


之前一篇文章我们学习了爬虫的异常处理问题,那么接下来我们一起来看一下Cookie的使用。
为什么要使用Cookie呢?
Cookie,指某些网站为了辨别用户身份、进行session跟踪而储存在用户本地终端上的数据(通常经过加密)
比如说有些网站需要登录后才能访问某个页面,在登录之前,你想抓取某个页面内容是不允许的。那么我们可以利用Urllib2库保存我们登录的Cookie,然后再抓取其他页面就达到目的了。
在此之前呢,我们必须先介绍一个opener的概念。
1.Opener
当你获取一个URL你使用一个opener(一个urllib2.OpenerDirector的实例)。在前面,我们都是使用的默认的opener,也就是urlopen。它是一个特殊的opener,可以理解成opener的一个特殊实例,传入的参数仅仅是url,data,timeout。
如果我们需要用到Cookie,只用这个opener是不能达到目的的,所以我们需要创建更一般的opener来实现对Cookie的设置。
2.Cookielib
cookielib模块的主要作用是提供可存储cookie的对象,以便于与urllib2模块配合使用来访问Internet资源。Cookielib模块非常强大,我们可以利用本模块的CookieJar类的对象来捕获cookie并在后续连接请求时重新发送,比如可以实现模拟登录功能。该模块主要的对象有CookieJar、FileCookieJar、MozillaCookieJar、LWPCookieJar。
它们的关系:CookieJar —-派生—->FileCookieJar —-派生—–>MozillaCookieJar和LWPCookieJar
1)获取Cookie保存到变量
首先,我们先利用CookieJar对象实现获取cookie的功能,存储到变量中,先来感受一下
import urllib2
import cookielib
#声明一个CookieJar对象实例来保存cookie
cookie = cookielib.CookieJar()
#利用urllib2库的HTTPCookieProcessor对象来创建cookie处理器
handler=urllib2.HTTPCookieProcessor(cookie)
#通过handler来构建opener
opener = urllib2.build_opener(handler)
#此处的open方法同urllib2的urlopen方法,也可以传入request
response = opener.open('http://www.baidu.com')
for item in cookie:
print 'Name = '+item.name
print 'Value = '+item.value
我们使用以上方法将cookie保存到变量中,然后打印出了cookie中的值,运行结果如下
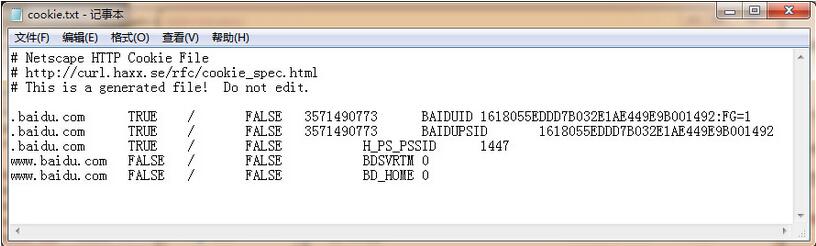
Name = BAIDUID Value = B07B663B645729F11F659C02AAE65B4C:FG=1 Name = BAIDUPSID Value = B07B663B645729F11F659C02AAE65B4C Name = H_PS_PSSID Value = 12527_11076_1438_10633 Name = BDSVRTM Value = 0 Name = BD_HOME Value = 0
2)保存Cookie到文件
在上面的方法中,我们将cookie保存到了cookie这个变量中,如果我们想将cookie保存到文件中该怎么做呢?这时,我们就要用到
FileCookieJar这个对象了,在这里我们使用它的子类MozillaCookieJar来实现Cookie的保存
import cookielib
import urllib2
#设置保存cookie的文件,同级目录下的cookie.txt
filename = 'cookie.txt'
#声明一个MozillaCookieJar对象实例来保存cookie,之后写入文件
cookie = cookielib.MozillaCookieJar(filename)
#利用urllib2库的HTTPCookieProcessor对象来创建cookie处理器
handler = urllib2.HTTPCookieProcessor(cookie)
#通过handler来构建opener
opener = urllib2.build_opener(handler)
#创建一个请求,原理同urllib2的urlopen
response = opener.open("http://www.baidu.com")
#保存cookie到文件
cookie.save(ignore_discard=True, ignore_expires=True)
关于最后save方法的两个参数在此说明一下:
官方解释如下:
ignore_discard: save even cookies set to be discarded.
ignore_expires: save even cookies that have expiredThe file is overwritten if it already exists
由此可见,ignore_discard的意思是即使cookies将被丢弃也将它保存下来,ignore_expires的意思是如果在该文件中cookies已经存在,则覆盖原文件写入,在这里,我们将这两个全部设置为True。运行之后,cookies将被保存到cookie.txt文件中,我们查看一下内容,附图如下
3)从文件中获取Cookie并访问
那么我们已经做到把Cookie保存到文件中了,如果以后想使用,可以利用下面的方法来读取cookie并访问网站,感受一下
import cookielib
import urllib2
#创建MozillaCookieJar实例对象
cookie = cookielib.MozillaCookieJar()
#从文件中读取cookie内容到变量
cookie.load('cookie.txt', ignore_discard=True, ignore_expires=True)
#创建请求的request
req = urllib2.Request("http://www.baidu.com")
#利用urllib2的build_opener方法创建一个opener
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie))
response = opener.open(req)
print response.read()
设想,如果我们的 cookie.txt 文件中保存的是某个人登录百度的cookie,那么我们提取出这个cookie文件内容,就可以用以上方法模拟这个人的账号登录百度。
4)利用cookie模拟网站登录
下面我们以我们学校的教育系统为例,利用cookie实现模拟登录,并将cookie信息保存到文本文件中,来感受一下cookie大法吧!
注意:密码我改了啊,别偷偷登录本宫的选课系统 o(╯□╰)o
import urllib
import urllib2
import cookielib
filename = 'cookie.txt'
#声明一个MozillaCookieJar对象实例来保存cookie,之后写入文件
cookie = cookielib.MozillaCookieJar(filename)
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie))
postdata = urllib.urlencode({
'stuid':'201200131012',
'pwd':'23342321'
})
#登录教务系统的URL
loginUrl = 'http://jwxt.sdu.edu.cn:7890/pls/wwwbks/bks_login2.login'
#模拟登录,并把cookie保存到变量
result = opener.open(loginUrl,postdata)
#保存cookie到cookie.txt中
cookie.save(ignore_discard=True, ignore_expires=True)
#利用cookie请求访问另一个网址,此网址是成绩查询网址
gradeUrl = 'http://jwxt.sdu.edu.cn:7890/pls/wwwbks/bkscjcx.curscopre'
#请求访问成绩查询网址
result = opener.open(gradeUrl)
print result.read()
以上程序的原理如下
创建一个带有cookie的opener,在访问登录的URL时,将登录后的cookie保存下来,然后利用这个cookie来访问其他网址。
如登录之后才能查看的成绩查询呀,本学期课表呀等等网址,模拟登录就这么实现啦,是不是很酷炫?
好,小伙伴们要加油哦!我们现在可以顺利获取网站信息了,接下来就是把网站里面有效内容提取出来,下一篇文章我们去会会正则表达式!

