이고 생산적으로 만드는 데 도움이 됩니다. 목록 유형에는 사용자 이름, 비밀번호, URL, 퍼징 페이로드, 민감한 데이터 패턴, 웹 셸 등이 포함됩니다. 테스터는 이 저장소를 새로운 테스트 시스템으로 간단히 가져올 수 있으며 필요한 모든 유형의 목록에 액세스할 수 있습니다.

DVWA
DVWA(Damn Vulnerable Web App)는 매우 취약한 PHP/MySQL 웹 애플리케이션입니다. 주요 목표는 보안 전문가가 법적 환경에서 자신의 기술과 도구를 테스트하고, 웹 개발자가 웹 응용 프로그램 보안 프로세스를 더 잘 이해할 수 있도록 돕고, 교사/학생이 교실 환경 웹 응용 프로그램에서 가르치고 배울 수 있도록 돕는 것입니다. 보안. DVWA의 목표는 다양한 난이도의 간단하고 간단한 인터페이스를 통해 가장 일반적인 웹 취약점 중 일부를 연습하는 것입니다. 이 소프트웨어는

SublimeText3 Linux 새 버전
SublimeText3 Linux 최신 버전

에디트플러스 중국어 크랙 버전
작은 크기, 구문 강조, 코드 프롬프트 기능을 지원하지 않음