 Python vs. C : 주요 차이점 이해Apr 21, 2025 am 12:18 AM
Python vs. C : 주요 차이점 이해Apr 21, 2025 am 12:18 AMPython과 C는 각각 고유 한 장점이 있으며 선택은 프로젝트 요구 사항을 기반으로해야합니다. 1) Python은 간결한 구문 및 동적 타이핑으로 인해 빠른 개발 및 데이터 처리에 적합합니다. 2) C는 정적 타이핑 및 수동 메모리 관리로 인해 고성능 및 시스템 프로그래밍에 적합합니다.
 Python vs. C : 프로젝트를 위해 어떤 언어를 선택해야합니까?Apr 21, 2025 am 12:17 AM
Python vs. C : 프로젝트를 위해 어떤 언어를 선택해야합니까?Apr 21, 2025 am 12:17 AMPython 또는 C를 선택하는 것은 프로젝트 요구 사항에 따라 다릅니다. 1) 빠른 개발, 데이터 처리 및 프로토 타입 설계가 필요한 경우 Python을 선택하십시오. 2) 고성능, 낮은 대기 시간 및 근접 하드웨어 제어가 필요한 경우 C를 선택하십시오.
 파이썬 목표에 도달 : 매일 2 시간의 힘Apr 20, 2025 am 12:21 AM
파이썬 목표에 도달 : 매일 2 시간의 힘Apr 20, 2025 am 12:21 AM매일 2 시간의 파이썬 학습을 투자하면 프로그래밍 기술을 효과적으로 향상시킬 수 있습니다. 1. 새로운 지식 배우기 : 문서를 읽거나 자습서를 시청하십시오. 2. 연습 : 코드를 작성하고 완전한 연습을합니다. 3. 검토 : 배운 내용을 통합하십시오. 4. 프로젝트 실무 : 실제 프로젝트에서 배운 것을 적용하십시오. 이러한 구조화 된 학습 계획은 파이썬을 체계적으로 마스터하고 경력 목표를 달성하는 데 도움이 될 수 있습니다.
 2 시간 극대화 : 효과적인 파이썬 학습 전략Apr 20, 2025 am 12:20 AM
2 시간 극대화 : 효과적인 파이썬 학습 전략Apr 20, 2025 am 12:20 AM2 시간 이내에 Python을 효율적으로 학습하는 방법 : 1. 기본 지식을 검토하고 Python 설치 및 기본 구문에 익숙한 지 확인하십시오. 2. 변수, 목록, 기능 등과 같은 파이썬의 핵심 개념을 이해합니다. 3. 예제를 사용하여 마스터 기본 및 고급 사용; 4. 일반적인 오류 및 디버깅 기술을 배우십시오. 5. 목록 이해력 사용 및 PEP8 스타일 안내서와 같은 성능 최적화 및 모범 사례를 적용합니다.
 Python과 C : The Hight Language 중에서 선택Apr 20, 2025 am 12:20 AM
Python과 C : The Hight Language 중에서 선택Apr 20, 2025 am 12:20 AMPython은 초보자 및 데이터 과학에 적합하며 C는 시스템 프로그래밍 및 게임 개발에 적합합니다. 1. 파이썬은 간단하고 사용하기 쉽고 데이터 과학 및 웹 개발에 적합합니다. 2.C는 게임 개발 및 시스템 프로그래밍에 적합한 고성능 및 제어를 제공합니다. 선택은 프로젝트 요구와 개인적인 이익을 기반으로해야합니다.
 Python vs. C : 프로그래밍 언어의 비교 분석Apr 20, 2025 am 12:14 AM
Python vs. C : 프로그래밍 언어의 비교 분석Apr 20, 2025 am 12:14 AMPython은 데이터 과학 및 빠른 개발에 더 적합한 반면 C는 고성능 및 시스템 프로그래밍에 더 적합합니다. 1. Python Syntax는 간결하고 학습하기 쉽고 데이터 처리 및 과학 컴퓨팅에 적합합니다. 2.C는 복잡한 구문을 가지고 있지만 성능이 뛰어나고 게임 개발 및 시스템 프로그래밍에 종종 사용됩니다.
 하루 2 시간 : 파이썬 학습의 잠재력Apr 20, 2025 am 12:14 AM
하루 2 시간 : 파이썬 학습의 잠재력Apr 20, 2025 am 12:14 AM파이썬을 배우기 위해 하루에 2 시간을 투자하는 것이 가능합니다. 1. 새로운 지식 배우기 : 목록 및 사전과 같은 1 시간 안에 새로운 개념을 배우십시오. 2. 연습 및 연습 : 1 시간을 사용하여 소규모 프로그램 작성과 같은 프로그래밍 연습을 수행하십시오. 합리적인 계획과 인내를 통해 짧은 시간에 Python의 핵심 개념을 마스터 할 수 있습니다.
 Python vs. C : 학습 곡선 및 사용 편의성Apr 19, 2025 am 12:20 AM
Python vs. C : 학습 곡선 및 사용 편의성Apr 19, 2025 am 12:20 AMPython은 배우고 사용하기 쉽고 C는 더 강력하지만 복잡합니다. 1. Python Syntax는 간결하며 초보자에게 적합합니다. 동적 타이핑 및 자동 메모리 관리를 사용하면 사용하기 쉽지만 런타임 오류가 발생할 수 있습니다. 2.C는 고성능 응용 프로그램에 적합한 저수준 제어 및 고급 기능을 제공하지만 학습 임계 값이 높고 수동 메모리 및 유형 안전 관리가 필요합니다.


핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

DVWA
DVWA(Damn Vulnerable Web App)는 매우 취약한 PHP/MySQL 웹 애플리케이션입니다. 주요 목표는 보안 전문가가 법적 환경에서 자신의 기술과 도구를 테스트하고, 웹 개발자가 웹 응용 프로그램 보안 프로세스를 더 잘 이해할 수 있도록 돕고, 교사/학생이 교실 환경 웹 응용 프로그램에서 가르치고 배울 수 있도록 돕는 것입니다. 보안. DVWA의 목표는 다양한 난이도의 간단하고 간단한 인터페이스를 통해 가장 일반적인 웹 취약점 중 일부를 연습하는 것입니다. 이 소프트웨어는

mPDF
mPDF는 UTF-8로 인코딩된 HTML에서 PDF 파일을 생성할 수 있는 PHP 라이브러리입니다. 원저자인 Ian Back은 자신의 웹 사이트에서 "즉시" PDF 파일을 출력하고 다양한 언어를 처리하기 위해 mPDF를 작성했습니다. HTML2FPDF와 같은 원본 스크립트보다 유니코드 글꼴을 사용할 때 속도가 느리고 더 큰 파일을 생성하지만 CSS 스타일 등을 지원하고 많은 개선 사항이 있습니다. RTL(아랍어, 히브리어), CJK(중국어, 일본어, 한국어)를 포함한 거의 모든 언어를 지원합니다. 중첩된 블록 수준 요소(예: P, DIV)를 지원합니다.

SublimeText3 영어 버전
권장 사항: Win 버전, 코드 프롬프트 지원!

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

